Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
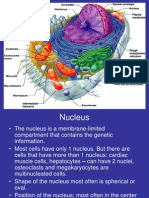
- NucleusDokument58 SeitenNucleusImperiall100% (1)
- ERYTHROPOEISISDokument28 SeitenERYTHROPOEISISnirilibNoch keine Bewertungen
- IB HL BIO FULL NOTES (Onarıldı)Dokument874 SeitenIB HL BIO FULL NOTES (Onarıldı)Sıla DenizNoch keine Bewertungen
- Chinese Herbs and Herbal Medicine Essential Components, Clinical Applications and Health Benefits (Public Health in The 21st Century) 1st Edition 2015 (PRG)Dokument193 SeitenChinese Herbs and Herbal Medicine Essential Components, Clinical Applications and Health Benefits (Public Health in The 21st Century) 1st Edition 2015 (PRG)hanalarasNoch keine Bewertungen
- Updated Zoology 2017Dokument21 SeitenUpdated Zoology 2017Pradeep RathaNoch keine Bewertungen
- Ap - Transpiration LabDokument1 SeiteAp - Transpiration Labapi-251015600Noch keine Bewertungen
- Ap - Diffusion Osmosis Lab Report RubricDokument1 SeiteAp - Diffusion Osmosis Lab Report Rubricapi-251015600Noch keine Bewertungen
- Ap - Blast Lab RevisedDokument1 SeiteAp - Blast Lab Revisedapi-251015600Noch keine Bewertungen
- Ap - Bacterial Transformation Virtual Lab ModifiedDokument1 SeiteAp - Bacterial Transformation Virtual Lab Modifiedapi-251015600Noch keine Bewertungen
- Ap - Photosynthesis Lab Report RubricDokument1 SeiteAp - Photosynthesis Lab Report Rubricapi-251015600Noch keine Bewertungen
- Ap - Gel Electrophoresis Virtual Lab ModifiedDokument1 SeiteAp - Gel Electrophoresis Virtual Lab Modifiedapi-251015600Noch keine Bewertungen
- Ap - Gel Electrophoresis Post Lab QuestionsDokument1 SeiteAp - Gel Electrophoresis Post Lab Questionsapi-251015600Noch keine Bewertungen
- Ap - Enzyme Lab Report RubricDokument1 SeiteAp - Enzyme Lab Report Rubricapi-251015600Noch keine Bewertungen
- Ap PollutionprojectDokument1 SeiteAp Pollutionprojectapi-251015600Noch keine Bewertungen
- Ap AcivilactionDokument2 SeitenAp Acivilactionapi-251015600Noch keine Bewertungen
- Ap - SyllabusDokument8 SeitenAp - Syllabusapi-251015600100% (1)
- Ap - Enzyme LabDokument1 SeiteAp - Enzyme Labapi-251015600Noch keine Bewertungen
- Ap - EcologyDokument52 SeitenAp - Ecologyapi-251015600Noch keine Bewertungen
- Ap ErinbrockovichDokument3 SeitenAp Erinbrockovichapi-251015600Noch keine Bewertungen
- Ap - Hardy-Weinberg LabDokument1 SeiteAp - Hardy-Weinberg Labapi-251015600Noch keine Bewertungen
- Ap - HeredityDokument58 SeitenAp - Heredityapi-251015600Noch keine Bewertungen
- Ap - Hardy-Weinberg Lab Report RubricDokument2 SeitenAp - Hardy-Weinberg Lab Report Rubricapi-251015600Noch keine Bewertungen
- SPP ExpectationsagreementDokument4 SeitenSPP Expectationsagreementapi-251015600Noch keine Bewertungen
- Ap - Diversity of Life & PlantsDokument40 SeitenAp - Diversity of Life & Plantsapi-251015600Noch keine Bewertungen
- Ap - EvolutionDokument54 SeitenAp - Evolutionapi-251015600Noch keine Bewertungen
- Ap - Cell Division - MeiosisDokument24 SeitenAp - Cell Division - Meiosisapi-251015600Noch keine Bewertungen
- Ap - Heredity Corn Lab Report RubricDokument1 SeiteAp - Heredity Corn Lab Report Rubricapi-251015600Noch keine Bewertungen
- Ap - Heredity Corn LabDokument1 SeiteAp - Heredity Corn Labapi-251015600Noch keine Bewertungen
- Ap - Cellular Energetics - PhotosynthesisDokument20 SeitenAp - Cellular Energetics - Photosynthesisapi-251015600Noch keine Bewertungen
- Ap - Unit 01 Chemistry of Life Study GuideDokument2 SeitenAp - Unit 01 Chemistry of Life Study Guideapi-251015600Noch keine Bewertungen
- Ap - Cell Division - MitosisDokument16 SeitenAp - Cell Division - Mitosisapi-251015600Noch keine Bewertungen
