Beruflich Dokumente
Kultur Dokumente
Universidad de Costa Rica Facultad de Ingeniería Escuela de Ingeniería Eléctrica
Hochgeladen von
salmo83:18Originaltitel
Copyright
Verfügbare Formate
Dieses Dokument teilen
Dokument teilen oder einbetten
Stufen Sie dieses Dokument als nützlich ein?
Sind diese Inhalte unangemessen?
Dieses Dokument meldenCopyright:
Verfügbare Formate
Universidad de Costa Rica Facultad de Ingeniería Escuela de Ingeniería Eléctrica
Hochgeladen von
salmo83:18Copyright:
Verfügbare Formate
Universidad de Costa Rica Facultad de Ingeniera Escuela de Ingeniera Elctrica
IE 0502 Proyecto Elctrico
Diseo de un sumador digital de 32 bits para circuitos integrados.
Por: Carlos Duarte Martnez
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
ii
Diseo de un sumador digital de 32 bits para circuitos integrados. Por: Carlos Duarte Martnez.
Sometido a la Escuela de Ingeniera Elctrica de la Facultad de Ingeniera de la Universidad de Costa Rica como requisito parcial para optar por el grado de: BACHILLER EN INGENIERA ELCTRICA Aprobado por el Tribunal:
___________________ Ing. Federico Ruiz. Profesor Gua ___________________ Ing. Roberto Senz Fallas. Profesor Lector ___________________ Ing. Mauricio Muoz Castro Profesor Lector
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
iii
AGRADECIMIENTOS. A Dios, A Kattia, A mi familia. Por toda la paciencia.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
iv
RECONOCIMIENTOS Al LADS-DE por lo que nos cost aprender lo que aqu tan fcil se escribe.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
NDICE GENERAL
NDICE DE FIGURAS.................................................................................... vi NDICE DE TABLAS.................................................................................... viii NOMENCLATURA........................................................................................ ix RESUMEN ...................................................................................................... xi CAPTULO 1: Introduccin.............................................................................1
1.1 1.2 Justificacin. ....................................................................................................................1 Objetivos ..........................................................................................................................1 1.2.1 Objetivos especficos ...............................................................................................1 1.3 Metodologa .....................................................................................................................2
CAPTULO 2: Desarrollo terico.....................................................................4
2.1 Las grandes familias de sumadores digitales:..................................................................4 2.1.1 Estructuras comnmente asociadas a los sumadores. ...................................................13 2.1.2 Criterios de escogencia. ................................................................................................13
CAPTULO 3: Escogencia de la arquitectura apropiada. .............................. 14
3.1 Limitantes del diseo. .............................................................................................................. 14 3.2 Comparacin de las opciones disponibles. .............................................................................. 16
CAPTULO 4: Diseo del sumador escogido y anlisis de resultados............ 34
4.1 Simulacin lgica. .................................................................................................................... 34 4.1.1 Verificacin del modelo...............................................................................................40 4.2 Modelado lgico esquemtico. ................................................................................................ 42 4.3 Modelo de polgonos para plano fsico. ................................................................................... 50 4.4 Anlisis de resultados. ............................................................................................................. 57
CAPTULO 5: Conclusiones y recomendaciones ........................................... 63
5.1 Conclusiones. ........................................................................................................................... 63 5.2 Recomendaciones: ................................................................................................................... 66
BIBLIOGRAFA............................................................................................ 68 ANEXOS ........................................................................................................ 69
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
vi
NDICE DE FIGURAS Figura 2.1: Sumador genrico de prediccin de acarreo. .............................................................8 Figura 2.2: Bloque predictor de acarreo. ...................................................................................10 Figura 2.3: Topologa de la solucin recurrente. .......................................................................12 Figura 3.1: Sumador completo de 1 bit. .....................................................................................18 Figura 3.2: Diagrama de bloques de un sumador de acarreo guardado. ....................................19 Figura 3.3: acarreo por nodo interno. .........................................................................................20 Figura 3.4: Compuerta O-exclusiva con transistores de paso. ...................................................22 Figura 3.5: Sumador completo por compuertas de paso. ...........................................................23 Figura 3.6: Diagrama simplificado del sumador por compuertas de paso. ................................24 Figura 3.7: diagrama de bloques del sumador de salto de acarreo. ...........................................25 Figura 3.8: Diagrama de bloques del rbol de prediccin de acarreo. .......................................28 Figura 3.9: Grafos de sumadores regulares por solucin recurrente: ........................................30 Figura 3.10: Grafos de un predictor de acarreo en raz creciente en potencias de 2. ................32 Figura 4.1: Sumador completo de 1 bit:.....................................................................................43 Figura 4.2: Sumador completo de 1 bit con propagado de acarreo: ..........................................44 Figura 4.3: Smbolo del sumador completo de 1 bit y conexin de 4. ......................................45 Figura 4.4: Smbolo del bloque de suma de 4 bits. ....................................................................46 Figura 4.5: Alambrado de los bloques 1 y 2 en el diagrama final. ............................................47 Figura 4.6: Diagrama esquemtico completo de l sumador de 32 bits. ......................................48 Figura 4.7: Imagen del simulador esquemtico en funcionamiento. .........................................50 Figura 4.8: Plano fsico del sumador de 1 bit con generacin de propagado. ...........................51 Figura 4.9: Plano fsico del sumador de 1 con interconexin hecha a mano. ............................52 Figura 4.10: grupo de 4 interconectado. ....................................................................................53 Figura 4.11: Bloque de 4 bits con salto de acarreo y selector de acarreo entrando mejorado por interconexin. .............................................................................................................................54 Figura 4.12: Sumador de 8 bits con lgica de salto de acarreo. .................................................55 Figura 4.13: sumador completo de 32bits y sus dimensiones finales. .......................................56
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
vii
Figura 4.14: Diagrama de tiempos del sumador de 1 bit con generador de propagado. ............58 Figura 4.15: Diagrama de tiempos del sumador de 1 bit con generador de propagado e interconexiones manuales. .........................................................................................................59 Figura 4.16: Diagrama de tiempos del sumador de 4 bits: ........................................................60 Figura 4.17: Diagrama de tiempos del bloque de 8 bits propagando acarreo de la posicin cero a la suma de la posicin siete. ....................................................................................................61 Figura 4.18: Diagrama de tiempos de los acarreos generados por salto, por ltima entrada de cada bloque de 4 y suma de la posicin 31. ...............................................................................62
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
viii
NDICE DE TABLAS Tabla 2.1: Tabla de verdad del sumador de 1 bit.........................................................................4 Tabla 4.1: Columna de clculo correspondiente al sumador completo de 1 bit. .......................34 Tabla 4.2: Dependencias del sumador de 1 bit: .........................................................................35 Tabla 4.3: Dependenc ias del sumador de 4 bits con propagacin de acarreo. ...........................35 Tabla 4.4: Sumador de 32 bits en simulacin lgica. ................................................................36 Tabla 4.5: Trazas de las dependencias de la sumatoria y acarreo de salida de la tajada 32, desde el prximo acarreo del bit 27. ..........................................................................................38 Tabla 4.6: Trazas de las dependencias de la sumatoria y acarreo de salida de la tajada 32, desde el cuarto bloque de 4 bits. ................................................................................................39 Tabla 4.7: Trazas de las dependencias de la sumatoria y acarreo de salida de la tajada 32, desde el acarreo entrando al bit 0...............................................................................................39 Tabla 4.8: Trazas de las dependencias de la sumatoria y acarreo de salida de la tajada 32, el primer bit de datos. .....................................................................................................................40 Tabla 4.9: Trazas de las dependen cias del acarreo de salida de la tajada 32 desde la 16. .........40 Tabla 4.10: Generador de vectores aleatorios y clculos de verificacin. .................................41 Tabla 4.11: Pantalla del comparador de sumas..........................................................................42 Tabla 4.12: Parmetros de simulacin. ......................................................................................49
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
ix
NOMENCLATURA A B ASICS Bit Byte C Cin Carry CARRY Co CPLD G Convencionalmente se adoptaron estos nombres como los datos de entrada a los circuitos. Circuitos integrados de aplicacin especfica (Siglas en Ingls). Unidad mnima de datos binarios. Conjunto de 8 bits. Convencionalmente se utiliza para denominar el acarreo entrando a un bloque lgico. Convencionalmente se usa para denominar al acarreo saliente de un bloque lgico.
Dispositivo lgico complejo programable (Siglas en Ingls). Convencionalmente se utiliza para denominar la seal de acarreo generado. Elemento secuencial biestable controlado por flanco. Primer nivel de metal en la construccin del circuito integrado. Segundo nivel de metal en la construccin del circuito integrado. Grupo de 4 bits. Transistor tipo N en fabricacin de silicio y xido de metal. Compuerta lgica, representa la suma booleana.
Latch M1 M2 Nibble N-mos O P
Convencionalmente se utiliza para denominar la seal de acarreo propagado. Arreglo lgico programable (Siglas en Ingls). Transistor tipo P en fabricacin de silicio y xido de metal. Convencionalmente se utilizan para denominar la seal de salida del
Agosto del 2004
PLA P-mos
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
S Sum Y Via
bloque de suma.
Compuerta lgica, representa el producto booleano. Pozo de metal en el proceso de fabricacin ruta vertical que conecta capas consecutivas de metal.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
xi
RESUMEN El presente reporte sintetiza el resultado de una investigacin prctica en circuitos digitales. La primera intencin de la labor que se desarroll fue la de disear un sumador digital de 32 bits para circuitos integrados, desde su concepcin terica hasta el dibujo y simulacin del modelo de ms bajo nivel que se pudiere alcanzar. En general ante la visin del desarrollo de la electrnica de consumo que requiere sistemas digitales eficientes y de bajo costo, se decidi simular el proceso de diseo de un bloque funcional especfico para un microprocesador. La metodologa que se decidi seguir, consisti en emular el proceso de diseo que por experiencia se conoce, de una empresa de diseo de microprocesadores del mercado costarricense. La tarea se separ en cuatro grandes etapas y cada una de stas se desarroll a modo de entregar una seccin del producto final y exponer la forma de dicha etapa del diseo. A lo largo de ste desarrollo, se investigaron las diferentes arquitecturas comunes de sumadores digitales. Se expuso una mtrica simple que intenta ayudar en la comparacin de estos sistemas. Se utilizaron esta mtrica y un grupo de premisas tericas para efectuar una escogencia conveniente respecto a la arquitectura que habra de implementarse. Seguido se generaron modelos lgicos conductuales, estructurales y de representacin fsica que se probaron y simularon para asegurar el correcto funcionamiento del circuito, y establecer sus caractersticas. Todo esto se conjug con un uso experimental de formas novedosas de simulacin y utilizacin de recursos puramente acadmicos. El trabaj concluy reafirmando una conviccin que incita a orientarse a los circuitos integrados artesanales siempre que el volumen de mercado lo permita. Aparte de a exposicin de una l metodologa de trabajo utilizada en la industria, se promueve un sistema de diseo un poco relegado por las metodologas de celdas estndar y dispositivos programables. Pero que en el fondo representa la verdadera ventaja competitiva comercial de las grandes empresas de semiconductores. Formalmente el documento consta de cinco captulos los cuales se separaron de esta manera: Introduccin, resea terica, escogencia de la arquitectura, elaboracin de los modelos y conclusiones. Parte integral de este reporte son los archivos que representan los modelos mencionados. Se recomienda al lector que recorra los modelos presentados en sus mltiples versiones, para que observe de primera mano el resultado que aqu se intent exponer.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
CAPTULO 1: Introduccin
1.1
Justificacin.
