Das könnte Ihnen auch gefallen
- Pie Chart For The ProjectDokument7 SeitenPie Chart For The Projectapi-325968264Noch keine Bewertungen
- Skittles Term ProjectDokument10 SeitenSkittles Term Projectapi-273060240Noch keine Bewertungen
- Skittles Project Math 1040Dokument8 SeitenSkittles Project Math 1040api-495044194Noch keine Bewertungen
- SkittlesDokument7 SeitenSkittlesapi-244615173Noch keine Bewertungen
- Skittles ProjectDokument4 SeitenSkittles Projectapi-287735026Noch keine Bewertungen
- Skittles Term Project 1-6Dokument10 SeitenSkittles Term Project 1-6api-284733808Noch keine Bewertungen
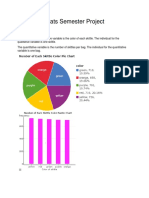
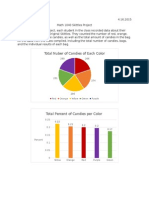
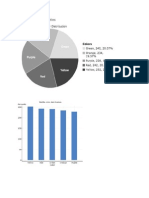
- Stats Semester ProjectDokument11 SeitenStats Semester Projectapi-276989071Noch keine Bewertungen
- Skittles Project 1Dokument7 SeitenSkittles Project 1api-299868669100% (2)
- Full Skittles ProjectDokument13 SeitenFull Skittles Projectapi-537189505Noch keine Bewertungen
- Kassem Hajj: Math 1040 Skittles Term ProjectDokument10 SeitenKassem Hajj: Math 1040 Skittles Term Projectapi-240347922Noch keine Bewertungen
- Skittles ProjectDokument9 SeitenSkittles Projectapi-252747849Noch keine Bewertungen
- Emily Gregorio Skittles Project FinalDokument3 SeitenEmily Gregorio Skittles Project Finalapi-288933258Noch keine Bewertungen
- Skittles Project 2-6Dokument8 SeitenSkittles Project 2-6api-302525501Noch keine Bewertungen
- Skittles Project Part 5Dokument16 SeitenSkittles Project Part 5api-246855746Noch keine Bewertungen
- Skittles Project FinalDokument5 SeitenSkittles Project Finalapi-271348941Noch keine Bewertungen
- Skittles ProDokument9 SeitenSkittles Proapi-241124972Noch keine Bewertungen
- Statistics Final Project Summer Semester 2016Dokument17 SeitenStatistics Final Project Summer Semester 2016api-295161880Noch keine Bewertungen
- Skittles Term Project Final PaperDokument15 SeitenSkittles Term Project Final Paperapi-339884559Noch keine Bewertungen
- Skittles ReportDokument15 SeitenSkittles Reportapi-271901299Noch keine Bewertungen
- Statistics Project 17Dokument13 SeitenStatistics Project 17api-271978152Noch keine Bewertungen
- Final ProjectDokument9 SeitenFinal Projectapi-262329757Noch keine Bewertungen
- Skittles 2 FinalDokument12 SeitenSkittles 2 Finalapi-242194552Noch keine Bewertungen
- Math 1030 Skittles Term ProjectDokument8 SeitenMath 1030 Skittles Term Projectapi-340538273Noch keine Bewertungen
- Math 1040 Skittles Project Worksheet-2 1Dokument6 SeitenMath 1040 Skittles Project Worksheet-2 1api-316476731Noch keine Bewertungen
- Kiera Tech Experience 2Dokument5 SeitenKiera Tech Experience 2api-275431904Noch keine Bewertungen
- Skittles Project 2Dokument10 SeitenSkittles Project 2api-316655135Noch keine Bewertungen
- Math 1040 Skittles Term ProjectDokument10 SeitenMath 1040 Skittles Term Projectapi-310671451Noch keine Bewertungen
- Reflection and EportfolioDokument8 SeitenReflection and Eportfolioapi-252747849Noch keine Bewertungen
- Skittles Eportfolio TestDokument14 SeitenSkittles Eportfolio Testapi-385819431100% (1)
- Skittles Project Math 1030Dokument9 SeitenSkittles Project Math 1030api-305867098Noch keine Bewertungen
- The Skittles ProjectDokument5 SeitenThe Skittles Projectapi-495363385Noch keine Bewertungen
- Skittles Term Project - Kai Galbiso Stat1040Dokument6 SeitenSkittles Term Project - Kai Galbiso Stat1040api-316758771Noch keine Bewertungen
- 1040 Skittles ProjectDokument4 Seiten1040 Skittles Projectapi-279941094Noch keine Bewertungen
- Skittles Project Final Cut Leon LindDokument13 SeitenSkittles Project Final Cut Leon Lindapi-283465839Noch keine Bewertungen
- Comprehensive Skittles Project Math 1040Dokument7 SeitenComprehensive Skittles Project Math 1040api-316732019Noch keine Bewertungen
