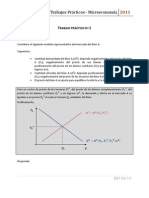
Das könnte Ihnen auch gefallen
- Solucionario Del Capítulo 2 de Pindyck-Mayo-2010Dokument15 SeitenSolucionario Del Capítulo 2 de Pindyck-Mayo-2010riemmaNoch keine Bewertungen
- Soluciones Al Capítulo 3 de PindyckDokument5 SeitenSoluciones Al Capítulo 3 de Pindyckriemma33% (6)
- Trabajo FinalDokument13 SeitenTrabajo FinalLuis Alberto Pulido CamposNoch keine Bewertungen
- (PRACTICA) Ejercicios PropuestosDokument6 Seiten(PRACTICA) Ejercicios PropuestosMila50% (2)
- Tarea Economía M1 - Cap. 24 y 25Dokument6 SeitenTarea Economía M1 - Cap. 24 y 25Jesus SalvadorNoch keine Bewertungen
- Mankiw (2014) Ejercicios Cap 5Dokument1 SeiteMankiw (2014) Ejercicios Cap 5Germán Utz60% (5)
- Capítulo 7 - Funciones de ProducciónDokument45 SeitenCapítulo 7 - Funciones de ProducciónMARTIN EMILIO VAZQUEZ SARMIENTONoch keine Bewertungen
- Microeconomía Intermedia, Un Enfoque Actual EjerciciosDokument7 SeitenMicroeconomía Intermedia, Un Enfoque Actual Ejercicioseskiz010% (2)
- Tarea 2 PDFDokument3 SeitenTarea 2 PDFDavid CanulNoch keine Bewertungen
- Solucionario Mankiw Apuntes 4 9Dokument48 SeitenSolucionario Mankiw Apuntes 4 9Miguel100% (1)
- Monopolio Clases 21 y 22 (Cap 13 Nicholson)Dokument53 SeitenMonopolio Clases 21 y 22 (Cap 13 Nicholson)danielNoch keine Bewertungen
- Capítulo 10 El Poder de Mercado - El Monopolio y El MonopsonioDokument13 SeitenCapítulo 10 El Poder de Mercado - El Monopolio y El MonopsonioDaniel Collazos Merino0% (2)
- Sin TítuloDokument1 SeiteSin TítuloShirley Farfan100% (1)
- Practica 2 de Fundamentos de EconomiaDokument1 SeitePractica 2 de Fundamentos de EconomiaLeonela MuñozNoch keine Bewertungen
- Microeconomia Problem Set 1 SolutionDokument16 SeitenMicroeconomia Problem Set 1 Solutionriemma67% (3)
- Microeconomia Problem Set 1 SolutionDokument16 SeitenMicroeconomia Problem Set 1 Solutionriemma67% (3)
- Microeconomia Problem Set 1 SolutionDokument16 SeitenMicroeconomia Problem Set 1 Solutionriemma67% (3)
- Microeconomia Problem Set 1 SolutionDokument16 SeitenMicroeconomia Problem Set 1 Solutionriemma67% (3)
- Taller 2 Estadìstica InferencialDokument15 SeitenTaller 2 Estadìstica InferencialstivenNoch keine Bewertungen
- Ejercicios resueltos de microeconomía intermedia: Óptimo del productorVon EverandEjercicios resueltos de microeconomía intermedia: Óptimo del productorNoch keine Bewertungen
- Externalidad Edgard CordovaDokument6 SeitenExternalidad Edgard CordovaEdgard Cordova100% (1)
- TP Equilibrio Parcial - Microeconomia IIDokument4 SeitenTP Equilibrio Parcial - Microeconomia IIJosefina Valenzuela Grauschopf0% (1)
- Ejercicios Resueltos de Microeconomía - Guillermo Pereyra - 1edDokument35 SeitenEjercicios Resueltos de Microeconomía - Guillermo Pereyra - 1edalbi_12291214100% (4)