Ante la tendencia de las empresas manufactureras de electrnica de consumo; de integrar mayor capacidad de computacin en los dispositivos mviles. Las empresas tradicionales de microprocesadores han anunciado el desarrollo de versiones reducidas de sus procesadores de primera lnea; que intentan introducir al mercado de los aparatos de bolsillo. Estos sistemas proveen poder computacional de arquitectura IA-32 en sistemas simples como telfonos mviles y agendas electrnicas. En un segmento de mercado donde los circuitos integrados dominantes son sistemas sintticos en PLA CPLD, circuitos de muy alta integracin presentan una ventaja competitiva de costo y ambientes de desarrollo. Esto motiv el trabajo que en este documento se reporta. Se decidi replicar el proceso de diseo de un bloque funcional, utilizando herramientas acadmicas. Se intent tipificar ese proceso tan diferente de la programacin de circuitos de uso general para mostrar el esqueleto de las metodologas de diseo de microprocesadores. 1.2 Objetivos
Disear un sumador digital de 32 bits y describir sus modelos, hasta obtener un mapa en plano fsico cuyo funcionamiento pueda ser simulado. Recorrer el proceso de diseo en sus etapas generales tal y como se hace en la industria de los microprocesadores. Evaluar las herramientas acadmicas y la viabilidad de disear circuitos integrados artesanales.
1.2.1 Objetivos especficos Analizar las familias arquitectnicas comunes de sumadores digitales, comparar sus caractersticas fsicas y funcionales. Establecer criterios de comparacin de acuerdo a los requerimientos tericos del diseo. Dichos criterios han de utilizarse para escoger la arquitectura de suma conveniente. El sistema a escoger sera utilizado en un microprocesador planeado para productos mviles. Delimitar en etapas claras el proceso de diseo de un bloque funcional en un sistema en circuitos integrados. Tomando como ejemplo el proceso de alguna compaa de microprocesadores conocida.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
Desarrollar las etapas de diseo del sumador mostrando las herramientas involucradas y las simulaciones asociadas a cada modelo del mismo. Se decidi que este sistema habr de tener un importante componente artesanal en su elaboracin, para aprovechar al mximo los recursos que ofrece. Esta etapa tiene gran importancia, puesto que han de proponerse soluciones viables a los problemas de diseo. No solo en el circuito sino en la metodologa de diseo. Listar los rangos operativos del circuito diseado y sus caractersticas de acuerdo a la labor que en l se realizare. Y observar el retorno sobre inversin de alterar manualmente los polgonos en el silicio.
1.3 Metodologa El diseo de circuitos digitales puede a grandes rasgos describirse como la separacin de los componentes del sistema final en bloques de menor complejidad. Estos bloques, pueden agruparse en categoras bastante definidas. Siendo stas: Las celdas de entrada/salida, los elementos de memoria, las estructuras de control y los operadores de datos. A partir de estos grupos se especifican los sistemas que han de ejecutar estas funciones, luego se disean e implementan. El mdulo que en particular nos interesa es uno entre los operadores de datos, el sumador. La operacin de suma es bsica para muchos procesos lgicos comunes, el conteo, el incremento, la resta, la multiplicacin, divisin, y filtrado. Como resultado de esto el circuito digital que toma 2 operandos y calcula su suma se vuelve de gran importancia en el diseo de circuitos de alta integracin. Existe una gran variedad de implementaciones de un circuito sumador, cada una con su combinacin de ventajas y desventajas derivadas de las necesidades y limitaciones inherentes a todo diseo de alta integracin. rea, densidad velocidad, potencia, dificultad de sntesis y costo deben alcanzar un equilibrio. Todas las implementaciones de sumadores llevan consigo la consigna que rige el diseo de los operadores de datos; se desea que sean modulares, regulares, jerrquicos y locales. As cumplen con los principios del diseo estructurado.
Para la ejecucin del trabajo se defini el siguiente esquema: Se dividi el esfuerzo en dos reas principales. La primera fue la investigacin de las arquitect uras de sumadores comunes. Y su posterior comparacin. Esto permiti expandir el rango de posibilidades por las que se pudo inclinar el diseo. A la vez estableci las mtricas por las cuales la comparacin se llev a cabo. La recopilacin de esa informacin se expuso como teora necesaria. La segunda parte comprendi la creacin de los modelos que representan el circuito. Esta seccin en particular se estructur a modo de representar las diferentes etapas del diseo, cada una de las cuales gener un producto, el respectivo modelo. A cada etapa se asoci una herramienta especfica que ayud en la creacin del mismo y su simulacin. La parte que
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
concentr la mayor cantidad de esfuerzo fue la creacin y verificacin de los modelos. Y el producto de mayor importancia son los modelos funcionales y su comportamiento en simulacin. De acuerdo a la metodologa de diseo que generalmente se utiliza en Intel se definieron 3 pasos. Inicialmente al estar ya definida la arquitectura a utilizar, se cre un modelo lgico, el cual debi ser verificado en su funcionamiento. El segundo paso consisti en la generacin de un modelo esquemtico. Este modelo como paso intermedio permiti una simulacin de mayor precisin. A partir de este modelo, se utilizo la propiedad del Verilog generado automticamente para producir la tercera etapa. En la etapa final se generaron bloques constitutivos bsicos en modelo de polgonos. Estos se tomaron como constituyentes esenciales pero no fijos del sistema final. El modelo final en polgonos se dibuj a mano a partir de los bloques esenciales. Finalmente se corri una simulacin dinmica que ayudo a caracterizar su funcionamiento.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
CAPTULO 2: Desarrollo terico
2.1 Las grandes familias de sumadores digitales:
Los datos en un circuito digital se procesan en palabras de n bits usualmente normales, es decir, de un ancho definido. El ancho depende de la precisin que se desea obtener en el resultado. La palabra ms simple de procesar es la de 1 bit, en lo que se conoce como tajadas de 1 bit. La oportunidad que esto representa es muy importante. Todo el sistema puede construirse a partir de n tajadas de 1 bit. As el circuito crece ampliando el ancho de la palabra que puede manejar. Esta forma de disear concuerda con una realidad ineludible de los sistemas de procesamiento de datos. Las operaciones usualmente se agrupan en tiempo y espacio, ya sea por su secuencia lgica, o por la localizacin de las estructuras de ejecucin y almacenamiento. Por construccin la estructura de tajadas obliga al resto del diseo a reunir los pares de bits operandos. Siendo el sumador de 1 bit el ms simple de disear, se convierte este en la base lgica de la operacin de suma. La funcin lgica del sumador no se limita a tomar sus entradas y generar el resultado binario, para que el bloque sea funcional sus vectores de entradas y salidas son ms amplios. As el sistema bsico puede comunicar con sus bloques adyacentes toda la informacin pertinente a la operacin. Una tabla de verdad comnmente utilizada para sumadores de 1 bit es la que se muestra en la tabla 2.1:
Tabla 2.1: Tabla de verdad del sumador de 1 bit. C 0 0 0 0 1 1 1 1 A 0 0 1 1 0 0 1 1 B 0 1 0 1 0 1 0 1 A.B(G) 0 0 0 1 0 0 0 1 A+B(P) 0 1 1 1 0 1 1 1 A(+)B 0 1 1 0 1 1 1 0 S 0 1 1 0 1 0 0 1 CARRY 0 0 0 1 0 1 1 1
A y B son las entradas, C es la entrada de acarreo, S es el resultado de la suma que tomar en cuenta los 3 valores A, B y C. CARRY es el acarreo que la suma producira, G es la seal de acarreo generado, esta se da cuando el acarreo se produjo dentro en el sumador, P acarreo propagado se da cuando hay acarreo de entrada y salida, es decir, se pasa el acarreo de entrada a
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
la salida del sumador. En algunos casos se usa la O-exclusiva de A y B como P pues esta se puede utilizar para generar la suma. La forma ms sencilla de disear el sumador, es implementar las compuertas que puedan generar las funciones descritas por la tabla anterior de la cual se toma que: S = ABC + ABC + ABC + ABC S = A(+)B(+)C De igual forma: CARRY = AB + AC + BC CARRY = AB + C(A + B) (2.3) (2.4) (2.1) (2.2)