- Ap - Cellular Energetics - Cell RespirationDokument22 SeitenAp - Cellular Energetics - Cell Respirationapi-251015600100% (1)
- SPP FinalexamDokument1 SeiteSPP Finalexamapi-251015600Noch keine Bewertungen
- Ap - Photosynthesis LabDokument1 SeiteAp - Photosynthesis Labapi-251015600Noch keine Bewertungen
- Cell Theory PowerpresDokument16 SeitenCell Theory PowerpresGehan FaroukNoch keine Bewertungen
- Prokaryotic Vs Eukaryotic CellsDokument55 SeitenProkaryotic Vs Eukaryotic CellsRufaro SadindiNoch keine Bewertungen
- Biochem Check For UnderstandingDokument5 SeitenBiochem Check For UnderstandingMaria Vannesa Anne SalvacionNoch keine Bewertungen
- Resveratrol Role in Autoimmune Disease-A Mini-Review: Nutrients December 2017Dokument23 SeitenResveratrol Role in Autoimmune Disease-A Mini-Review: Nutrients December 2017Melati SatriasNoch keine Bewertungen
- A Peek Inside A CellDokument2 SeitenA Peek Inside A CellJohn Carl Angelo EstrellaNoch keine Bewertungen
- Sowdambikaa Group of Schools: Bio - Botany I. Choose The Best Answer: (5x1 5)Dokument2 SeitenSowdambikaa Group of Schools: Bio - Botany I. Choose The Best Answer: (5x1 5)fireNoch keine Bewertungen
- Botany Prelims Chapters 1 To 7 PointersDokument3 SeitenBotany Prelims Chapters 1 To 7 PointersCristine LalunaNoch keine Bewertungen
- Silver (I) Complexes Containing Diclofenac and Niflumic Acid Induce Apoptosis in Human-Derived Cancer Cell LinesDokument12 SeitenSilver (I) Complexes Containing Diclofenac and Niflumic Acid Induce Apoptosis in Human-Derived Cancer Cell LinesRapazito RagazzoNoch keine Bewertungen
- Activation of TLR7:8 Sperm Sexing PDFDokument24 SeitenActivation of TLR7:8 Sperm Sexing PDFmeltwithsnow163.comNoch keine Bewertungen
- The Integrative Biology of Type 2 DiabetesDokument10 SeitenThe Integrative Biology of Type 2 DiabetesAdrian GhiţăNoch keine Bewertungen
- Pathophysiology of Type 1 DiabetesDokument14 SeitenPathophysiology of Type 1 DiabetesBoNoch keine Bewertungen
- NSTSE Sample Paper Class 9Dokument4 SeitenNSTSE Sample Paper Class 9Jleodennis RajNoch keine Bewertungen
- Agascalm Brossúra01Dokument21 SeitenAgascalm Brossúra01vukicsvikiNoch keine Bewertungen
- Midterm Performance Task 1Dokument3 SeitenMidterm Performance Task 1Mary Grace E. CerioNoch keine Bewertungen
- Syntrophic TheoryDokument14 SeitenSyntrophic TheoryPam LandayanNoch keine Bewertungen
- Aqa Byb2 W MS Jun06Dokument5 SeitenAqa Byb2 W MS Jun06iluvmcr88Noch keine Bewertungen
- Plant Cell:: Ultra Structure and Functions of Typical Plant and Animal CellDokument8 SeitenPlant Cell:: Ultra Structure and Functions of Typical Plant and Animal CellMaleehaNoch keine Bewertungen
- Chapter 18 - Regulation of Gene ExpressionDokument37 SeitenChapter 18 - Regulation of Gene ExpressionSelestine Salema100% (1)
- 8 Carbohydrate Metabolism PDFDokument36 Seiten8 Carbohydrate Metabolism PDFDayne Ocampo-SolimanNoch keine Bewertungen
- TranscriptionDokument72 SeitenTranscriptionMurthy MandalikaNoch keine Bewertungen
- Photosynthesis: Rafia Urooj Saman 2020-Ag-937Dokument18 SeitenPhotosynthesis: Rafia Urooj Saman 2020-Ag-937Rafya ShabbirNoch keine Bewertungen
- CELLDokument45 SeitenCELLKimberly Clarisse VegaNoch keine Bewertungen
- Chapter 7 - NeoplasiaDokument23 SeitenChapter 7 - NeoplasiaAgnieszka WisniewskaNoch keine Bewertungen
- Code ZOOL Course DetailsDokument33 SeitenCode ZOOL Course DetailssaqikhanNoch keine Bewertungen
- PlantDerived Edible Nanoparticles and MiRNAs Emerging Frontier For Therapeutics and Targeted DrugDeliveryDokument15 SeitenPlantDerived Edible Nanoparticles and MiRNAs Emerging Frontier For Therapeutics and Targeted DrugDeliveryS. MartinezNoch keine Bewertungen