- Ejercicios Adicionales PDFDokument9 SeitenEjercicios Adicionales PDFandersonNoch keine Bewertungen
- EjerciciosDokument6 SeitenEjerciciosLuis Palomino Toscano0% (2)
- Ejercicios Cap 5 y 6Dokument11 SeitenEjercicios Cap 5 y 6Nicolas Rodriguez BarraganNoch keine Bewertungen
- Cuestionario 3-4Dokument5 SeitenCuestionario 3-4Gustavo PereaNoch keine Bewertungen
- Soluciones Ejercicios Cap. 8 - Funciones de Costos - Novena EdiciónDokument10 SeitenSoluciones Ejercicios Cap. 8 - Funciones de Costos - Novena EdiciónDeisy GomezNoch keine Bewertungen
- Práctica Eq. GeneralDokument3 SeitenPráctica Eq. GeneralMadssss12Noch keine Bewertungen
- Capitulo 16Dokument7 SeitenCapitulo 16Luz Angelica RAMIREZ SANABRIANoch keine Bewertungen
- Practica 2 Análisis MicroeconómicoDokument5 SeitenPractica 2 Análisis Microeconómicodeisy sanchez florezNoch keine Bewertungen
- Trabajo Tercer CorteDokument6 SeitenTrabajo Tercer CorteKaren Galindo0% (1)
- Ejercicios MonopolistasDokument4 SeitenEjercicios MonopolistasMaricielo llauceNoch keine Bewertungen
- Soluciones Ejercicios Cap. 8 - Funciones de Costos - Novena EdiciónDokument9 SeitenSoluciones Ejercicios Cap. 8 - Funciones de Costos - Novena Ediciónfranklin queroNoch keine Bewertungen
- Ejercicios de Oferta, Demanda, Equilibrio, Precios Máximos y Mínimos e ImpuestosDokument9 SeitenEjercicios de Oferta, Demanda, Equilibrio, Precios Máximos y Mínimos e ImpuestosESTEFANY DUARTENoch keine Bewertungen
- Ba Lotario 001Dokument16 SeitenBa Lotario 001jose0% (1)
- Ejercicio #12 - #17Dokument12 SeitenEjercicio #12 - #17Nataly CortezNoch keine Bewertungen
- Ejercicios Resueltos de Microeconomia Mercado de Factores2013Dokument11 SeitenEjercicios Resueltos de Microeconomia Mercado de Factores2013goyo58100% (4)
- Tarea 2 Mercado y EmpresaDokument2 SeitenTarea 2 Mercado y EmpresaGbNoch keine Bewertungen
- Capitulo 2: - EjerciciosDokument51 SeitenCapitulo 2: - EjerciciosDANA VANESSA SUAZANoch keine Bewertungen
- Dokumen - Tips - Problemas Capitulo 8 Robert S PindyckDokument9 SeitenDokumen - Tips - Problemas Capitulo 8 Robert S Pindyckvalentina burgosNoch keine Bewertungen
- Ejercicio 8Dokument3 SeitenEjercicio 8Daniela Núñez PrietoNoch keine Bewertungen
- Notas de ClaseDokument2 SeitenNotas de ClaseTania Gomez Vargas100% (2)
- NicholsonDokument4 SeitenNicholsonedwin daniel yovera yovera100% (1)
- Teoría de Juegos Ejercicio 13, Equilibrio General Ejerc 1,2 y 3.Dokument3 SeitenTeoría de Juegos Ejercicio 13, Equilibrio General Ejerc 1,2 y 3.susana gomezNoch keine Bewertungen
- TALLER FINAL EconomiaEmpDokument4 SeitenTALLER FINAL EconomiaEmpNatalia SanchezNoch keine Bewertungen
- Ejercicios Resueltos de Microeconomia - El Óptimo Del Consumidor y La Demanda, RevisadoDokument10 SeitenEjercicios Resueltos de Microeconomia - El Óptimo Del Consumidor y La Demanda, RevisadoIsaac Carranza100% (2)