La implementacin por compuertas lgicas de ambas funciones formara nuestra tajada de 1 bit. Dicha implementacin no es nica, adems a nivel de transistor varios nodos internos de una configuracin XOR de 3 entradas resultaran redundantes. Nuestro sumador completo de 1 bit esta diseado de tal manera que puede conectarse con si mismo tantas veces como se desee. Esta es la estructura bsica conocida como sumador de propagacin de acarreo; el acarreo de salida de cada etapa se conecta al acarreo de entrada de la siguiente. La configuracin de todo sumador tiene como entradas esenciales la descritas en la tabla 2.1, lo cual nos lleva a hacer notar una de sus principales ventajas, el sumador y el restador son esencialmente iguales por construccin. La resta puede fcilmente ejecutarse invirtiendo una de las entradas y aplicando un acarreo de entrada al sumador. Esta simplicidad es importante puesto que nos muestra como la configuracin lgica de un circuito puede ser muy til si se aprovechan sus nodos internos. La cantidad de lgica necesaria para convertir un sumador en restador es pequea. Esto refuerza el concepto de circuitera reutilizable que se persigue siempre para aprovechar al mximo las estructuras fsicas. El sumador de acarreo propagado utiliza el mismo bloque de lgica n veces para producir su salida. Por construccin, cada bloque debe esperar el resultado del anterior para producir el propio de manera confiable. Se puede argumentar que no en todos los casos es realmente necesario esperar por el bloque anterior, pues este podra no generar acarreo alguno y por ende el resultado de esos bloques es correcto simultneamente. Pero es claro tambin que aprovechar esa realidad estadstica es imposible en un sumador de uso general de ancho de palabra superior a 2. Esto crea otro nivel de complicacin que pretende descubrir eso casos y aprovecharlos. Desde otro punto de vista en cambio, si se considera el peor caso del circuito, aquel en el que todo bloque ha de esperar por el resultado del anterior, otra aproximacin se hace evidente. El mismo bloque de lgica se utiliza n veces en una secuencia temporal consecutiva. Se est usando la misma funcin pero en un lugar y tiempo distinto cada vez. Por tanto se puede serializar completamente el sumador, utilizar un nico bloque de lgica, enmarcado en una mquina d e estados que le alimenta secuencialmente los pares correspondientes de sus vectores de entrada y
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
realimenta el acarreo. El resultado y las entradas utilizan registros de desplazamiento. Los registros han de ser de profundidad normalizada, de acuerdo al ancho de palabra que la mquina necesita. Como es de suponer la lgica de control se complica y crece a medida que la lgica de ejecucin se reduce. Este circuito nunca entregar un resultado antes de lo que lo habra hecho el peor caso del circuito de propagacin serial. Pero dependiendo del ancho de la palabra a operar, podra consumir un rea significativamente menor. Una caracterstica esencial del sumador de propagacin de acarreo es su tiempo de retardo, el cual depende de en cuantos bloques el acarreo debe atravesar. En muchos casos este tiempo se vuelve prohibitivo para los diseos, por lo que se desarroll otra familia de sumadores que intenta liberarse de la serialidad del acarreo propagado. El camino crtico es el que lleva de C a CARRY desde la entrada del bit menos significativo hasta el ms significativo. Acelerar la propagacin del acarreo a travs del sumador se logra por varios mtodos diferentes. Una arquitectura de sumador comn es la de acarreo saltado; donde se utilizan las seales de acarreo propagado de un grupo definido de bits. Si todas las seales P de un grupo de bits consecutivos son ciertas 1 lgicos, el acarreo entrando a dicho grupo puede saltrselo completo sin necesidad de recorrer todos los pasos de lgica intermedios. Esto puede describirse como: P = Pi . Pi+1 . Pi+2 . . Pi+k 1 (2.5)
La implementacin de acarreo saltado separa las palabras a operar en grupos de bits de igual tamao con k bits cada uno, dentro de cada grupo el acarreo recorre el circuito a la manera usual de acarreo propagado, adems un compuerta Y se utiliza para formar la seal de propagacin del grupo y saltarse todo el grupo hasta la entrada del siguiente. El retardo mximo de un sumador implementado de esta manera, se da cuando se genera un acarreo en la posicin menos significativa, recorre k posiciones del primer grupo salta en el -1 trayecto N/k-2 grupos en el medio y entra al ltimo bloque en su pareja k-1 y se asimila en la Nsima posicin para completar el resultado S. Esta forma de propaga r el acarreo es significativamente ms veloz que el acarreo propagado, pero requiere algunas modificaciones relativamente simples. El retraso an es linealmente dependiente del tamao de la palabra a operar pero se reduce a 1/k veces. Una mejora que resulta del anlisis de tiempos del sumador con salto de acarreo es el sumador de bloques variables. La intencin es reducir la latencia del camino crtico mas largo en el sumador de salto de acarreo. Esto no implica necesariamente que la complejidad deba aumentar. El primer y ltimo bloques se vuelven ms cortos y los bloques intermedios ms largos. Esto permite que el camino crtico que analizamos anteriormente, pueda saltar grupos ms largos en el medio, As tendr una generacin y propagacin ms rpida en los bloques donde su comportamiento es esencialmente el de un sumador de acarreo. Las consecuencias, a diferencia de lo poco complejo de los cambios, si son de importancia. La latencia total se reduce en comparacin al sumador de acarreo saltado y deja de tener una dependencia lineal con el tamao del sumador. El retraso
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
tomar una razn cuadrtica con respecto al largo de la palabra a operar. Para un sumador de ancho variable optimizado, es posible llegar a un tiempo de retardo que puede expresarse como: ? = C1 + v (C2 N + C3) (2.6)
El determinar los tamaos ptimos de los bloques, es un problema de programacin lineal. Si se resuelve de esta manera, no se obtiene una verdadera optimizacin. Si se utilizan tcnicas de programacin dinmica, este sumador puede sobrepasar a muchas otras clases de sumadores en lo que respecta a su velocidad. Los sumadores de prediccin de acarreo pretenden eliminar el problema de tener un aumento lineal del tiempo de retardo por la propagacin del acarreo. En un sumador de n bits de propagacin el tiempo seria n veces la latencia del clculo del bloque bsico, la idea de prever el acarreo intenta ejecutar el clculo en paralelo para cada etapa del sumador. Podemos expresar el acarreo del i-simo bloque como: Ci = Gi + Pi. Ci-1 Donde: Gi = Ai. Bi Pi = Ai. Bi Al expandir la ecuacin, resulta: Ci = Gi + Pi.Gi-1 + Pi.Pi-1.Gi-2 + + Pi P1C0. Y la suma es: Si = Ci (+) Ai (+) Bi (2.11) (2.10) (Acarreo generado.) (Acarreo propagado.) (2.8) (2.9) (2.7)
Como podemos ver, implementando Ci para cada etapa del sumador podramos volverlo completamente paralelo, pero las dimensiones de la circuitera son mucho mayores de lo que se desea. El nmero de estados de prediccin que se utiliza normalmente es de 4, los trminos para cada acarreo en la estructura de 4 son: C0 = G0 + P0Ci C1 = G1 + P1G0 + P1P0Ci C2 = G2 + P2G1 + P2P1G0 + P2P1P0Ci C3 = G3 + P3G2 + P3P2G1 + P3P2P1G0 + P3P2P1P0Ci (2.12) (2.13) (2.14) (2.15)
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
En la representacin de Weste Y Eshraghian [12] del bloque de prediccin de acarreo de 4 bits, la lgica de generacin de los trminos S, P y G rodean al bloque de generacin de acarreo que incluye las funciones descritas anteriormente. Esto se describe en la figura 2.1 y 2.2.
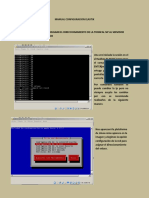
Figura 2.1: Sumador genrico de prediccin de acarreo. Esta es la llamada de Verilog correspondiente, se dise en Microwind y se genero a partir del esquemtico:
module predictor( b3,a3,b2,a2,a0,b0,a1,b1, Cin,sum0,sum1,sum2,sum3,C3); input b3,a3,b2,a2,a0,b0,a1,b1; input Cin; output sum0,sum1,sum2,sum3,C3; wire w26,w27,w28,w29,w30,w31,w32,w33; wire w34,w35,w36,w37,w38,w39,w40,w41; wire w42; and and2_2(w3,a3,b3) xor xor2_3(w4,b3,a3) and and2_4(w7,a2,b2) and and2_5(w10,a1,b1) and and2_6(w13,a0,b0)
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
xor xor2_7(w14,b2,a2) xor xor2_8(w15,b1,a1) xor xor2_9(w16,b0,a0) xor xor2_13(sum0,w16,Cin) xor xor2_14(sum3,w4,w19) xor xor2_15(sum2,w14,w21) xor xor2_16(sum1,w23,w15) and and2_1_long_pred_1_28(w26,w13,w15) and and3_2_long_pred_2_29(w27,w15,w16, Cin) or or3_3_long_pred_3_30(w21,w27,w26,w10) or or2_4_long_pred_4_31(w23,w13,w28) and and2_5_long_pred_5_32(w28,w16,Cin) and and2_6_long_pred_6_33(w31,w29,w30) and and2_7_long_pred_7_34(w30,w15,w14) and and2_8_long_pred_8_35(w29,Cin,w16) and and3_9 _long_pred_9_36(w32,w13,w15,w14) and and2_10_long_pred_10_37(w33,w14,w10) or or2_11_long_pred_11_38(w19,w34,w35) or or2_12_long_pred_12_39(w35,w33,w7) or or2_13_long_pred_13_40(w34,w31,w32) or or2_14_long_pred_14_41(C3,w36,w3) or or2_15_long_pred_15_42(w37,w13,w16) and and2_16_long_pred_16_43(w38,Cin,w37) and and2_17_long_pred_17_44(w39,w15,w38) or or2_18_long_pred_18_45(w40,w39,w10) and and2_19_long_pred_19_46(w41,w14,w40) or or2_20_long_pred_20_47(w42,w41,w7) and and2_21_long_pred_21_48(w36,w4,w42) or or2_23_long_pred_22_49(w23,w13,w28) and and2_24_long_pred_23_50(w28,w16,Cin) endmodule
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
10
Figura 2.2: Bloque predictor de acarreo. El cdigo correspondiente a este bloque representa las ecuaciones descritas anteriormente.
