Das könnte Ihnen auch gefallen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1091)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- NumericalMethods GDokument39 SeitenNumericalMethods GdwightNoch keine Bewertungen
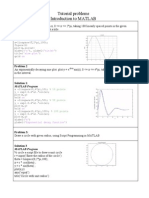
- 6 MatLab Tutorial ProblemsDokument27 Seiten6 MatLab Tutorial Problemsabhijeet834uNoch keine Bewertungen
- A Practical Guide To SplinesDokument366 SeitenA Practical Guide To SplinesAdam Campbell100% (6)
- Spline Functions Basic Theory: CambridgeDokument5 SeitenSpline Functions Basic Theory: CambridgeNasrin DorrehNoch keine Bewertungen
- Assignment 2 NewDokument5 SeitenAssignment 2 NewNasrin DorrehNoch keine Bewertungen
- 4 - Face RecognitionDokument8 Seiten4 - Face RecognitionNasrin DorrehNoch keine Bewertungen
- A Problem in Enumerating Extreme PointsDokument9 SeitenA Problem in Enumerating Extreme PointsNasrin DorrehNoch keine Bewertungen
- NMDokument12 SeitenNMShravan KumarNoch keine Bewertungen
- CBNST, 5Dokument3 SeitenCBNST, 5Amit JuyalNoch keine Bewertungen
- InterpolationDokument79 SeitenInterpolationNatassa Adi PutriNoch keine Bewertungen
- (Cornelius Lanczos) Linear Differential OperatorsDokument582 Seiten(Cornelius Lanczos) Linear Differential Operatorsmichel.walz01Noch keine Bewertungen
- Lagrange InterpolationDokument3 SeitenLagrange Interpolationanis anisNoch keine Bewertungen
- InterpolationDokument5 SeitenInterpolationMengistu AbebeNoch keine Bewertungen
- Unit IiDokument21 SeitenUnit IiRobertBellarmineNoch keine Bewertungen
- Numerical Methods in Structural Engineering (Ce60125) :computer Assignment 1Dokument7 SeitenNumerical Methods in Structural Engineering (Ce60125) :computer Assignment 1Anonymous QjMkRPqjNoch keine Bewertungen
- Group - 5 Laboratory 4Dokument22 SeitenGroup - 5 Laboratory 4Jerome Mateo Tuble Jr.Noch keine Bewertungen
- Final Quiz 1 - Attempt Review 2Dokument4 SeitenFinal Quiz 1 - Attempt Review 2Erick GarciaNoch keine Bewertungen
- Interpolation (Part I) : Simon Fraser University - Surrey Campus MACM 316 - Spring 2005 Instructor: Ha LeDokument31 SeitenInterpolation (Part I) : Simon Fraser University - Surrey Campus MACM 316 - Spring 2005 Instructor: Ha LeAli RazaNoch keine Bewertungen
- R5100306-Computer Programming & Numerical MethodsDokument1 SeiteR5100306-Computer Programming & Numerical MethodssivabharathamurthyNoch keine Bewertungen
- Tabel SeismologiDokument168 SeitenTabel SeismologiImam FaisalNoch keine Bewertungen
- Numerical Methods Formula SheetDokument1 SeiteNumerical Methods Formula Sheetfake7083100% (1)
- Curse NGDokument464 SeitenCurse NGRadu TrimbitasNoch keine Bewertungen
- Chapter FourDokument11 SeitenChapter FourHanan Shayibo100% (1)
- Chapter 19 Numerical Differentiation: Taylor Polynomials Lagrange InterpolationDokument29 SeitenChapter 19 Numerical Differentiation: Taylor Polynomials Lagrange InterpolationAnonymous 1VhXp1Noch keine Bewertungen
- DEM4110 - Interpolation and Extrapolation - 2021Dokument74 SeitenDEM4110 - Interpolation and Extrapolation - 2021henriettamunakombwe8Noch keine Bewertungen
- The Spectral-Element Method: Introduction: Heiner IgelDokument67 SeitenThe Spectral-Element Method: Introduction: Heiner IgeljukaNoch keine Bewertungen
- 1 Polynomial Approximation and Interpolation: 1.1 Jackson TheoremsDokument11 Seiten1 Polynomial Approximation and Interpolation: 1.1 Jackson TheoremsAurangZaib LaghariNoch keine Bewertungen
- Chapter 3 - Interpolation Curve Fitting With TutorialsDokument25 SeitenChapter 3 - Interpolation Curve Fitting With TutorialsZac StylesNoch keine Bewertungen
- Numerical Methods LAB: Lagrange InterpolationDokument21 SeitenNumerical Methods LAB: Lagrange InterpolationHumaish KhanNoch keine Bewertungen
- Interpolation: ApproximationDokument13 SeitenInterpolation: ApproximationElena DamocNoch keine Bewertungen
- Inte o Ation An Po Omia RoximationDokument18 SeitenInte o Ation An Po Omia RoximationMattia Silva ValsangiacomoNoch keine Bewertungen
- Curve-Fitting and InterpolationDokument16 SeitenCurve-Fitting and InterpolationZafar IqbalNoch keine Bewertungen
- Mcse 004Dokument15 SeitenMcse 004Vishal Gupta0% (1)
- Computer Project # 1 - Interpolation, Differentiation and IntegrationDokument1 SeiteComputer Project # 1 - Interpolation, Differentiation and IntegrationKetan RsNoch keine Bewertungen