- Ejercicio 7-14Dokument6 SeitenEjercicio 7-14Lis Denis Zapata JaraNoch keine Bewertungen
- Taller 1 Matematica BasicaDokument5 SeitenTaller 1 Matematica BasicaLuisa Lagos100% (1)
- Microeconomia 2 X HcerDokument6 SeitenMicroeconomia 2 X HcerLuis Alfredo Ochoa BurgosNoch keine Bewertungen
- Capitulo 1Dokument5 SeitenCapitulo 1David PMNoch keine Bewertungen
- Ejercicios de Modelo KeynesianoDokument12 SeitenEjercicios de Modelo KeynesianoAlvaro Diego Vizarreta OlaecheaNoch keine Bewertungen
- Prueba de Hipotesis Con SpssDokument6 SeitenPrueba de Hipotesis Con SpssDante Cruz CLNoch keine Bewertungen
- Tra Pra04 MEM Barahona VacaDokument10 SeitenTra Pra04 MEM Barahona Vacageovanny barahona vaca100% (1)
- Ejercicios de Monopolio y Franja CometitivaDokument5 SeitenEjercicios de Monopolio y Franja CometitivaFiorella Lisbeth Chumioque FernandezNoch keine Bewertungen
- Ejercicio 10 Cap.14Dokument2 SeitenEjercicio 10 Cap.14Esteban Hernández0% (1)
- Tarea 11 Economia GeneralDokument7 SeitenTarea 11 Economia GeneralEsmeralda Victorio100% (1)
- Nicholson Teoria Microeconomica Cap 18Dokument28 SeitenNicholson Teoria Microeconomica Cap 18rosalia JustoNoch keine Bewertungen
- Cap14 PindyckDokument85 SeitenCap14 PindyckCarli La RosaNoch keine Bewertungen
- Ejercicio 5 Capitulo 12Dokument1 SeiteEjercicio 5 Capitulo 12Esteban HernándezNoch keine Bewertungen
- Solucionario Mankiw Apuntes 4 9Dokument48 SeitenSolucionario Mankiw Apuntes 4 9Angel Castro100% (1)
- Regresión Lineal Simpl1Dokument7 SeitenRegresión Lineal Simpl1Renato SánchezNoch keine Bewertungen
- Regresión Lineal Simple - 9amDokument5 SeitenRegresión Lineal Simple - 9amPatricio AmorósNoch keine Bewertungen
- Tema 9a - 2019 - Regresi+ N Lineal Multiple JAMDokument77 SeitenTema 9a - 2019 - Regresi+ N Lineal Multiple JAMAnthony Piedra MedinaNoch keine Bewertungen
- Lectura 4Dokument10 SeitenLectura 4Erne TrejoNoch keine Bewertungen
- Taller Sobre Ecuaciones, Inecuaciones y Valor AbsolutoDokument14 SeitenTaller Sobre Ecuaciones, Inecuaciones y Valor AbsolutoDiana Bohorquez LopezNoch keine Bewertungen
- Curriculum Vitae Agosto 2012Dokument8 SeitenCurriculum Vitae Agosto 2012riemma100% (1)
- Curso Econometría IPIE 2012Dokument4 SeitenCurso Econometría IPIE 2012emiliortiz1Noch keine Bewertungen
- Green Capítulo 2 Ejercicio 5Dokument3 SeitenGreen Capítulo 2 Ejercicio 5riemmaNoch keine Bewertungen
- Curriculum Vitae Noviembre 2012Dokument6 SeitenCurriculum Vitae Noviembre 2012riemmaNoch keine Bewertungen
- Green Capítulo 2 Ejercicio 5Dokument2 SeitenGreen Capítulo 2 Ejercicio 5riemmaNoch keine Bewertungen
- Estudio Sobre Los Sistemas Previsionales Del ParaguayDokument54 SeitenEstudio Sobre Los Sistemas Previsionales Del ParaguayriemmaNoch keine Bewertungen
