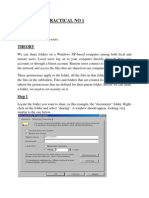
Das könnte Ihnen auch gefallen
- B TreesDokument6 SeitenB TreesthskumarNoch keine Bewertungen
- B TreeDokument63 SeitenB Treesummit rajNoch keine Bewertungen
- B-Trees: Balanced Tree Data Structures for Large Data SetsDokument10 SeitenB-Trees: Balanced Tree Data Structures for Large Data Setsarun10y07Noch keine Bewertungen
- EVALUATING JAVASCRIPT CALL GRAPH ALGORITHMSDokument76 SeitenEVALUATING JAVASCRIPT CALL GRAPH ALGORITHMSJorryt DijkstraNoch keine Bewertungen
- Trees: - Linear Access Time of Linked Lists Is ProhibitiveDokument156 SeitenTrees: - Linear Access Time of Linked Lists Is ProhibitiveRoshani ShettyNoch keine Bewertungen
- FS Lab Mini Project Placement StatisticsDokument44 SeitenFS Lab Mini Project Placement StatisticsTripti kumariNoch keine Bewertungen
- File Structures UNIT 1 NotesDokument13 SeitenFile Structures UNIT 1 NotesVadiraja Acharya50% (2)
- Final Exam - Design and Analysis of Algorithms - Fall 2010 Semester - SolDokument7 SeitenFinal Exam - Design and Analysis of Algorithms - Fall 2010 Semester - SolAbdul RaufNoch keine Bewertungen
- Database Recovery TechniquesDokument37 SeitenDatabase Recovery TechniquesabcNoch keine Bewertungen
- Computer Organization and Architecture MCQ14Dokument2 SeitenComputer Organization and Architecture MCQ14Kuldeep KushwahaNoch keine Bewertungen
- DBMS Record Database DesignDokument144 SeitenDBMS Record Database DesignAamerNoch keine Bewertungen
- OS - 2mark and 16 Mark (Unit-IV)Dokument6 SeitenOS - 2mark and 16 Mark (Unit-IV)Kartheeban KamatchiNoch keine Bewertungen
- CS218-Data Structures Final ExamDokument7 SeitenCS218-Data Structures Final ExamRafayGhafoorNoch keine Bewertungen
- CSCI 4717 Memory Hierarchy and Cache QuizDokument3 SeitenCSCI 4717 Memory Hierarchy and Cache QuizNeha SharmaNoch keine Bewertungen
- Cs403 Finalterm Subjective by MoaazDokument30 SeitenCs403 Finalterm Subjective by MoaazMuhammad Awais100% (1)
- MCA 312 Design&Analysis of Algorithm QuestionBankDokument7 SeitenMCA 312 Design&Analysis of Algorithm QuestionBanknbprNoch keine Bewertungen
- Relational Algebra and Calculus Multiple Choice QuestionsDokument5 SeitenRelational Algebra and Calculus Multiple Choice QuestionsMoses SsesangaNoch keine Bewertungen
- DBMS-Question and Answer Bank - SOCET-CE-Department - 211127 - 223259Dokument81 SeitenDBMS-Question and Answer Bank - SOCET-CE-Department - 211127 - 223259Dhruv ShahNoch keine Bewertungen
- Practice Questions of CPP - Multiple InheritanceDokument6 SeitenPractice Questions of CPP - Multiple InheritanceShubham KumarNoch keine Bewertungen
- Purpose of Language ProcessorsDokument7 SeitenPurpose of Language Processorsall4downloads100% (2)
- Advance Computer Architecture - CS501 Spring 2013 QuizDokument4 SeitenAdvance Computer Architecture - CS501 Spring 2013 QuizAkram KhanNoch keine Bewertungen
- Asessments POS N FictionDokument3 SeitenAsessments POS N FictionmmhenriNoch keine Bewertungen
- MC0080 Analysis and Design of AlgorithmsDokument15 SeitenMC0080 Analysis and Design of AlgorithmsGaurav Singh JantwalNoch keine Bewertungen