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Dokument8 SeitenTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832Noch keine Bewertungen
- Skittles ProjectDokument6 SeitenSkittles Projectapi-495018964Noch keine Bewertungen
- SkittlesdataclassprojectDokument8 SeitenSkittlesdataclassprojectapi-399586872Noch keine Bewertungen
- Skittles Project Stats 1040Dokument8 SeitenSkittles Project Stats 1040api-301336765Noch keine Bewertungen
- Skittles ProjectDokument9 SeitenSkittles Projectapi-242873849Noch keine Bewertungen
- Math 1040 Skittles Term ProjectDokument9 SeitenMath 1040 Skittles Term Projectapi-319881085Noch keine Bewertungen
- The Rainbow ReportDokument11 SeitenThe Rainbow Reportapi-316991888Noch keine Bewertungen
- Skittles Project - My Page VersionDokument22 SeitenSkittles Project - My Page Versionapi-272829351Noch keine Bewertungen
- Skittles ProjectDokument5 SeitenSkittles Projectapi-441660843Noch keine Bewertungen
- Math 1040 Statistics Term Project: Blake FreemanDokument10 SeitenMath 1040 Statistics Term Project: Blake Freemanapi-252919218Noch keine Bewertungen
- Skittles Project FinalDokument8 SeitenSkittles Project Finalapi-548638974Noch keine Bewertungen
- Math 1040 Skittles Term Project EportfolioDokument7 SeitenMath 1040 Skittles Term Project Eportfolioapi-260817278Noch keine Bewertungen
- Final ProjectDokument3 SeitenFinal Projectapi-265661554Noch keine Bewertungen
- Final ProjectDokument6 SeitenFinal Projectapi-283261340Noch keine Bewertungen
- Final Math ProjectDokument7 SeitenFinal Math Projectapi-316775963Noch keine Bewertungen
- Math 1040 Skittles Term ProjectDokument8 SeitenMath 1040 Skittles Term Projectapi-272870073Noch keine Bewertungen
- Skittles Term Project 11 9 14Dokument5 SeitenSkittles Term Project 11 9 14api-192489685Noch keine Bewertungen
- Skittles FinalDokument12 SeitenSkittles Finalapi-241861434Noch keine Bewertungen
- Group Project #1 - SkittlesDokument9 SeitenGroup Project #1 - Skittlesapi-245266056Noch keine Bewertungen
- Term Project ReportDokument9 SeitenTerm Project Reportapi-238585685Noch keine Bewertungen
- Stats StuffDokument7 SeitenStats Stuffapi-242298926Noch keine Bewertungen
- Statistics Term Project E-Portfolio ReflectionDokument8 SeitenStatistics Term Project E-Portfolio Reflectionapi-258147701Noch keine Bewertungen
- Skittles Project Group Final WordDokument6 SeitenSkittles Project Group Final Wordapi-316239273Noch keine Bewertungen
- GCSE Mathematics Numerical Crosswords Foundation Written for the GCSE 9-1 CourseVon EverandGCSE Mathematics Numerical Crosswords Foundation Written for the GCSE 9-1 CourseNoch keine Bewertungen
- How Pi Can Save Your Life: Using Math to Survive Plane Crashes, Zombie Attacks, Alien Encounters, and Other Improbable Real-World SituationsVon EverandHow Pi Can Save Your Life: Using Math to Survive Plane Crashes, Zombie Attacks, Alien Encounters, and Other Improbable Real-World SituationsNoch keine Bewertungen
- IMU-Based Gait Normalcy Index Calculation For Clinical Evaluation of Impaired GaitDokument10 SeitenIMU-Based Gait Normalcy Index Calculation For Clinical Evaluation of Impaired GaitsanahujalidiaNoch keine Bewertungen
- Ch. 4 (Final Paper As of July 12)Dokument12 SeitenCh. 4 (Final Paper As of July 12)PAUL MICHAEL G. BAGUHINNoch keine Bewertungen
- Analysis - Ecological - Data PCA in RDokument126 SeitenAnalysis - Ecological - Data PCA in RBolitox ErazoNoch keine Bewertungen
- Corroletion & Regeression1 Mrs SaharDokument33 SeitenCorroletion & Regeression1 Mrs SaharzodiakNoch keine Bewertungen
- Implication of Online Digital Modules To Academic Performance Among Grade 12 HUMSS Students in Rizal National High SchoolDokument29 SeitenImplication of Online Digital Modules To Academic Performance Among Grade 12 HUMSS Students in Rizal National High SchoolDen Mabasa100% (1)