- Curriculum Vitae Julio 2012Dokument11 SeitenCurriculum Vitae Julio 2012riemmaNoch keine Bewertungen
- Junio de 2012 Operaciones CambiariasDokument1 SeiteJunio de 2012 Operaciones CambiariasriemmaNoch keine Bewertungen
- La Deserción Escolar y Sus Costos en ParaguayDokument125 SeitenLa Deserción Escolar y Sus Costos en Paraguayriemma100% (3)
- La Presión Fiscal en ArgentinaDokument399 SeitenLa Presión Fiscal en ArgentinariemmaNoch keine Bewertungen
- Testimonio Rafael BriscoDokument2 SeitenTestimonio Rafael BriscoriemmaNoch keine Bewertungen
- Informe Recarte de LD Sobre Crack FinancieraDokument44 SeitenInforme Recarte de LD Sobre Crack Financierajuanloprada100% (1)
- Do 1201Dokument40 SeitenDo 1201riemmaNoch keine Bewertungen
- La Economia de Paraguay 1940 20081Dokument44 SeitenLa Economia de Paraguay 1940 20081riemmaNoch keine Bewertungen
- Cómo Aplicar El Modelo de Rasch A La MediciónDokument9 SeitenCómo Aplicar El Modelo de Rasch A La MediciónriemmaNoch keine Bewertungen
- Capítulo 2Dokument11 SeitenCapítulo 2riemmaNoch keine Bewertungen
- Programa-2Dokument2 SeitenPrograma-2riemmaNoch keine Bewertungen
- Programa MatematicasDokument3 SeitenPrograma Matematicaseco_alvaroNoch keine Bewertungen
- Curso Matemáticas y Microeconomía 2012Dokument1 SeiteCurso Matemáticas y Microeconomía 2012riemmaNoch keine Bewertungen
- Capítulo 3Dokument15 SeitenCapítulo 3riemmaNoch keine Bewertungen
- Testimonio Ryan ThompsonDokument1 SeiteTestimonio Ryan ThompsonriemmaNoch keine Bewertungen
- La Deserción Escolar y Sus CostosDokument115 SeitenLa Deserción Escolar y Sus CostosriemmaNoch keine Bewertungen
- Diagrama de Flujo de La Crisis Del EuroDokument5 SeitenDiagrama de Flujo de La Crisis Del EuroriemmaNoch keine Bewertungen
- La Deserción Escolar y Sus CostosDokument73 SeitenLa Deserción Escolar y Sus CostosriemmaNoch keine Bewertungen
- La Desercion Escolar en Paraguay - PortalGuaraniDokument114 SeitenLa Desercion Escolar en Paraguay - PortalGuaraniPortal Guarani100% (3)
- La Deserción Escolar y Sus CostosDokument105 SeitenLa Deserción Escolar y Sus CostosriemmaNoch keine Bewertungen
- Metodos Cos en La Ingenieria 1o Parcial SolucionesDokument4 SeitenMetodos Cos en La Ingenieria 1o Parcial SolucioneswgbikrredmNoch keine Bewertungen
- Practica 1Dokument4 SeitenPractica 1Rony Martin Alegria RodriguezNoch keine Bewertungen
- Unidad Septiembre - SetiembreDokument4 SeitenUnidad Septiembre - SetiembreMARTHNoch keine Bewertungen
- Método de Procedimientos Especiales2020Dokument12 SeitenMétodo de Procedimientos Especiales2020Diego PomaNoch keine Bewertungen
- Relacion Del Medio Ambiente Con Las Medidas de DispersionDokument10 SeitenRelacion Del Medio Ambiente Con Las Medidas de DispersionRoyer Jhonathan BañosNoch keine Bewertungen