- Compare speeds, volatility, access methods, portability and costs of storage devicesDokument2 SeitenCompare speeds, volatility, access methods, portability and costs of storage devicesstarlite564Noch keine Bewertungen
- CS8603 Distributed SystemsDokument11 SeitenCS8603 Distributed SystemsMohammad Bilal - Asst. Prof, Dept. of CSENoch keine Bewertungen
- Quiz AssignmentDokument7 SeitenQuiz Assignmentprateek100% (1)
- MIS MCQ SolvedDokument9 SeitenMIS MCQ Solvedshamzan100% (1)
- Component and Deployment Diagrams ExplainedDokument16 SeitenComponent and Deployment Diagrams ExplainedShakeel Iqbal MohdNoch keine Bewertungen
- SQL MCQ - Entity Relationship Model QuestionsDokument7 SeitenSQL MCQ - Entity Relationship Model QuestionsWaqar Hassan100% (1)
- P131 CMP506Dokument2 SeitenP131 CMP506Akshay Ambarte0% (1)
- Advanced Cluster Analysis: Clustering High-Dimensional DataDokument49 SeitenAdvanced Cluster Analysis: Clustering High-Dimensional DataPriyanka BhardwajNoch keine Bewertungen
- InfoTech Site Solved MCQ of Database Management System (DBMDokument2 SeitenInfoTech Site Solved MCQ of Database Management System (DBMmanoj24983Noch keine Bewertungen
- DS IMP Questions Module WiseDokument7 SeitenDS IMP Questions Module WiseBhuvan S M100% (1)
- Compiler Design Notes (UNIT 4 & 5)Dokument16 SeitenCompiler Design Notes (UNIT 4 & 5)PritamGupta100% (2)
- Computer Science Mcqs TestDokument70 SeitenComputer Science Mcqs TestAman AlviNoch keine Bewertungen
- Java InterfaceDokument14 SeitenJava InterfaceSR ChaudharyNoch keine Bewertungen
- Bput CoaDokument2 SeitenBput CoaANIKET SAHOONoch keine Bewertungen
- Algorithms For Parallel MachinesDokument7 SeitenAlgorithms For Parallel Machinesshinde_jayesh2005Noch keine Bewertungen
- Dynamic HashingDokument35 SeitenDynamic Hashingsreenu_pesNoch keine Bewertungen
- Learn UNIX and Shell Programming with this guideDokument161 SeitenLearn UNIX and Shell Programming with this guideShaik AdiNoch keine Bewertungen
- Artifact - Diagrams - 5th UnitDokument3 SeitenArtifact - Diagrams - 5th UnitSharma JoshiNoch keine Bewertungen
- Lab Manual 10 PDFDokument4 SeitenLab Manual 10 PDFShahid ZikriaNoch keine Bewertungen
- OOPs in C++ UNIT-IDokument135 SeitenOOPs in C++ UNIT-IAnanya Gupta0% (1)
- Breadth-First Search - Wikipedia, The Free EncyclopediaDokument3 SeitenBreadth-First Search - Wikipedia, The Free EncyclopediaSourav DasNoch keine Bewertungen
- Unit 6 PDFDokument31 SeitenUnit 6 PDFTarun ReddyNoch keine Bewertungen
- Database Security Lab ManualDokument65 SeitenDatabase Security Lab ManualAkhilesh [MAVIS] PokaleNoch keine Bewertungen
- Tutorial Sheets of Data StructureDokument10 SeitenTutorial Sheets of Data StructureAnupmaSangwanNoch keine Bewertungen
- Raw SocketsDokument2 SeitenRaw SocketsmanjunathbhattNoch keine Bewertungen
- Ab Initio OverviewDokument4 SeitenAb Initio OverviewKulbir Minhas100% (3)
- Assignment - IC Binary Trees SolutionsDokument34 SeitenAssignment - IC Binary Trees SolutionsDrKrishna Priya ChakireddyNoch keine Bewertungen
