Das könnte Ihnen auch gefallen
- 2 Ensamblaje Placa MadreDokument31 Seiten2 Ensamblaje Placa MadreGustavo Jurado AlfaroNoch keine Bewertungen
- Factor Forma Placa BaseDokument19 SeitenFactor Forma Placa BaseMaría Del Mar Romero RicoNoch keine Bewertungen
- Partes principales motherboardDokument7 SeitenPartes principales motherboardStefy Del BfNoch keine Bewertungen
- Desarrollo de Las Placas BasesDokument9 SeitenDesarrollo de Las Placas Basesjose_22_96Noch keine Bewertungen
- TEMA 3.1 La Placa BaseDokument33 SeitenTEMA 3.1 La Placa BaseGuadalupe WilsonNoch keine Bewertungen
- Mini ItxDokument2 SeitenMini ItxJosé Antonio Yáñez JiménezNoch keine Bewertungen
- LPXDokument9 SeitenLPXDavid Nuñez HerreraNoch keine Bewertungen
- PC at Pentium IvDokument18 SeitenPC at Pentium IvJesus HuamaniNoch keine Bewertungen
- Info DTXDokument7 SeitenInfo DTXSantiago SamaniegoNoch keine Bewertungen
- CuestionarioDokument6 SeitenCuestionarioJohan RiveroNoch keine Bewertungen
- Tecnologia FabricantesDokument3 SeitenTecnologia FabricantesEduardo PinoNoch keine Bewertungen
- Tipos de MainboardDokument7 SeitenTipos de MainboardJesenia Jessica Cota Rosello0% (1)
- La Board y Sus PartesDokument84 SeitenLa Board y Sus PartesJulio C Julio CeballosNoch keine Bewertungen
- Tarea Tarjeta MadreDokument5 SeitenTarea Tarjeta MadreCesar LimaNoch keine Bewertungen
- Laboard22 10Dokument3 SeitenLaboard22 10mara ramirezNoch keine Bewertungen
- 9 - Placas Madres - (Mainboard)Dokument82 Seiten9 - Placas Madres - (Mainboard)Alee CastilloNoch keine Bewertungen
- Los Motherboard o Tarjetas MadresDokument10 SeitenLos Motherboard o Tarjetas MadresEduardo RomeroNoch keine Bewertungen
- Placas BaseDokument22 SeitenPlacas BasesalekmustafaNoch keine Bewertungen
- HISTORIA DE LA MAINBOARDDokument5 SeitenHISTORIA DE LA MAINBOARDZeta GussNoch keine Bewertungen
- MotherboardDokument22 SeitenMotherboardJn Pablx RivasNoch keine Bewertungen
- Mainboard, Supercomputadores y MemoriasDokument5 SeitenMainboard, Supercomputadores y MemoriasPablo Guaman NovilloNoch keine Bewertungen
- Tipos de Tarjeta MadreDokument5 SeitenTipos de Tarjeta Madrearmenta ivanNoch keine Bewertungen
- Concepto de Términos de EnsamblajeDokument13 SeitenConcepto de Términos de EnsamblajeCarito Luján MorenoNoch keine Bewertungen
- 1 Placa MadreDokument30 Seiten1 Placa MadreAntonio ChávezNoch keine Bewertungen
- Placas MadresDokument15 SeitenPlacas MadresUNA VIDA FELIZNoch keine Bewertungen
- Evolucion de Las Tarjetas MadresDokument5 SeitenEvolucion de Las Tarjetas MadresljfjNoch keine Bewertungen
- Manipulacion y Reconocimiento de Partes Internas de La PCDokument6 SeitenManipulacion y Reconocimiento de Partes Internas de La PCesmailsatoruNoch keine Bewertungen
- Capítulo 2 (Parte 1) - Placa BaseDokument42 SeitenCapítulo 2 (Parte 1) - Placa BaseJulián Sánchez CruzNoch keine Bewertungen
- Investigacion Placas MadreDokument10 SeitenInvestigacion Placas MadreAdrian CalderonNoch keine Bewertungen
- P0401 - Trabajo Placa BaseDokument14 SeitenP0401 - Trabajo Placa BaseRCRNoch keine Bewertungen
- Manual Del HardwareDokument120 SeitenManual Del HardwareandrewskyNoch keine Bewertungen
- Tipos Placa Base PDFDokument6 SeitenTipos Placa Base PDFBunny Swam100% (1)
- Aplicaciones de ChipsetDokument2 SeitenAplicaciones de ChipsetPacko Santhos100% (1)
- BoardDokument13 SeitenBoardDavid RestrepoNoch keine Bewertungen
- La MotherboardDokument10 SeitenLa MotherboardanakarinaNoch keine Bewertungen
- Rafael Pinto Soto MotherboardDokument6 SeitenRafael Pinto Soto MotherboardADRIAN DAVID ROSADO GUERRANoch keine Bewertungen
- Investigacion Chipset - Unidad 3 Arquitectura de ComputadorasDokument8 SeitenInvestigacion Chipset - Unidad 3 Arquitectura de Computadorasjuan pablo50% (2)