- Quiz 1 PDFDokument8 SeitenQuiz 1 PDFEmilsenNoch keine Bewertungen
- Problemas Con Medidas de Tendencia Central y Dispersión: Laura Lorenia Sandoval Salcido (Al12508174)Dokument7 SeitenProblemas Con Medidas de Tendencia Central y Dispersión: Laura Lorenia Sandoval Salcido (Al12508174)lauraloreniaNoch keine Bewertungen
- Trabajo Metodología de La Investigación Científica - Grupo 03Dokument46 SeitenTrabajo Metodología de La Investigación Científica - Grupo 03Franc_canNoch keine Bewertungen
- S01.s1 - Material - Pdf-ActualDokument53 SeitenS01.s1 - Material - Pdf-ActualNoely MabelNoch keine Bewertungen
- SIM02 ContenidosActualizadoPaginaUnicaDokument33 SeitenSIM02 ContenidosActualizadoPaginaUnicaafrass18Noch keine Bewertungen
- OC 1 Estadística Descriptiva v5Dokument38 SeitenOC 1 Estadística Descriptiva v5Cesar GouroNoch keine Bewertungen
- ABP Primero Medio - LL - EMDokument7 SeitenABP Primero Medio - LL - EMcarolinaNoch keine Bewertungen
- Clase 1 Prueba de Hipótesis para Un PromedioDokument4 SeitenClase 1 Prueba de Hipótesis para Un PromedioFiorella Rios GoñyNoch keine Bewertungen
- Taller No. 1 Estadística II - 2019-IIDokument3 SeitenTaller No. 1 Estadística II - 2019-IILeidy SuarezNoch keine Bewertungen
- 2do EXP. APRE 3 2022-1Dokument15 Seiten2do EXP. APRE 3 2022-1Junior LCNoch keine Bewertungen
- S 03.1 Binomial PoissonDokument51 SeitenS 03.1 Binomial PoissonMayraRiosDiazNoch keine Bewertungen
- Taller de Investigación - Bosquejo Del MétodoDokument35 SeitenTaller de Investigación - Bosquejo Del MétodoSheyNoch keine Bewertungen
- CronogramanFasen1nnAnnnlisis 4663f9b22768b10 PDFDokument3 SeitenCronogramanFasen1nnAnnnlisis 4663f9b22768b10 PDFFernanda PosadaNoch keine Bewertungen
- Distribucion Binomial NegativaDokument8 SeitenDistribucion Binomial NegativaAndrea Giramar CantilloNoch keine Bewertungen
- LIBRO PRACTICAS BIOESTADÍSTICA 3eraed CHIPIA PDFDokument52 SeitenLIBRO PRACTICAS BIOESTADÍSTICA 3eraed CHIPIA PDFMaría zambranoNoch keine Bewertungen
- Trabajo Final EstadisticaDokument19 SeitenTrabajo Final EstadisticaNay Jey DssNoch keine Bewertungen
- Kevin Brian Roblero Perez. Ejercicios InfoStatDokument17 SeitenKevin Brian Roblero Perez. Ejercicios InfoStatkevin robleroNoch keine Bewertungen
- MercadoteniaDokument118 SeitenMercadotenialftellezcNoch keine Bewertungen
- Fuentes de InformaciónDokument8 SeitenFuentes de InformaciónDamian DiazNoch keine Bewertungen
- ANALISISDokument4 SeitenANALISISOlga OxteNoch keine Bewertungen
- Est Ad Is Tic AsDokument46 SeitenEst Ad Is Tic AsMatthew Lewis100% (5)
- Actividad 7 Estadistica 20092020 ExcelDokument14 SeitenActividad 7 Estadistica 20092020 ExcelDIANA MARCELA PEREZ RodriguezNoch keine Bewertungen
- Estadistica InfDokument2 SeitenEstadistica InfMiguel Limon50% (2)