- Practice Exercises: Doctype Element Element Element Element Pcdata PcdataDokument2 SeitenPractice Exercises: Doctype Element Element Element Element Pcdata PcdataDivyanshu BoseNoch keine Bewertungen
- Interview Questions in AutomataDokument7 SeitenInterview Questions in AutomataShuchita MishraNoch keine Bewertungen
- Computer Network Practical FileDokument31 SeitenComputer Network Practical FileAbhishek JainNoch keine Bewertungen
- LAB - 03 (Static Variables, Methods, and Blocks, Object As Parameter, Wrapper Classes) PDFDokument14 SeitenLAB - 03 (Static Variables, Methods, and Blocks, Object As Parameter, Wrapper Classes) PDFgreen goblinNoch keine Bewertungen
- Unit-2 (Btree InsertionDelection)Dokument4 SeitenUnit-2 (Btree InsertionDelection)Aa ANoch keine Bewertungen
- B-Trees: Balanced Tree Data Structures Optimized for Disk AccessDokument0 SeitenB-Trees: Balanced Tree Data Structures Optimized for Disk Accessbaluchandrashekar2008Noch keine Bewertungen
- CS2606: Data Structures and Object-Oriented Development Chapter 10: IndexingDokument25 SeitenCS2606: Data Structures and Object-Oriented Development Chapter 10: Indexinganon_484100541Noch keine Bewertungen
- B+ Tree IndexingDokument22 SeitenB+ Tree Indexingimtiazahmedfahim87Noch keine Bewertungen
- Data Structures: 2-3 Trees, B Trees, TRIE TreesDokument41 SeitenData Structures: 2-3 Trees, B Trees, TRIE TreesCojocaru IonutNoch keine Bewertungen
- CSE 301 Lecture-8-Indexing WTDokument31 SeitenCSE 301 Lecture-8-Indexing WTrafi siddiqueNoch keine Bewertungen
- PDFDokument9 SeitenPDFsudhialamandaNoch keine Bewertungen
- PDFDokument7 SeitenPDFsudhialamandaNoch keine Bewertungen
- 06213714Dokument14 Seiten06213714sudhialamandaNoch keine Bewertungen
- Applied Energy: Duong Quoc Hung, N. Mithulananthan, R.C. BansalDokument11 SeitenApplied Energy: Duong Quoc Hung, N. Mithulananthan, R.C. BansalsudhialamandaNoch keine Bewertungen
- Great Dictator MaterialsDokument9 SeitenGreat Dictator MaterialssudhialamandaNoch keine Bewertungen
- Optimal Capacitor Placement in A Radial Distribution System Using Shuffled Frog Leaping and Particle Swarm Optimization AlgorithmsDokument5 SeitenOptimal Capacitor Placement in A Radial Distribution System Using Shuffled Frog Leaping and Particle Swarm Optimization AlgorithmsIDESNoch keine Bewertungen
- 2CSC420004B0201 - RCDs EN PDFDokument80 Seiten2CSC420004B0201 - RCDs EN PDFmanoledan81Noch keine Bewertungen
- 00119248Dokument8 Seiten00119248sudhialamandaNoch keine Bewertungen
- Print PDFDokument6 SeitenPrint PDFsudhialamandaNoch keine Bewertungen
- (IEEE33) Network Reconfiguration in Distribution Systems For Loss Reduction and Load BalancingDokument7 Seiten(IEEE33) Network Reconfiguration in Distribution Systems For Loss Reduction and Load BalancingSudheerKumarNoch keine Bewertungen
- Utilizing SVC For Transient Stability Enhancement: ELEKTROENERGETIKA, Roč.6, č.2, 2013Dokument3 SeitenUtilizing SVC For Transient Stability Enhancement: ELEKTROENERGETIKA, Roč.6, č.2, 2013sudhialamandaNoch keine Bewertungen
- IntDokument2 SeitenIntsudhialamandaNoch keine Bewertungen