module long_pred( P3,G3,P2,G2,P1,G1,P0,G0, Ci,C3,C0,C1,C2); input P3,G3,P2,G2,P1,G1,P0,G0; input Ci; output C3,C0,C1,C2; and and2_1(w3,G0,P1) and and3_2(w6,P1,P0,Ci) or or3_3(C1,w6,w3,G1) or or2_4(C0,G0,w9) and and2_5(w9,P0,Ci) and and2_6(w13,w11,w12) and and2_7(w12,P1,P2) and and2_8(w11,Ci,P0) and and3_9(w15,G0,P1,P2) and and2_10(w16,P2,G1) or or2_11(C2,w17,w18) or or2_12(w18,w16,G2) or or2_13(w17,w13,w15) or or2_14(C3,w21,G3) or or2_15(w24,G0,P0) and and2_16(w25,Ci,w24) and and2_17(w26,P1,w25) or or2_18(w27,w26,G1) and and2_19(w28,P2,w27) or or2_20(w29,w28,G2)
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
11
and and2_21(w21,P3,w29) or or2_23(C0,G0,w9) and and2_24(w9,P0,Ci) endmodule
Este esquema es el usual que se utiliza al hacer diseo por celdas estndar o arreglo de compuertas. Observando el trmino C3 de la generacin de acarreo este puede simplificarse a: C3 = G3 + P3 . (G2 + P2( G1 + P1(G0 + P0Ci))) (2.16)
Esta funcin se implementa fcilmente como una compuerta en domin y de igual forma las etapas C0, C1 y C2. Esto permite obtener una tajada de datos de 4 bits y expandir el sumador con el mismo criterio con el que se ampliaba el de propagacin a partir de bloques de 1 bit. El sumador de 4 bits se convierte en la unidad bsica y puede compartir acarreos locales cada 4 bits. De la implementacin y la tecnologa dependen que el acarreo en bloques de 4 supere en tiempo al acarreo secuencial. La reduccin a bloques de 4 bits es una limitante a lo que tericamente podra ser un sumador completamente paralelo pero como se mencion antes, la complejidad de las etapas de prediccin consumira demasiada rea de lgica e interconexin. Los sumadores de solucin por recurrencia son otra familia; derivados de los trabajos de KoggeStone y mejorados por los esquemas de Bigory-Gajski y Brent-Kung [2] Sobre el supuesto de que si Ci = 0 las ecuaciones de prediccin de acarreo se simplifican a una forma recurrente del tipo: (g,p) * (g,p) = (g +pg , pp) (2.17)
As se describe el operador * el cual se utiliza para definir las tablas de propagacin de los acarreos, un ejemplo de tabla se muestra en la figura 2.3:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
12
Figura 2.3: Topologa de la solucin recurrente. En esencia el uso de la tabla simplifica los trminos de la ecuacin de prediccin de acarreo por lo que el sumador en si es una alteracin de la topologa de prediccin de acarreo. La estructura de suma condicional ataca el problema desde otro ngulo, en lugar de esperar por la generacin o propagacin del acarreo se ejecutan ambas condiciones al mismo tiempo. Luego una estructura de multiplexor escoge el resultado apropiado de acuerdo al verdadero acarreo. Similar a la estructura del predictor de acarreo, se divide la palabra en bloques que luego se suman condicionalmente. En teora este es el esquema de sumador ms rpido que pueda construirse, pero, como en un predictor de profundidad igual al nmero de bits de la palabra que opera, la complejidad del circuito es demasiada. La sub-optimizacin ms viable para esta estructura la encontramos en el sumador de seleccin de acarreo. Este implementa suma condicional en la parte ms significativa de la suma pero mantiene alguna de las otras arquitecturas en la parte baja. As toma ventaja de la velocidad de l acarreo condicional en el camino ctrico pero no duplica la complejidad del circuito. Los sumadores son bloques de lgica de gran importancia pues son la base de muchas operaciones aritmticas complejas, pero de igual importancia son otros bloques que interactan directamente con el sumador y que en muchos casos influyen en el control o dependen de los resultados de este. Enumeraremos unos cuantos.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
13
2.1.1 Estructuras comnmente asociadas a los sumadores. Los resultados de la operacin de un sumador, forman una palabra de datos tanto o mas complejos que cada uno de los operandos que le diera forma. El vector de banderas aritmticas que acompaa a cada palabra de datos puede convertirse en una de las ms importantes herramientas de optimizacin en la utilizacin de los recursos de la mquina. En la mayora de ocasiones el resultado de una suma no es tan importante como la decisin condicional que se puede tomar a partir de las banderas que ese resultado gener. Las banderas mas comunes son Cero, Paridad y Acarreo, otras pueden engrosar la lista como son: El Rebalse, que se da cuando el sumador entrega un resultado superior al que puede contener la palabra de destino. La bandera Auxiliar que indica el acarreo en una operacin de cdigo binario decimal. Adems todo otro vector que ayude a analizar el dato resultante o fuente, como por ejemplo detectores de primer 1 y otros. Los generadores de paridad detectan el nmero de bits de la palabra que se encuentran en 1 haciendo la O-exclusiva de todos los bits de la palabra de forma secuencial. Los detectores de palabra en cero o palabra en unos son conos de lgica de abanico de entrada muy grande y por lo tanto de retardo significativo. Un comparador de magnitudes se implementa fcilmente a partir de un complementador y un sumador utilizando luego un detector de ceros. Las operaciones Booleanas bit a bit son mucho ms simples y fciles de generar, pero vale la pena notar que en la lgica propia del sumador muchas de estas operaciones ya se han implementado. Si se esta dispuesto a compartir recursos en la mquina y complicar el control del sumador, esa rea puede ahorrarse a costa del desempeo. Las operaciones ms complejas de manejo de datos como multiplicacin, divisin o filtrado se pueden implementar a partir de la suma y la resta aprovechando la circuitera del sumador. Usualmente para aplicaciones de alto desempeo se crean unidades de multiplicacin, divisin y otros que poseen sus propios sumadores especializados. El concepto bsico se mantiene: un buen sumador puede convertirse en un bloque estndar en el diseo de un sistema digital, ya sea que se utilice aislado para su propsito original o como parte de un subsistema ms complejo que tiene otro fin.
2.1.2 Criterios de escogencia. Ante las diversas opciones de sumadores que existen, una mtrica comn es definir la magnitud de cada tipo en 3 ejes de decisin: tiempo, espacio y costo. Tomando esto en cuenta, se hace la escogencia de una implementacin. El sumador de propagacin de acarreo es usualmente la mejor opcin, es pequeo, simple y relativamente rpido. Es especialmente bueno para aplicaciones con largas colas de proceso,
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
14
pues su retardo se adapta a una o ms etapas de la secuencia de la mquina. Cuando se necesita un sumador ms paralelo y de menor latencia, las libreras estndar usualmente proveen bloques sumadores de 4 bits que ya implementan los predictores de acarreo. Estos pueden utilizarse para implementar sumadores de tamao n mltiplo de 4, en configuracin de rbol. Esto se logra con relativa facilidad. Mayor velocidad se puede conseguir a partir del sumador de seleccin de acarreo pero el rea casi se duplica por lo que ste ser el factor decisivo entre rea y velocidad. Otra ventaja de este ltimo, es que se compone fcilmente de secuencias de propagacin de acarreo. Los sumadores de salto del acarreo y los de solucin por recurrencia son variaciones mas avanzadas de los modelos tradicionales, requieren mayor esfuerzo de diseo y pierden regularidad en el diseo fsico, pero son las mejores opciones para aplicaciones de alta velocidad. Para aplicaciones como multiplicadores u otras en la que la velocidad del resultado no es especialmente crtica se busca utilizar aquellos en los que el retraso del acarreo y los datos es muy similar. En general para sumadores de ms de 32 bits se utilizan combinaciones para las partes baja y alta. Esto minimiza los tiempos de retraso si la necesidad de desempeo es crtica para el diseo. Parece sencillo aplicar una regla emprica para tomar una decisin de diseo importante y en realidad es as. Puesto que el sumador por s solo no es un sistema til, y su entorno se va a encargar en muchos casos de limitar la gama de opciones que se tiene a la hora de escoger el sumador. Las limitantes de rea, tiempo de retraso, ancho de palabra, tecnologa de fabricacin, validacin del sistema y tiempo de entrega del diseo final se encargaran muy probablemente de dejar a los diseadores con una nica solucin siempre sub-ptima para resolver su problema de adicin.
CAPTULO 3: Escogencia de la arquitectura apropiada.
3.1 Limitantes del diseo.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
15
Para efecto de comparar las arquitecturas el criterio hubo de reducirse bajo el supuesto que el diseo para el cual el sumador se hubo de escoger es un microprocesador de alto desempeo de propsito general orientado a las aplicaciones porttiles, de bajo consumo de potencia y de dimensiones reducidas. Se decidi que el sistema ha de implementarse en el proceso comercial de cualquier suplidor como por ejemplo MOSIS. El programa de diseo lgico y fsico Microwind se escogi como la herramienta preferida de diseo. La descripcin lgica se hara en Verliog. La razn esencial para suponer este ambiente, fue la tendencia reciente de la mayora de compaas comerciales de microprocesadores de enfocar sus esfuerzos de mercado a la rama mvil y la tendencia de la industria de electrodomsticos de incorporar cada vez mas poder computacional en la mayora de productos comunes, como lo son los telfonos, organizadores personales y centros de entretenimiento porttiles. Rpidamente los requerimientos de poder de procesamiento de este tipo de dispositivos han dejado atrs al diseo tradicional enfocado a ASICS o sistemas de propsito especfico. Cada vez el nivel de integracin nos permite ver el da que un procesador de cualquier arquitectura mayor sea reducido lo suficiente en tamao y consumo para poder incorporarse a un pequeo sistema porttil. Pronto modelos recientes de la arquitectura X86 de Intel o PowerPC de Motorola encuentran cabida en los dispositivos porttiles como la pocketpc de Compaq. Desde ese punto de vista, varios supuestos delimitaron el marco en el cual el diseo se hizo y ese marco defini los criterios de seleccin de la arquitectura de sumador que se buscaba. El sistema general siendo un microprocesador de propsito general con un lenguaje y