Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Century 21 South Western Accounting Answer Key Free PDF Ebook Download Century 21 South Western Accounting Answer Key Download or Read Online Ebook Century 21 SouthDokument8 SeitenCentury 21 South Western Accounting Answer Key Free PDF Ebook Download Century 21 South Western Accounting Answer Key Download or Read Online Ebook Century 21 SouthJohn0% (4)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (120)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Assignment 2 Grammar Lesson PlanDokument26 SeitenAssignment 2 Grammar Lesson PlanKesia Kerspay100% (1)
- AS400 RPG400 BasicsDokument148 SeitenAS400 RPG400 Basicscharaviz84100% (1)
- Mid Term Exam SQLDokument17 SeitenMid Term Exam SQLSebastian Ajesh100% (1)
- Some Other Links That May Help You! Make Sure To Check If The Answer Is Right!Dokument16 SeitenSome Other Links That May Help You! Make Sure To Check If The Answer Is Right!GilangMaulanaNoch keine Bewertungen
- Some Other Links That May Help You! Make Sure To Check If The Answer Is Right!Dokument16 SeitenSome Other Links That May Help You! Make Sure To Check If The Answer Is Right!GilangMaulanaNoch keine Bewertungen
- Some Other Links That May Help You! Make Sure To Check If The Answer Is Right!Dokument16 SeitenSome Other Links That May Help You! Make Sure To Check If The Answer Is Right!GilangMaulanaNoch keine Bewertungen
- Makaut Grade Card Collection Notice 2018-19Dokument1 SeiteMakaut Grade Card Collection Notice 2018-19Sourav PandaNoch keine Bewertungen
- BM Stake Holders Case Study 1st November 2023Dokument2 SeitenBM Stake Holders Case Study 1st November 2023Arsath malik ArsathNoch keine Bewertungen
- 1802SupplementaryNotes FullDokument235 Seiten1802SupplementaryNotes FullCourtney WilliamsNoch keine Bewertungen
- Miracle Mills 300 Series Hammer MillsDokument2 SeitenMiracle Mills 300 Series Hammer MillsSNoch keine Bewertungen
- Entropy Equation For A Control VolumeDokument12 SeitenEntropy Equation For A Control VolumenirattisaikulNoch keine Bewertungen
- PreNav - Pitch - Customers Wind SiDokument20 SeitenPreNav - Pitch - Customers Wind SiKaterinaLiNoch keine Bewertungen
- Engine Torque Settings and Spec's 3.0L V6 SCDokument4 SeitenEngine Torque Settings and Spec's 3.0L V6 SCMario MaravillaNoch keine Bewertungen
- ICorr CED CT01 InspectionAndTestingOfCoatings Issue1-2Dokument13 SeitenICorr CED CT01 InspectionAndTestingOfCoatings Issue1-2AlineMeirelesNoch keine Bewertungen
- Response 2000 IntroductionDokument24 SeitenResponse 2000 IntroductionRory Cristian Cordero RojoNoch keine Bewertungen
- Parkinson S Disease Detection Based On SDokument5 SeitenParkinson S Disease Detection Based On SdaytdeenNoch keine Bewertungen
- Critique of Violence - Walter BenjaminDokument14 SeitenCritique of Violence - Walter BenjaminKazım AteşNoch keine Bewertungen
- SPECIFIC ENERGY, ENERGY DENSITY OF FUELS and PRIMARY ENERGY SOURCESDokument17 SeitenSPECIFIC ENERGY, ENERGY DENSITY OF FUELS and PRIMARY ENERGY SOURCESPranavBalarajuNoch keine Bewertungen
- Concession Project List Excel 02-Aug-2019Dokument15 SeitenConcession Project List Excel 02-Aug-2019Vishal BansalNoch keine Bewertungen
- 9A02505 Electrical Machines-IIIDokument4 Seiten9A02505 Electrical Machines-IIIsivabharathamurthyNoch keine Bewertungen
- Formal Report Expt 5Dokument6 SeitenFormal Report Expt 5AnonymouscatNoch keine Bewertungen
- 2021 3 AbstractsDokument168 Seiten2021 3 AbstractsLong An ĐỗNoch keine Bewertungen
- Ad 9915Dokument47 SeitenAd 9915Jime nitaNoch keine Bewertungen
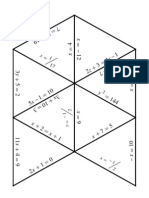
- Algebra1 Review PuzzleDokument3 SeitenAlgebra1 Review PuzzleNicholas Yates100% (1)
- How The Audiences Feel Closer and Connected To Their Culture With StorytellingDokument7 SeitenHow The Audiences Feel Closer and Connected To Their Culture With Storytellingmarcelo quezadaNoch keine Bewertungen
- Chapter4 RetainingwallDokument55 SeitenChapter4 RetainingwallNur HazwaniNoch keine Bewertungen
- Mech Syllabus R-2017 - 1Dokument110 SeitenMech Syllabus R-2017 - 1goujjNoch keine Bewertungen
- MHSS ItalyDokument9 SeitenMHSS Italyromedic36Noch keine Bewertungen
- Anger Management: Gaurav Sharma 138Dokument21 SeitenAnger Management: Gaurav Sharma 138gaurav_sharma_19900Noch keine Bewertungen
- PCBDokument5 SeitenPCBarampandey100% (4)
- AIMMS Modeling Guide - Linear Programming TricksDokument16 SeitenAIMMS Modeling Guide - Linear Programming TricksgjorhugullNoch keine Bewertungen
- Lithospheric Evolution of The Pre-And Early Andean Convergent Margin, ChileDokument29 SeitenLithospheric Evolution of The Pre-And Early Andean Convergent Margin, ChileAbdiel MuñozNoch keine Bewertungen
- Occupational Therapy Examination Review Guide 4th Edition Ebook PDFDokument57 SeitenOccupational Therapy Examination Review Guide 4th Edition Ebook PDFrobert.campbell485Noch keine Bewertungen