- MagNet Trial Edition-IntroductionDokument137 SeitenMagNet Trial Edition-IntroductionsudhialamandaNoch keine Bewertungen
- 1 JLK LiuuykDokument100 Seiten1 JLK LiuuyksudhialamandaNoch keine Bewertungen
- Relay SettingDokument17 SeitenRelay SettingFuat BolatNoch keine Bewertungen
- IntDokument2 SeitenIntsudhialamandaNoch keine Bewertungen
- 2012 03 PHD DavoudiDokument142 Seiten2012 03 PHD DavoudisudhialamandaNoch keine Bewertungen
- A Note On Study On The Transfer Functions For Detecting Windings Displacement of Power Transformers With Impulse MethodDokument1 SeiteA Note On Study On The Transfer Functions For Detecting Windings Displacement of Power Transformers With Impulse MethodsudhialamandaNoch keine Bewertungen
- 1 s2.0 S0378779611002239 MainDokument7 Seiten1 s2.0 S0378779611002239 MainsudhialamandaNoch keine Bewertungen
- Modified Particle Swarm Optimizers and Their ApplicationsDokument168 SeitenModified Particle Swarm Optimizers and Their ApplicationssudhialamandaNoch keine Bewertungen
- Appendix B: An Example of Back-Propagation Algorithm: November 2011Dokument4 SeitenAppendix B: An Example of Back-Propagation Algorithm: November 2011sudhialamandaNoch keine Bewertungen
- 9.power SystemsDokument16 Seiten9.power SystemsLalit NegiNoch keine Bewertungen
- Analysis PSO AlgorithmDokument5 SeitenAnalysis PSO AlgorithmzoranmiskovicNoch keine Bewertungen
- Genetic Programming On The Programming of Computers by Means of Natural Selection - John RDokument609 SeitenGenetic Programming On The Programming of Computers by Means of Natural Selection - John Rapi-3720602100% (3)
- Guidelines Happy Life Guide PDFDokument20 SeitenGuidelines Happy Life Guide PDFsudhialamandaNoch keine Bewertungen
- EED-M.Tech Pse PDFDokument8 SeitenEED-M.Tech Pse PDFsudhialamandaNoch keine Bewertungen
- Solving Quadratic Equations using Genetic AlgorithmDokument4 SeitenSolving Quadratic Equations using Genetic AlgorithmsudhialamandaNoch keine Bewertungen
- Power System Controle and StabilityDokument237 SeitenPower System Controle and Stabilitydigiloko100% (1)
- Engineering Mathematics SyllabusDokument2 SeitenEngineering Mathematics Syllabusrjpatil19Noch keine Bewertungen
- ScoreCardV2 PDFDokument2 SeitenScoreCardV2 PDFsudhialamandaNoch keine Bewertungen
- Asphalt General SpecDokument39 SeitenAsphalt General SpecUtpal MondalNoch keine Bewertungen
- Titanium Book From Org PDFDokument45 SeitenTitanium Book From Org PDFSuthirak SumranNoch keine Bewertungen
- In-Sight 7600/7800 Series Vision System: ManualDokument92 SeitenIn-Sight 7600/7800 Series Vision System: Manualjulio perezNoch keine Bewertungen
- Kinetics P.1 and P.2 SL IB Questions PracticeDokument22 SeitenKinetics P.1 and P.2 SL IB Questions Practice2018dgscmtNoch keine Bewertungen
- Ice 3Dokument9 SeitenIce 3Gabriel CortesNoch keine Bewertungen
- Greater Bangalore: Emerging Urban Heat Island: January 2010Dokument17 SeitenGreater Bangalore: Emerging Urban Heat Island: January 2010Rohan ChauguleNoch keine Bewertungen
- CH-7 System of Particles and Rotaional MotionDokument9 SeitenCH-7 System of Particles and Rotaional MotionMithul VPNoch keine Bewertungen