ambiente de programacin propietario el cual sera del tipo de conjunto reducido de instrucciones, aunque esto no es estrictamente necesario. Se supuso adems que el desempeo requerido era tal que la mquina habra de ser un sistema de ejecucin fuera de orden con una cola de ejecucin relativamente profunda. Un sistema simple de prediccin de saltos, unidades de ejecucin separadas e independientes, renombramiento de registros, deteccin de dependencias y ordenamiento dinmico de las colas de ejecucin. Tambin sera un procesador de 32 bits con 2 niveles de cache integrado. Una caracterstica del diseo, que tiene que ver en gran medida con la rentabilidad del producto, es su ciclo de vida. Se espera que el diseo sea fcilmente escalable a nuevos procesos y tecnologas de fabricacin. Por lo que este factor se consider como parte integral del diseo. Las condiciones iniciales son vagas en lo que al sumador en cuestin respecta pero algunas deducciones lgicas se hicieron en este punto. El sistema deba buscar el mayor grado de integracin que el proceso le permita. El desempeo dependera en gran medida de la frecuencia de operacin de la mquina. Los bloques en general se asemejan a los primeros procesadores con ejecucin fuera de orden. De la vida til que tuviera esta familia de microprocesadores se aprendi que la frecuencia y las constantes mejoras en tecnologa de fabricacin jugaron un papel esencial en la carrera por el desempeo y la supervivencia en el mercado de estos productos. La ejecucin fuera de orden, el renombramiento de registros y la deteccin de dependencias de datos, arrojan mucha luz sobre la operacin de las unidades de ejecucin en la mquina. Dadas estas condiciones, el secuenciador de operaciones estara en capacidad de escribir colas de operaciones consecutivas que utilizaran la mquina a mxima capacidad, sin ciclos muertos
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
16
entre operaciones. Ya que la mquina estara diseada para tener una cola de operaciones, la ejecucin de las instrucciones del sumador podra ser instantnea o separada en etapas; pero el requerimiento de alto desempeo nos hizo suponer que una ejecucin en un tiempo corto es lo apropiado. 1 2 ciclos de reloj deberan ser suficientes para obtener el resultado de una suma. El sumador operara sobre palabras de 32 bits de ancho. Por otro lado las herramientas de diseo con que se cont son bastante simples y es probable que presenten un obstculo al anlisis de diseos de alta complejidad. El diseo escogido debera tener modelos equivalentes de relativa simpleza para poder analizarlo por simulacin. La capacidad de edicin de diseo fsico, aunque existente fue limitada, tanto por la potencia de la herramienta, como por el costo del recurso humano apropiado. Este es uno de los factores determinantes que ha hecho tan apreciada la tcnica de diseo por celdas estndar y sntesis de plano fsico a partir de los modelos de comportamiento en lenguaje de descripcin de hardware. El sumador bsico debera a su vez ser reutilizable dentro del diseo. Aunque se escogi la opcin apropiada a la unidad de aritmtica de enteros, debera ser posible con poco esfuerzo utilizar el mismo sumador como submdulo de la unidad de aritmtica de punto flotante, unidad de manejo de memoria y otros. Como se mencion antes, el factor de costo fue determinante. El tiempo que el diseo lgico y de circuitos requiera para estar listo, es tan importante como la facilidad de sintetizarlo o dibujarlo en plano fsico. Igualmente importante es el rea final que el sumador va a requerir en el sistema total y esto depende directamente de la tcnica de diseo fsico. El costo tiene adems una dimensin temporal que es esencial: El tiempo de mercado de un producto es el principal lmite temporal de todo proyecto de ingeniera y en el caso de los circuitos electrnicos, con la feroz competencia que existe, esto es an ms latente. Otra etapa del diseo que representa un costo temporal importante es la verificacin del diseo. La verificacin puede separarse en 2 grandes ramas, la verificacin lgica-funcional y la verificacin elctrica y de tiempos. Ambas partes suponen la puesta en marcha de un plan y una estrategia de verificacin que esencialmente describe los procesos por los cuales se asegurar, por medio de simulacin, que el diseo a implementar cumpla las especificaciones requeridas por su entorno. La estructura y complejidad del sistema determinan que tan sencillo es establecer la estrategia de validacin y que tantos recursos son necesarios, tanto en material como horashombre para asegurar la funcionalidad del diseo. Es absolutamente necesario que antes de enviar un diseo a produccin su verificacin haya alcanzado el nivel de confianza a partir del cual se puede garantizar al consumidor un funcionamiento apropiado del producto. Esto no se limita al diseo de microprocesadores; pero les afecta sobremanera ya que es muy difcil brindar servicio en campo a un producto de esta ndole. A partir de estas limitaciones y criterios de seleccin se revisaron las opciones viables con motivo de ilustrar el proceso de escogencia del circuito. Se compararon las particularidades de su diseo lgico, fsico y su verificacin para encontrar la mejor opcin para nuestro caso hipottico. 3.2 Comparacin de las opciones disponibles.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
17
Las distintas implementaciones de sumadores, por la filosofa de su construccin, se comportan de manera diferente en lo que respecta a los principios del diseo estructurado. Tambin tienen diferentes magnitudes en los ejes de diseo de tiempo, espacio y complejidad. La primera opcin de diseo estudiada fue el sumador de propagacin de acarreo. Las ventajas de este diseo fueron muchas: su diseo lgico es bastante simple, y con muy pocas compuertas, el bloque bsico de sumador completo esta listo para funcionar. Se completa el alambrado en cascada de una secuencia de bloques idnticos y el sumador esta listo. Entre las ventajas fsicas de esta configuracin, la principal es su regularidad. Cada etapa es idntica a la anterior; esto permite que el diseo fsico se optimice para la interconexin consigo mismo ayudando a la integracin del circuito y mejorando la tasa de paso estadstica del circuito en fabricacin. Eso se da al reducirse el nmero de singularidades por rea en el silicio. La regularidad igualmente facilitara el diseo de la distribucin de potencia en el silicio. El diseo lgico puede corresponder 1 a 1 con la implementacin en compuertas, y la regularidad de los bloques da paso a que la simplificacin del circuito se transfiera al modelo de comportamiento; simplificando la verificacin. Se tom como ejemplo de sumador completo de 1 bit de la figura 3.1:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
18
Figura 3.1: Sumador completo de 1 bit. El cdigo simple correspondiente al sumador fue sintetizado tal que:
module sum1bitcompleto( A,B,C,Sum,Carry); input A,B,C; output Sum,Carry; xor xor2_4(w4,A,B) or or2_5(w6,C,w5) or or2_6(w7,A,B) and and2_7(Carry,w6,w7) and and2_8(w5,B,A) xor xor2_9(Sum,w4,C) endmodule
La celda result simple y se podra utilizar como parte de la librera estndar del diseo. Fue importante notar que un circuito bsico como este, existe casi con seguridad en todas las libreras estndar de los diferentes procesos comerciales, por lo que la sntesis de un sumador de este tipo sera muy sencilla a partir de bloques predefinidos. Los enrutadores automticos lograran una tasa de rea de interconexin / nmero de conexiones bastante alta, ayudando a la disminucin del rea total del circuito. El hecho de estar compuesto de lgica esttica introduce el beneficio de la facilidad de simulacin. La regularidad inherente del sistema, permite caracterizar un bloque nico, convertir este en una caja negra, con un diagrama de tiempos simple; que facilita la extrapolacin a n instancias consecutivas. Ya se conoce la peor limitante de frecuencia de este sistema, ya sabemos que la latencia crecer linealmente 32 veces desde Ci (al inicio del clculo) hasta Carry quien corresponde a C32. Una burda aproximacin derivada del esquemtico presentado anteriormente nos permiti decir que el retraso mximo de una transicin en el nodo de salida del acarreo es de 2 compuertas: La inversin requerida para las seales negadas internas y luego la operacin de la NO-Y que ejecuta el clculo. As se aproxim el retraso del acarreo propagndose 32 veces en 64T; donde T es una medida normalizada del tiempo de retraso de una compuerta NO-Y optimizada, con la seal critica en la cabeza de la serie n-mos y de flancos 0 1 y 1 0 simtricos. Esta aproximacin nos provey una idea general de la magnitud del retraso por dispositivo conmutante. No tom en cuenta el retraso por interconexin, que entre bloques consecutivos tan regulares como los que se analizaron, poda parecer despreciable. Sin embargo luego de 31 propagaciones el efecto debe hacerse notar. A medida que la tecnologa se mueve hacia las dimensiones submicrnicas y a procesos de muchas capas de metales, como los que se requieren para las celdas estndar, el retraso de la interconexin se vuelve mayor. Fue claro que con 64 tiempos de retraso, nuestro propagador de acarreo distaba mucho de tener una latencia de 1 2 ciclos, a menos que la frecuencia de operacin del sistema fuese increblemente baja. Esto no es comn. Si la velocidad de respuesta nos preocupa, se poda atacar el problema de una forma muy sencilla: multiplicando los recursos. Si se tuviesen 2 sumadores en lugar de uno y confiamos que la deteccin de dependencias de datos es razonablemente buena, la velocidad se duplica. Se pueden alimentar ambas unidades en paralelo. Esto aunque posible se presentaba muy costoso en
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
19
control y rea, no ofreca un retorno sobre inversin aceptable pues se sabe que podemos tener sistemas ms rpidos. Un sumador serial iterativo utiliza nicamente un bloque de sumador y sus respectivos registros de desplazamiento. Esta podra ser una forma de multiplicar los recursos, pero los registros representan un rea considerable. La lgica de control necesaria es bastante ms compleja que la que necesitara el sumador de propagacin. Para muestra de esto se utiliz el ejemplo de la figura 3.2:
Figura 3.2: Diagrama de bloques de un sumador de acarreo guardado.