- Tipos de GabinetesDokument8 SeitenTipos de GabinetesJessica Soliz CatariNoch keine Bewertungen
- Mainboard y ProcesadoresDokument8 SeitenMainboard y ProcesadoresOscar Xavier Montero CampaverdeNoch keine Bewertungen
- Investigacion ChipsetDokument17 SeitenInvestigacion ChipsetRamon Cano Prieto0% (1)
- MainboardDokument91 SeitenMainboardecorisa10Noch keine Bewertungen
- Catálogo de Tarjetas MadreDokument10 SeitenCatálogo de Tarjetas MadreAngel ArcosNoch keine Bewertungen
- Recuperacion BoardDokument2 SeitenRecuperacion Boardmara ramirezNoch keine Bewertungen
- 2.1 Factor de FormaDokument37 Seiten2.1 Factor de FormaEleonora RodríguezNoch keine Bewertungen
- Placas Madre: Guía de los Principales Tipos de Tarjetas MadreDokument10 SeitenPlacas Madre: Guía de los Principales Tipos de Tarjetas MadreAdrian CalderonNoch keine Bewertungen
- Evolucion de Los ChipsetDokument8 SeitenEvolucion de Los ChipsetEnriqueManserverNoch keine Bewertungen
- Actividades Tema 2-1Dokument15 SeitenActividades Tema 2-1picardoisNoch keine Bewertungen
- ComponentesHardware_1Dokument112 SeitenComponentesHardware_1ratiarodriguezaNoch keine Bewertungen
- Factor de Forma en La Placa Base Tarea 2 - DRPDokument2 SeitenFactor de Forma en La Placa Base Tarea 2 - DRPDavid Ruiz PulidoNoch keine Bewertungen
- SI-TEMA 4 - Placa Base Grafica BusesDokument41 SeitenSI-TEMA 4 - Placa Base Grafica Buseshalfonso01Noch keine Bewertungen
- Factores de Forma Pico ITX y LPXDokument28 SeitenFactores de Forma Pico ITX y LPXChristian Alejandro Ceballos FonsecaNoch keine Bewertungen
- La Placa BaseDokument11 SeitenLa Placa BaseAna María MínguezNoch keine Bewertungen
- Practica 3 - Partes de La Placa MadreDokument7 SeitenPractica 3 - Partes de La Placa MadreSusanRCNoch keine Bewertungen
- Aplicaciones ChipsetDokument3 SeitenAplicaciones ChipsetEduardo Martinez TadeoNoch keine Bewertungen
- Manual y partes de la MotherboardDokument25 SeitenManual y partes de la MotherboardCarolinaPiedrahitaNoch keine Bewertungen
- Desarrollo DigitalDokument9 SeitenDesarrollo DigitalDiego Martínez PérezNoch keine Bewertungen
- Tipos de MotherboardDokument8 SeitenTipos de MotherboardMario ValladaresNoch keine Bewertungen
- Tema VI Arquitectura Interna Del ComputadorDokument21 SeitenTema VI Arquitectura Interna Del ComputadorDom HernándezNoch keine Bewertungen
- Chipset PDFDokument6 SeitenChipset PDFCarlos Alberto Sánchez CastroNoch keine Bewertungen
- Iniciación al diseño de circuitos impresos con Altium DesignerVon EverandIniciación al diseño de circuitos impresos con Altium DesignerNoch keine Bewertungen
- 638 Finanzas%2BI Capitulo4 Planeacion%2BFinancieraDokument35 Seiten638 Finanzas%2BI Capitulo4 Planeacion%2BFinancieraghettosoNoch keine Bewertungen
- Matematicas y Papiroflexia PDFDokument276 SeitenMatematicas y Papiroflexia PDFvidaldoval92% (12)
- Fundamentos Matemáticos de La IngenieríaDokument299 SeitenFundamentos Matemáticos de La IngenieríaGeancarlos Cubas Palacios100% (1)
- Adaptación de Los Objetivos Del Programa de Estimulación Portage para Niños Con Sindrome de Down de 0 A 6 AñosDokument188 SeitenAdaptación de Los Objetivos Del Programa de Estimulación Portage para Niños Con Sindrome de Down de 0 A 6 AñosghettosoNoch keine Bewertungen
- Guia PEI 010313 PDFDokument52 SeitenGuia PEI 010313 PDFPamela Carolina100% (1)
- Desarrollo de Aplicaciones para Dispositivos Android (Piano)Dokument142 SeitenDesarrollo de Aplicaciones para Dispositivos Android (Piano)ronald_ecqNoch keine Bewertungen
- Lectura Metodo TroncosoDokument15 SeitenLectura Metodo TroncosoghettosoNoch keine Bewertungen
- Metodo TroncosoDokument17 SeitenMetodo TroncosoAna Laura Gi71% (7)
- C#Dokument175 SeitenC#ghettoso100% (2)
- 00820083007960Dokument35 Seiten00820083007960ghettoso0% (1)