- Preparation and Characterization of Tin Oxide Based Transparent Conducting Coating For Solar Cell ApplicationDokument5 SeitenPreparation and Characterization of Tin Oxide Based Transparent Conducting Coating For Solar Cell Applicationcrypto fanbabyNoch keine Bewertungen
- Io ListDokument122 SeitenIo ListCahyanti Dwi WinartiNoch keine Bewertungen
- IR LM100A Crawlair Drill PDFDokument8 SeitenIR LM100A Crawlair Drill PDFAnonymous 8yIptglHhNoch keine Bewertungen
- 232 SpdaDokument4 Seiten232 SpdaGerard Sierr BarboNoch keine Bewertungen
- Vacon OPTE9 Dual Port Ethernet Board Manual DPD01583E UKDokument220 SeitenVacon OPTE9 Dual Port Ethernet Board Manual DPD01583E UKHa NguyenNoch keine Bewertungen
- T238 Digital Trigger UnitDokument5 SeitenT238 Digital Trigger UnitGuilherme SousaNoch keine Bewertungen
- Evolution of Mobile Base Station ArchitecturesDokument6 SeitenEvolution of Mobile Base Station ArchitecturesShivganesh SomasundaramNoch keine Bewertungen
- MP2.1 - Rankine CycleDokument12 SeitenMP2.1 - Rankine CycleRuhan Guo0% (1)
- Schlenk Line Techniques: Liquid NDokument15 SeitenSchlenk Line Techniques: Liquid NMarinoChavarroCordobaNoch keine Bewertungen
- Pipe Rack Load CalculationDokument3 SeitenPipe Rack Load CalculationKrunalpanchalNoch keine Bewertungen
- Description of The Courses - Transportation Eng - 2013 v2 PDFDokument5 SeitenDescription of The Courses - Transportation Eng - 2013 v2 PDFVinoth KumarNoch keine Bewertungen
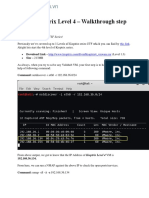
- CTF - Kioptrix Level 4 - Walkthrough Step by Step: @hackermuxam - Edu.vnDokument12 SeitenCTF - Kioptrix Level 4 - Walkthrough Step by Step: @hackermuxam - Edu.vnNguyenDucNoch keine Bewertungen
- TechRef ShuntDokument32 SeitenTechRef ShuntAlexNoch keine Bewertungen
- Azenabor - Oruka's Philosophic SagacityDokument18 SeitenAzenabor - Oruka's Philosophic SagacityestifanostzNoch keine Bewertungen
- Einstein's Discoveries Paved the WayDokument3 SeitenEinstein's Discoveries Paved the WayAyman Ahmed CheemaNoch keine Bewertungen
- Signal TransmissionDokument25 SeitenSignal TransmissionKumbati SupertiksNoch keine Bewertungen
- Mathematical Formulation of Physicochemical ProblemsDokument23 SeitenMathematical Formulation of Physicochemical ProblemsDea Puspa Karinda 02211940000031Noch keine Bewertungen
- DrillDokument18 SeitenDrillvivekNoch keine Bewertungen
- 4th Quarter Science 9 Impulse and MomentumDokument45 Seiten4th Quarter Science 9 Impulse and MomentumApple SamoyNoch keine Bewertungen
- Presentation GLDokument18 SeitenPresentation GLAris NurrochmanNoch keine Bewertungen
- Decision Analysis in Quantitative Decision MakingDokument14 SeitenDecision Analysis in Quantitative Decision MakingReader92% (13)
- RFPO55 G.8263: SpecificationsDokument5 SeitenRFPO55 G.8263: SpecificationsullascsNoch keine Bewertungen
- CKY) Cocke-Kasami-Younger) Earley Parsing Algorithms: Dor AltshulerDokument81 SeitenCKY) Cocke-Kasami-Younger) Earley Parsing Algorithms: Dor AltshulerViorel BotnariNoch keine Bewertungen