Con esta configuracin de acarreo guardado se necesitaran al menos 32 ciclos de reloj en el mejor de los casos (cuando se implementan la memoria de acarreo con un Latch y se aprovecha
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
20
la transparencia.) Por esto, sobreescalar los sumadores de esta manera tampoco pareci atractivo. Existen sin embargo aplicaciones que no son necesariamente veloces, para las cuales un sumador de este tipo es muy deseable. En sistemas de procesamiento digital de seales que utilizan operaciones de filtrado eminentemente iterativas, multiplicar el numero de recursos es invaluable. Ya que la velocidad era de inters; Por que no aprovechar otras configuraciones mas rpidas del sumador de acarreo y reducir el retraso de sus etapas? Se revis la siguiente configuracin que produce el negado del acarreo, con un mximo retraso de 1 transicin en una cascada de 3 pmos. La suma es considerablemente ms lenta que en la configuracin previa; pero es esencialmente paralela. El acarreo entrando en los bloques del 1 en adelante, define la transicin crtica. Se observ como se optimiza la serie de transistores en la generacin de la suma. Tal como se aprecia en el diagrama esquemtico de la figura 3.3:
Figura 3.3: acarreo por nodo interno.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
21
La manera ptima de utilizar esta configuracin es eliminando el inversor en la salida del acarreo. Los bloques impares quedaran actuando sobre datos negados. Esto redujo significativamente el tiempo de propagacin del acarreo, pero el abanico de salida del nodo de acarreo es mucho mayor. Luego la transicin puede ser un poco ms lenta de lo esperado. Fue importante notar que esta configuracin necesita una etapa de inversin extra en el camino de los bits impares, pero este retraso no se sumara a la cadena de retraso del acarreo, pues retrasa al bit 1 de la palabra. Cuando esto ocurre, el retraso propio del acarreo ya se ha cumplido al transicionar C en el bloque 1. Un retraso extra que no se consider, es el de la etapa de inversin de datos a la entrada del sumador. Para proveer el complemento de un operando necesario en le caso de la resta, el dato pasara por un arreglo de n O-exclusivas. Ah un bit de control basta para invertir la palabra antes de llegar a las tajadas de 1 bit del sumador. El mismo bit de control podra por un mtodo similar invertir el acarreo de entrada del bloque 0. Esta configuracin mejorada del circuito mantuvo la ventaja de regularidad del plano fsico. Esto facilit la interconexin y reduce el rea. El sistema continu siendo relativamente simple y aunque ms rpido, se mantuvo linealmente dependiente del nmero de bits; por lo cual se debieron considerar otras opciones. Una implementacin Interesante del sumador completo es la suma por compuertas de paso. Esta configuracin puede aprovecharse para mejorar la estructura bsica del sumador de propagacin de acarreo. La topologa utiliza una O-exclusiva alambrada con compuertas de paso. El problema que presentan los circuitos con series de compuertas de paso es la degradacin de la seal por las prdidas de voltaje a causa del voltaje de umbral. El ruido que atraviesa las difusiones, la prdida de la capacidad regenerativa de las etapas de lgica complementaria y la alta resistencia de las conexiones en serie de difusiones. La compuerta O-exclusiva que se utiliz es de esta forma:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
22
Figura 3.4: Compuerta O-exclusiva con transistores de paso. Utilizando esta estructura se construy un sumador completo de la figura 3.5:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
23
Figura 3.5: Sumador completo por compuertas de paso. Dependiendo de lo que se desee una optimizacin que utiliza menos transistores se presenta a continuacin:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
24
Figura 3.6: Diagrama simplificado del sumador por compuertas de paso. Estas son otras opciones de implementar el sumador original. Se pueden combinar todas las tcnicas que hemos presentado para obtener un diseo ms rpido y compacto. Pero esta ltima implementacin present un problema especial. La gran mayora de simuladores estticos de circuitos tienen grandes dificultades para simular correctamente el comportamiento de los transistores de paso, por lo que no habra sido tan sencilla la verificacin temporal del circuito. Aunque se mantuvo la regularidad bit a bit en el plano fsico, la celda se volvi menos genrica y difcil de encontrar en libreras estndar. La sntesis se complic. Un asunto digno de considerar fue que los procesos de fabricacin rara vez mejoran las caractersticas de respuesta de los transistores p y n de igual manera; esto agregara complejidad a la tarea de simular las compuertas de paso a la vez que se mostraron ms difciles de escalar. Se desconfi naturalmente de la capacidad de la herramienta de mostrar lo que ocurrira con otro proceso. Se determin recomendable entonces aprovechar sistemas para los que ya se tienen modelos y caracterizaciones probadas; no solo en un proceso sino en el caso de una mejora de este.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
25
Se not en este punto que el retraso lineal a lo largo de la propagacin del acarreo hace que las operaciones ms cortas: 8 y 16 bits, sean ms veloces. Aunque existen diversas formas de implementar las operaciones de palabras de ancho menor, las ms comunes y aplicables a la mayora de arquitecturas de sumador, son el corrimiento del bit menos significativo y el monitoreo de banderas intermedias. La ms sencilla desde el punto de vista lgico, es el corrimiento del bit menos significativo. La unidad de memoria se encarga de acomodar los datos corridos a la izquierda 16, 24 o 28 espacios y usualmente se rellena con ceros el resto de la palabra para que no afecte al circuito detector de ceros. El corrimiento permite que el acarreo de ultimo bloque continu siendo la ba ndera de acarreo real del registro y el rebalse para cada ancho de palabra es vlido. Es necesario sin embargo que existan lneas de control que puedan alterar los acarreos entrando para cada bloque que corresponde al bit menos significativo de una operacin de 16, 8 4 bits. Si no se hace el corrimiento de datos, el monitoreo deber hacerse sobre los acarreos de la tajada 3, 7 y 15, para determinar el acarreo de cada ancho de palabra. El manejo del acarreo entrando no es alterado en ninguna manera pero la deteccin de rebalse si de be hacerse en su respectivo lugar por lo que este acercamiento requiere un poco mas de lgica y altera la regularidad de los bloques un poco ms. Como se discuti con anterioridad el sumador terico ms veloz que pueda construirse es el de salto de acarreo optimizado para bloques variables. Se analizaron los requerimientos de implementacin de esta versin de sumador. El sumador de acarreo saltado ms sencillo supuso bloques de salto de acarreo de profundidad regular, usualmente 4, que por separado se comportan como propagadores de acarreo. Estos incorporan los calculadores de propagacin para que bloques enteros se puedan obviar en el camino. Cualquier forma de generar los sumadores de propagacin de profundidad 4 va a dar buen resultado. La latencia de un bloque de 4 es relativamente corta: si seguimos la aproximacin usada antes, se reducira a 8T normalizados. A partir del sumador bsico de 1 bit, una simple compuerta Y de 4 entradas asegura que el bloque en cuestin pueda ser saltado por el acarreo. Se observ la estructura bsica del sumador de salto de acarreo en la figura 3.7:
Figura 3.7: diagrama de bloques del sumador de salto de acarreo.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
26
Debido a la forma en la que el acarreo habra de saltarse los bloques intermedios del sumador, el retraso total es menor. Aunque continu siendo dependiente del acarreo y linealmente dependiente del ancho de la palabra. Continuando con nuestro esquema de anlisis de tiempo normalizado se obtuvo ?= (k-1) ?prop + (N/k 2 ) ?salto + (k-1) ?prop ?= 2 (k-1) ?prop + (N/k 2 ) ?salto (3.1) (3.2)
Recordemos que nuestro ?prop correspondia a 2T normalizados por lo que para N = 32 con k = 4 tenemos que: ?= 24T (3.3)
Y este seria el peor caso para este sumador. Se not a mejora en el tiempo de retardo comparando esta implementacin con el sumador de propagacin. En algunos microprocesadores modernos la frecuencia del reloj se ajusta de modo que, guardando tiempo en ambos flancos por problemas de retraso o inexactitudes en la red de distribucin; al menos el tiempo de 20 inversiones quepa dentro de un ciclo. A grosso modo 10 etapas de lgica por ciclo de reloj. Se supuso que nuestros requerimientos de frecuencia se adaptaran al proceso de pr oduccin que se escoja cerca de esta mtrica, este sumador podra encuadrarse en 2 ciclos de reloj aproximadamente. Aunque en nuestra burda mtrica se supuso 24 y no 20 etapas de lgica se aprovech la siguiente libertad: El sumador no requiere de reloj en ninguna de sus etapas. Luego, se controlaran los registros de entrada de datos y de captura del resultado con flancos separados por 2 ciclos. Como se pudo observar, los cambios de topologa que implica convertir nuestro sumador de propagacin en uno de salto de acarreo son mnimos. La mayora de las ventajas de plano fsico, verificacin lgica y temporizacin se mantuvieron. La regularidad permite la construccin de un arreglo de celdas, facilitando la distribucin de potencia y la interconexin de datos y control. Se aprovechara esto para aumentar la densidad de difusiones y metales bajos, reduciendo la carga capacitiva de la interconexin. El uso de bloques de 4 tajadas facilitara la verificacin, pues nos permite caracterizar un nuevo nivel de caja negra que se podra utilizar recursivamente. Apareceran nuevos caminos crticos los cuales deben ser analizados por separado y complican el modelo de tiempos. La verificacin lgica tambin incorpora cambios; el modelo de comportamiento debera ajustarse a la cadena de salto de acarreo. Si consideramos las operaciones de ancho menor nos encontramos ante la misma problemtica de los otros sumadores. Por lo que a ese respecto la dificultad no se incrementa. Separar el sumador en bloques de igual tamao es una solucin sub-ptima; que el sumador de bloques de tamao variable mejora, al acortar los caminos de propagacin y aumentar los de salto. Esta opcin fue digna de considerar pues es la ms veloz. Pero buscar esa optimizacin implica perder muchas de la ve ntaja del arreglo de celdas regulares. La introduccin de particularidades en el plano fsico conllevara factores que no se tenan en cuenta: efectos capacitivos irregulares, irregularidad en la distribucin de potencia, y discrepancias en el modelo de verificacin de tiempos. La mayora de los simuladores de tiempos son estticos y trabajan
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
27