- CH 12 Solutions Manual PDFDokument43 SeitenCH 12 Solutions Manual PDFErika MorenoNoch keine Bewertungen
- NetCoMi Network Construction and Comparison ForDokument18 SeitenNetCoMi Network Construction and Comparison Forhan zhouNoch keine Bewertungen
- Maths in Chemistry by DR Prerna BansalDokument197 SeitenMaths in Chemistry by DR Prerna BansalEmmanuel Bertrand100% (1)
- Arch Index PDFDokument11 SeitenArch Index PDFBunga Listia ParamitaNoch keine Bewertungen
- The Role of IT in Supporting Vietnam Youth EntrepreneurshipDokument4 SeitenThe Role of IT in Supporting Vietnam Youth EntrepreneurshipEditor IJTSRDNoch keine Bewertungen
- The Reliability and Validity of Three Non-Radiological Measures of Thoracic Kyphosis and Their Relations To The Standing Radiological Cobb AngleDokument9 SeitenThe Reliability and Validity of Three Non-Radiological Measures of Thoracic Kyphosis and Their Relations To The Standing Radiological Cobb Angle박진영Noch keine Bewertungen
- Chapter 3Dokument15 SeitenChapter 3aisyahazaliNoch keine Bewertungen
- An Examination of Written Work and Performance Task in General Mathematics and Precalculus of Filipino STEM LearnersDokument13 SeitenAn Examination of Written Work and Performance Task in General Mathematics and Precalculus of Filipino STEM LearnersStephanie Jessa ChinteNoch keine Bewertungen
- Course Handout 2023Dokument5 SeitenCourse Handout 2023ankit aggarwalNoch keine Bewertungen
- Contribution of Visionary Leadership, Lecturer Performance, and Academic CultureDokument17 SeitenContribution of Visionary Leadership, Lecturer Performance, and Academic CulturedelaNoch keine Bewertungen
- StatisticsDokument61 SeitenStatisticsCriscel Sambrano VivaresNoch keine Bewertungen
- Practice Questions: Maths PhysicsDokument3 SeitenPractice Questions: Maths PhysicsPAUL KOLERENoch keine Bewertungen
- Enhancing Socio-Economic Empowerment Through Financial Inclusion Initiatives A Case Study of Rwanda Union of The BlindDokument18 SeitenEnhancing Socio-Economic Empowerment Through Financial Inclusion Initiatives A Case Study of Rwanda Union of The BlindKIU PUBLICATION AND EXTENSIONNoch keine Bewertungen
- Hypothesis TestingDokument26 SeitenHypothesis TestingAzmuthNoch keine Bewertungen
- Biostatistics: A Refresher: Kevin M. Sowinski, Pharm.D., FCCPDokument20 SeitenBiostatistics: A Refresher: Kevin M. Sowinski, Pharm.D., FCCPNaji Mohamed Alfatih100% (1)
- Role of Emotional Intelligence in Effective LeadershipDokument12 SeitenRole of Emotional Intelligence in Effective LeadershipAyesha ShamimNoch keine Bewertungen
- Stat and Prob Q4 Week 7 Module 15 LorenaDokument24 SeitenStat and Prob Q4 Week 7 Module 15 LorenakatecharisseaNoch keine Bewertungen
- Using IBM SPSS Statistics - An Interactive Hands-On Approach (2016) James AldrichDokument473 SeitenUsing IBM SPSS Statistics - An Interactive Hands-On Approach (2016) James AldrichSabcMxyz100% (6)
- Impact of Hostel Students' Satisfaction On TheirDokument9 SeitenImpact of Hostel Students' Satisfaction On TheirAzzyHazimah0% (1)
- Correlation Between Match Performance and Field Tests in Professional Soccer PlayersDokument7 SeitenCorrelation Between Match Performance and Field Tests in Professional Soccer PlayersJUAN GERMAN GARZON MOLINANoch keine Bewertungen
- Assignment Six 20 PointsDokument8 SeitenAssignment Six 20 PointsSubhash KorumilliNoch keine Bewertungen
- VISA A enDokument8 SeitenVISA A enNestor NetoNoch keine Bewertungen
- The Impact of Internet On Academic Performance of Comilla University StudentsDokument38 SeitenThe Impact of Internet On Academic Performance of Comilla University Studentsshemali akterNoch keine Bewertungen
- Inferential Analysis SPSSDokument55 SeitenInferential Analysis SPSSSuhazeli AbdullahNoch keine Bewertungen
- Bootstrap Methods and Their Applications.Dokument96 SeitenBootstrap Methods and Their Applications.FernandaNoch keine Bewertungen