- Te Amo AleDokument1 SeiteTe Amo AleghettosoNoch keine Bewertungen
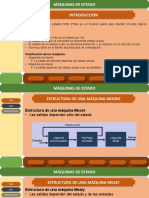
- FSM AsmDokument46 SeitenFSM AsmFernando GuiraudNoch keine Bewertungen
- Borrado de Archivos y Formato en Flash y NVRAM Router CISCODokument1 SeiteBorrado de Archivos y Formato en Flash y NVRAM Router CISCOcurrin20100% (1)
- Laboratorios 2023Dokument11 SeitenLaboratorios 2023Karla CozNoch keine Bewertungen
- PG-655-Mejia Flores, Heriberto JulioDokument189 SeitenPG-655-Mejia Flores, Heriberto JulioDavid C. AlvesteguiNoch keine Bewertungen
- Informe Practica 7Dokument4 SeitenInforme Practica 7Diego Alejandro Gómez GaviriaNoch keine Bewertungen
- Manejo de Swing en JAVA para NetbeansDokument24 SeitenManejo de Swing en JAVA para NetbeanselamigojohnNoch keine Bewertungen
- Taller 1 Digitales IiDokument5 SeitenTaller 1 Digitales IiKelly GomezxdedNoch keine Bewertungen
- Excel de Bienes Sin Codigos 2021 para Inventario (3) 20.01.2022Dokument495 SeitenExcel de Bienes Sin Codigos 2021 para Inventario (3) 20.01.2022OB ManuelNoch keine Bewertungen
- Cómo funciona un pendrive: Guía completaDokument13 SeitenCómo funciona un pendrive: Guía completaNilda Jose Martinez VasquezNoch keine Bewertungen
- Trabajo InformaticaDokument16 SeitenTrabajo InformaticaKeily RojasNoch keine Bewertungen
- Capa de Red: Introducción Al Enrutamiento Interno de AS en Internet OSPF (Open Shortest Path First)Dokument16 SeitenCapa de Red: Introducción Al Enrutamiento Interno de AS en Internet OSPF (Open Shortest Path First)xX-CROMA69-XxNoch keine Bewertungen
- Manual Linux Practico PERSONALDokument43 SeitenManual Linux Practico PERSONALWalter ValienteNoch keine Bewertungen
- 【Para S9series】 Problemas comunes indicados por el registro del kernel del minero y formas de resolverlos - Soporte de BitmainDokument7 Seiten【Para S9series】 Problemas comunes indicados por el registro del kernel del minero y formas de resolverlos - Soporte de BitmaineguzmanNoch keine Bewertungen
- Ont An5506 04 Fs ManualDokument2 SeitenOnt An5506 04 Fs ManualFRANZ JHOEL CORI ROJASNoch keine Bewertungen
- HD Omni GuideDokument70 SeitenHD Omni GuidedatttNoch keine Bewertungen
- Gestión de Servicios - ProcedimientoDokument16 SeitenGestión de Servicios - ProcedimientoJuan SanchezNoch keine Bewertungen
- Proyecto Final de PLCDokument12 SeitenProyecto Final de PLCDufi TobiNoch keine Bewertungen
- 4.3.3.4 Lab - Configure HSRPDokument8 Seiten4.3.3.4 Lab - Configure HSRPJuan Carlos BolivarNoch keine Bewertungen
- Redes Sna y MapDokument10 SeitenRedes Sna y Mapmariafernanda1992Noch keine Bewertungen
- Consejos de Reparación de Televisores LCDDokument6 SeitenConsejos de Reparación de Televisores LCDJuan Carlos RNoch keine Bewertungen
- PHP Es Un Lenguaje de Programación InterpretadoDokument14 SeitenPHP Es Un Lenguaje de Programación InterpretadoKevin Robin Salazar RiosNoch keine Bewertungen
- Orient DBDokument3 SeitenOrient DBmanfredjosueNoch keine Bewertungen
- Catálogo - Tecno Avance - SeptiembreDokument101 SeitenCatálogo - Tecno Avance - SeptiembreOscar FloresNoch keine Bewertungen
- Lab PCMDokument4 SeitenLab PCMCristian Danny RamirezNoch keine Bewertungen
- Manual de instrucciones HD TV 42 PlasmaDokument40 SeitenManual de instrucciones HD TV 42 PlasmachoneroNoch keine Bewertungen
- Tabla Comparacion Comandos Sistemas OperativosDokument12 SeitenTabla Comparacion Comandos Sistemas Operativosaltagracia0% (1)
- GersoDokument11 SeitenGersoramiro1ecvictorlevanNoch keine Bewertungen
- Practica P1S1 SQLite IntroDokument11 SeitenPractica P1S1 SQLite IntroBobby ZetaNoch keine Bewertungen
- Preinforme 3Dokument12 SeitenPreinforme 3Wilmer OscoNoch keine Bewertungen
- Ejemplo de Clases en C++Dokument10 SeitenEjemplo de Clases en C++ruperana100% (12)