con base en modelos relativamente simples, de tiempos de transicin en un arreglo definido de nodos. Por lo tanto se requerira ms tiempo de anlisis y poder computacional para describir satisfactoriamente cada bloque dentro del sumador y el modelo de cajas negras se volvera menos til. El problema del tamao de los bloques present un detalle interesante. Las operaciones de nibble Byte y 16 bits. Las soluciones a este dilema habran sido: forzar los tamaos de los bloques, lo cual podra hacernos perder el beneficio de variar los tamaos, bien conectar nodos internos para tomar las salidas requeridas, lo que deteriora la regularidad del diseo. La carga de los nodos cambia, modificando el modelo de anlisis de tiempos. Pasar de bloques regulares a tamaos variables introducira dificultades significativas de plano fsico y la sntesis de este sistema, es muy probable que resultara dificultosa. Los sumadores de prediccin de acarreo se presentan como una opcin muy interesante en lo que a velocidad se refiere. La implementacin ms razonable de las etapas de prediccin es de 4 bits de profundidad. Los bloques regulares de plano fsico facilitan el diseo. El uso que se de al vector de predicciones depende de la arquitectura particular. Las distintas etapas de la prediccin se ordenan en forma de un rbol y operan independientes del resto del clculo. El camino crtico sufre un cambio radical, deja de propagarse paralelo al arreglo de tajadas de bits, se propaga perpendicular a este creando un eje en profundidad que nicamente considera la lgica de prediccin. Como consecuencia de esto, la linealidad o factor de linealidad respecto al ancho de palabra desparece. La relacin de tiempo de retardo en los esquemas de prediccin de acarreo se vuelve logartmica, del tipo: ? log (N) N es el ancho de palabra. La estructura de rbol se compone de etapas que tienen propsitos diferentes y que en esencia comparten tiempos de retardo regulares. Cada par de bits correspondientes pasa por las compuertas que generan las seales de acarreo generado y propagado. El propagado se utilizar ms adelante para calcular el resultado. Luego estas seales entran al bloque de prediccin, donde hay lgica para cada nivel que implementa las funciones propias de cada tajada de bits en el grupo de 4. La salida de esta lgica y el propagado inicial le dan forma a los resultados del primer bloque. Esta secuencia de lgica es mucho ms compleja que la del sumador de propagacin, pero tiene la ventaja de haber generado las seales necesarias para paralelizar el resto del clculo. La cuarta etapa de lgica es la que se encarga de definir seales de generado o propagado por bloque. Para aprovechar los saltos de bloque completo. Esta es la lgica que efectivamente propaga el acarreo entre los bloques independientes de 4 bits. En grupos de 16 bits, una seal extra generada por la cuarta etapa indica si el acarreo se saltar los 16 bits en grupo. La seal se genera para ambas partes de la palabra de 32; independizndolas en caso de no haber acarreo del bit 15 al 16. Si dicho acarreo existe, viene de la quinta etapa, cuyas entradas son los propagados de cada bloque de 16. El diagrama de bloques de la figura 3.8 ilustra la estructura de rbol: (3.4)
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
28
Figura 3.8: Diagrama de bloques del rbol de prediccin de acarreo. El resto de sumadores de solucin por recurrencia son bsicamente alteraciones de la estructura del rbol creando etapas intermedias con bloques de salto de longitud variable. Las diferencias importantes entre las soluciones por recurrencia ms refinadas y nuestro rbol de bloques de 4 bits fueron: la irregularidad del plano fsico y la complejidad de los alambrados resultantes. Estos 2 factores se conjugaron para hacerlos muy difciles de sintetizar. Su implementacin requera de muchas horas de trabajo sobre el dibujo, optimizando la interconexin. La gran cantidad de alambrado reducira la ganancia de usar lgica en Domin que adems de ser rpida, consume menos rea. La congestin de las capas bajas de metal obligara a utilizar metales superiores 3, 4 5 para alambrar datos. Los nodos superiores son muy sensibles al ruido. El ruido se empeorara en circuitos en Domin con multiplexores de compuertas de transmisin. Muchos factores dificultaran sobremanera la verificacin funcional del circuito. Varios ejemplos muy interesantes de soluciones recursivas nos presentaron Matthew M. Ziegler y Mircea R. Stan [1] :
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
29
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
30
Figura 3.9: Grafos de sumadores regulares por solucin recurrente: El anlisis de Ziegler Y Stan [1] se enfoca a las formas ms regulares por ser stas simples de sintetizar e implementar. En su dialctica se dedican a crear un espacio tridimensional que representa la complejidad de los diseos tomando en cuenta los siguientes factores de diseo: rea consumida, Abanico de salida Y raz. Recordemos que la raz en la estructura de un sumador corresponde al abanico de entrada de las etapas de acarreo generado y propagado que inciden en cada bloque nico de cada etapa. El diseo que se escoja incide en diferente profundidad en los tres ejes propuestos. El aumento en la raz lleva a crear bloques de lgica mayores, esto disminuye la regularidad pero concentra el ancho de la data, disminuyendo el rea pero aumentando el abanico de salida. La importancia de la dimensin en el abanico de salida es muy grande, pues representa la primera limitacin fsica que la frecuencia encuentra. El rea es igualmente esencial y se encuentra en el centro de las motivaciones del diseo de muy alta integracin: sin restriccin de rea no hay integracin, y es la primera mtrica cuantificable en trminos del costo de un diseo. Con base en esto los grafos correspondientes a sumadores de prediccin se comportan de la siguiente manera: menor raz implica mayor rea y menor abanico de salida; por lo tanto mayor frecuencia asociada a cada etapa. Observemos en la figura como varan los grafos de los sumadores a lo largo del eje de la raz:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
31
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
32
Figura 3.10: Grafos de un predictor de acarreo en raz creciente en potencias de 2. An con todos los beneficios de los diseos de predictores y diferentes rboles posibles. Estos mostraron un nivel de complejidad de la verificacin lgica y funcional muy superior a las arquitecturas ms simples. La dificultad que el anlisis de la lgica en Domino introdujo, no es trivial; la sintonizacin de los anchos de pulso en las etapas consecutivas requerira de un simulador muy preciso y muchas iteraciones para encontrar el balance entre los retardos de las series N-mos y los anchos de pulso. Se consider el problema del ruido en los nodos, cuya solucin es un trabajo de diseo de circuitos considerable. Se observ de los grafos que ya los diagramas se complicaban y nicamente se haba resuelto la aritmtica para 16 bits, por lo cual es lgico suponer que la complejidad que hemos alcanzado es como mnimo la mitad de lo que habramos de enfrentar. Debido a las restricciones de capacidad de simulacin (o tiempo para obtener una simulacin apropiada) que se impusieron al inicio, la complejidad de los diseos de prediccin y la dificultad de encontrar celdas estndar genricas. Se lleg a la conclusin de adoptar el muy regular simple y relativamente rpido sumador con salto de acarreo. Esta decisin puede parecer conservadora; pero los beneficios de la regularidad en trminos de rapidez de diseo y validacin son muy grandes.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
33
Aprovechando la regularidad del diseo el sumador de 32 bits crecera bloque a bloque. Se utilizara el esquema de salto por grupos de 4. Los siguientes seran los bloques constit uyentes de nuestro sumador; estos se generaran a partir de la librera IEEE que utiliza el programa Microwind.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
34
CAPTULO 4: Diseo del sumador escogido y anlisis de resultados
4.1 Simulacin lgica. Se decidi utilizar una forma fcil e interesante de analizar logicamente el que sera nuestro sumador. Para esto, se gener un modelo lgico en hoja de clculo con el enorme beneficio de tener un sistema visual que fue de enorme ayuda para el diseo fsico. Se utiliz de manera ilustrativa el sumador completo de 1 bit con sus de acarreo propagado y generado: Tabla 4.1: Columna de clculo correspondiente al sumador completo de 1 bit.
A B Ci G P S Co
1 1 0 1 1 0 1
0 0 1 0 0 1 0
0 1 0 0 1 1 0
0 1 1 0 1 0 1
1 0 0 0 1 1 0
1 0 1 0 1 0 1
1 1 0 1 1 0 1
1 1 1 1 1 1 1
Cada columna implementa las siguientes funciones por fila: A: Bit de entrada. B: Bit de entrada Ci: Acarreo de entrada a la columna G: =IF(AND(A,B),1,0) el condicional se utiliz para mantener el formato de respuesta en 1 y 0 P: =IF(OR(A,B),1,0) (4.2) (4.1)
S: =IF(OR((AND(A,NOT(B),NOT(C))),(AND(NOT(A),B,NOT(C))),(AND(NOT(A), NOT(B),C)),(AND(A,B,C))),1,0) (4.3) Co: =IF(OR(AND(OR(A,B),C),AND(A,B)),1,0) (4.4)
Luego, cada columna corresponde a una de nuestras tajadas de bits y la columna tiene completa funcionalidad. Una de las ventajas de describir la lgica de esta manera fue el rastreo visual de
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
35
las dependencias en las casillas de la hoja de clculo, se observ, en cada una de las implementaciones como depende de las entradas, esto se observa en la tabla 4.2: Tabla 4.2: Dependencias del sumador de 1 bit:
La siguiente etapa en el diseo fue generar a partir de nuestra tajada de 1 bit un sumador de 4 bits de propagacin de acarreo. Yuxtaponiendo 4 tajadas y conectando los acarreos entrantes de todas las etapas no primarias a su precedente salida se obtuvo la tabla 4.3: Tabla 4.3: Dependencias del sumador de 4 bits con propagacin de acarreo.
Se pudo observar al acarreo propagarse por las 3 etapas consecutivas afectando el clculo de las sumatorias y los acarreos salientes. En este punto se apreci la simpleza del diseo de propagacin. Replicando lo anterior n veces se podra obtener con asombrosa simpleza un sumador tan ancho como se desee. El diseo de salto de acarreo requiere generar para cada bloque de 4 bits una condicin de salto de bloque la cual se da si las 4 tajadas generan P. se implement de esta manera:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
36 (4.5)
Bp= IF(AND(P0,P1,P2,P3),1,0)
Luego, si existe el acarreo de entrada al bloque, ste puede pasar al siguiente sin tener que propagarse por las 4 etapas del actual: Bcs =IF(AND(Ci,Bp),1,0) (4.6)
Finalmente el acarreo entrante al prximo bloque es cualquiera entre el de salida del bloque anterior o el que salt al bloque anterior: NxBCin=IF(OR(C1n-1,Bcsn-1),1,0) (4.7)
Se replic esta estructura y se form nuestro sumador de 32 bits con salto de accarreo. Este se muestra en la tabla 4.4:
Tabla 4.4: Sumador de 32 bits en simulacin lgica.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
37
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
38
Como se observ de la seccin anterior, la ayuda visual de la hoja de clculo puede ser de utilidad para entender las dependencias de interconexin de nuestro diseo. Cada lnea de dependencia corresponde a una ruta de datos en el plano fsico y se aprovech esta abstraccin grfica para planear la optimizacin de estas lneas. Es importante observar en este momento, la cantidad de lneas de metal que se trazan en la direccin de los datos, por lo que las seales crticas han de ser optimizadas, forzndolas a compartir direccin con las lneas de control; As se minimizan desviaciones y vas innecesarias. De igual manera se reduce la posibilidad de diafonas. La regularidad de las casillas asemeja un arreglo de celdas estndar de huella constante, lo cual es usual en las libreras de manejo de datos. Aprovechando los beneficios de esta representacin del sistema, se observaron no slo las dependencias de alambrado, sino el comportamiento propio de la arquitectura del sumador de salto. A grandes rasgos, se asumi que cada traza de dependencia corresponde al retraso de una compuerta y su correspondiente lnea de transmisin. Tambin se observ la dimensin de los abanicos de salida de cada compuerta. Todo esto cre una imagen a priori de las dimensiones de las compuertas a usar. Las trazas de dependencia se analizaron en las siguientes tablas. Tabla 4.5: Trazas de las dependencias de la sumatoria y acarreo de salida de la tajada 32, desde el prximo acarreo del bit 27.
Estas son las dependencias a 8 trazas para la sumatoria: se contaron 5 propagaciones del acarreo desde la ltima posicin de salto del acarreo.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
39
Tabla 4.6: Trazas de las dependencias de la sumatoria y acarreo de salida de la tajada 32, desde el cuarto bloque de 4 bits.
Estas son las dependencias a 12 trazas: Se observ como el acarreo recorri la mitad alta del sumador; en el tiempo en que se completaron 2 propagaciones completas de 4 bits. Esto en realidad no ocurre serialmente excepto para el ltimo sumador de 4 bits, Se generaron las siguientes trazas. Tabla 4.7: Trazas de las dependencias de la sumatoria y acarreo de salida de la tajada 32, desde el acarreo entrando al bit 0.
Con 16 trazas ya el camino de saltos se complet desde Ci hasta Co. En ste momento se volvi claro el paralelismo de los bloques de 4 bits. La propagacin por saltos del acarreo hizo que en bloques cons ecutivos nicamente se propagara el acarreo un mximo de 6 tajadas de 1 bit y a lo largo de todo el sumador aproximadamente 14 etapas de lgica.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
40
Tabla 4.8: Trazas de las dependencias de la sumatoria y acarreo de salida de la tajada 32, el primer bit de datos.
A 70 trazas, todas las dependencias se completaron. Se regener el diagrama de dependencias para acarreo de salida: Tabla 4.9: Trazas de las dependencias del acarreo de salida de la tajada 32 desde la 16.
A 12 trazas se observ que el paralelismo de los generadores de Suma y acarreo lograron aprovechar la arquitectura de la misma manera. 4.1.1 Verificacin del modelo. En este punto que nuestro diseo lgico estuvo listo se comenz otra de las etapas propias del diseo estructurado: la verificacin lgica. El ideal de verificacin es crear un ambiente de
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
41
prueba para el cdigo de Verilog que representa nuestro circuito. En este punto sin embargo, se recurri a un artilugio ms simple. Este logr revelar errores de diseo con gran facilidad. A nuestro arreglo de lgica en la hoja de clculo se le agreg una serie de funciones que se encargan de generar valores aleatorios para los vectores de entrada y un comparador aritmtico que verifica los valores producidos por la lgica. Esto se hizo tan simple como: Tabla 4.10: Generador de vectores aleatorios y clculos de verificacin.
Todas las casillas de los vectores A y B se implementaron la siguiente funcin: =IF(RAND()<0.5,0,1) (4.8)
Tambin se implement un convertidor binario /decimal (sumas y potencias) para tener una imagen fcil de leer de los vectores aleatorios y la sumatoria. Una simple suma toma los vectores convertidos a decimal y entrega un resultado que se compara con la sumatoria para verificar su exactitud. =IF(SUM(A,B)>=2^32,SUM(A,B)-2^32,SUM(A,B)) (4.9)
Recordemos que la suma aritmtica va a considerar el acarreo de salida como parte del resultado ya que no existe rebalse, as que se debi restar ese valor en caso de haber superado los 32 bits. =IF((SUM-ARITH_SUM)=0,"PASS","FAIl") Se incluy un pequeo mensaje de error. (4.10)
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
42
Tabla 4.11: Pantalla del comparador de sumas.
Cada vez que los vectores aleatorios se recalculaban, una nueva suma se ejecut y los resultados se compararon. Esto nos cre un patrn simple de prueba aleatoria de la suma.
4.2 Modelado lgico esquemtico. La implementacin en esquemticos del diseo, utilizando bloques simples y jerarqua, se hizo ms simple conociendo la estructura regular del sistema y sus principales interconexiones. LA figura 4.1 muestra nuestro primer bloque esencial.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
43
Figura 4.1: Sumador completo de 1 bit: Se cre y utiliz esta estructura como base para nuestro sumador, a partir de este bloque creci la jerarqua. Adicionando una compuerta O para producir el propagado de acarreo se obtuvo e lcircuito de la figura 4.2:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
44
Figura 4.2: Sumador completo de 1 bit con propagado de acarreo: Luego se gener un smbolo para nuestro sumador con generacin de propagado y se cre el sumador de 4 bits de propagacin de acarreo con salidas de seal de propagado:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
45
Figura 4.3: Smbolo del sumador completo de 1 bit y conexin de 4. Cada etapa de 4 bits se comporta de manera independiente, externa a esta lgica se debi construir la de sealizacin de propagado por bloque y acarreo entrando a cada seccin de 4:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
46
Figura 4.4: Smbolo del bloque de suma de 4 bits. Con estos bloques bsicos no rest ms que alambrar las seales de salto de acarreo y acarreo entrando y nuestro sumador qued completo. Se incluy en el esquemtico la circuitera de prueba necesaria para verificar funcionalidad:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
47
Figura 4.5: Alambrado de los bloques 1 y 2 en el diagrama final. Con la ayuda de teclados y pantallas hexadecimales se aliment el circuito y verificaron sus salidas. Este es el sistema completo:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
48
Figura 4.6: Diagrama esquemtico completo del sumador de 32 bits. Las caractersticas de simulacin del sistema, se determinan por el archivo de tecnologa incluido en Microwind por defecto; esto se muestra en la siguiente tabla:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
49
Tabla 4.12: Parmetros de simulacin.
Se inici la simulacin y observ la lgica funcionando. Fue ilustrativo para el paralelismo del circuito observar como el salto por bloque se adelant al acarreo por bloque cuando se dieron secuencias de propagacin de ms de 6 bits.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
50
Figura 4.7: Imagen del simulador esquemtico en funcionamiento. Cada uno de los bloques constitutivos gener su propio listado de redes y archivo de Verilog, incluido el ms alto nivel de jerarqua que corresponde al circuito completo de 32 bits. Los parmetros de simulacin indicaron tiempos de retraso por compuerta y por interconexin de 0.02 y 0.07ns para el proceso de 2um.
4.3 Modelo de polgonos para plano fsico.
A partir del archivo de Verilog generado automticamente por Dsch, se compil el plano fsico para el sumador completo de 1 bit con generacin de propagado, observable en la figura 4.8:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
51
Figura 4.8: Plano fsico del sumador de 1 bit con generacin de propagado.
Se observ que el diseo automtico fue prcticamente serial, coloc los pines de entrada y salida en un solo costado de la malla de potencia y no comparti pistas de metal 2, an cuando son de dimensiones complementarias. Manualmente se procedi disminuir el ancho excesivo de lneas de M2. Esencial mente se recurri a compartir pistas de M2 entre las seales que tuviesen un largo complementario sobre la longitud del conjunto de celdas. Un beneficio asociado a la disminucin del ancho de las rutas fue la disminucin de la longitud total de interconexin, esto redujo resistencia y capacitancia. Los cambios se observan en la figura 4.9.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
52
Figura 4.9: Plano fsico del sumador de 1 con interconexin hecha a mano. Al expandir el arreglo en forma vertical, Carry comparti la pista de M1 con C facilitando la interconexin y ahorrando espacio entre las celdas. Tambin se elimin una serie de vas que no eran necesarias y nicamente aumentaban el retraso de transporte de las seales. A diferencia de la estructura que se gener automticamente a partir del V erilog, Se decidi utilizar la direccin horizontal como camino de datos y la vertical como camino crtico y de control. Aprovechando las mejoras que se hicieron, se alambraron las seales de interconexin de los bloques de 1 bit con M1 y con una menor cantidad de vas. Posteriormente se alinearon las celdas, de modo que cupieran 2 celdas por cada 3 barras de poder; la interconexin debe consumir el espacio de una barra. De esta manera se obtuvo el grupo de 4 interconectado que observamos en la figura 4.10:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
53
Figura 4.10: grupo de 4 interconectado. Se observ en el arreglo de 4 celdas, que este no cumpla con el espacio regular entre las barras de poder, estas estn separadas por 60 lambdas y las conexiones entre celdas no permitan mantener esa regularidad. Para solventar este problema se elimin el exceso de conexiones que rodeaban las celdas estndar y se aprovecharon espacios dentro de las celdas para colocar contactos. La estructura se redujo y permiti aprovechar la regularidad de la malla de tierra y fuente. El sumador de acarreo de 4 bits se convirti ahora en nuestro bloque lgico bsico, para
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
54
completarlo, nicamente hizo falta: la compuerta O que determina la entrada del acarreo saltado de la etapa previa el acarreo generado por la ultima tajada de 1 bit del bloque anterior y la serie de compuertas Y que determinan si el acarreo ha de saltar el bloque actual. Incluyendo dichas estructuras el bloque qued constituido como se observa en la figura 4.11:
Figura 4.11: Bloque de 4 bits con salto de acarreo y selector de acarreo entrando mejorado por interconexin. Se duplic la estructura y se efectuaron las conexiones necesarias, se obtuvo un bloque para 8 bits que se muestra en la figura 4.12. En este punto de la replicacin de bloques bsicos se hizo evidente la importancia de planear las conexiones terminales de cada bloque de 4 a modo de facilitar el diseo de las conexiones entre bloques.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
55
Figura 4.12: Sumador de 8 bits con lgica de salto de acarreo. En este bloque fsico aparecieron rutas mucho ms largas e irregulares. Esto fue irremediable, pero es bueno notar que es poco probable que se incremente la irregularidad a partir de este punto. Se lleg a un nivel de sde el cual crecer el arreglo de bloques fue muy sencillo. Finalmente se alambraron los 6 bloques restantes para obtener nuestro sumador de 32 bits. La regularidad de los bloques en el plano fsico ayud a hacer de esta tarea algo muy simple.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
56
Figura 4.13: sumador completo de 32bits y sus dimensiones finales. El rea final del diseo que se logr implementar es de 500 * 4200 lambdas, lo que en el proceso que se utiliz se traduce en 20000 * 168000um. La forma rectangular se escogi por ser la que ofrece el mismo camino de rutas para los datos entrando al sumador. Se pudo escoger una forma menos alargada haciendo crecer el arreglo de celdas en ambas direcciones y no solo en Y, pero la congestin de las rutas asociadas con A y B (vectores de entrada) consumiran el rea de M1. Para un proceso de 2 metales esto no es recomendable puesto que la mayor parte del ruteo debe darse en M1 y liberar M2 para rutas crticas o seales de control que tengan mayor distancia
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
57
entre terminales. Estas limitantes son las que influyeron en la decisin de aprovechar polisilicio de las compuertas como medio de liberar pistas de M1 para conexiones de datos. A causa de la manera en la que la librera estndar implementa las cabezas del polisilicio el utilizar las compuertas con interconexiones menores de hecho redujo la ruta total de seal a compuerta. Durante la simulacin de una de las versiones fsicas se detect un problema de diseo lgico no considerado en la primera lgica del sumador. La propagacin de un cero por la lnea de salto de acarreo era imposible. Aunque los libros de texto conectan el acarreo saliente de cada bloque de suma y el de salto a la siguiente etapa a travs de una compuerta O en la realidad esto no funciona. Cuando se da salto de acarreo pero el acarreo a pasar es cero la compuerta O sobrescribe el 0 Si se da el caso de que el bloque de propagacin tiene 1 en su acarreo final. Si todos los bloques internos del sumador fueron saltados en la operacin previa de suma, el cero se propagara a la velocidad de una propagacin sin salto de 31 bits cuando el acarreo 0 se gener en la posicin 0 del sumador. La solucin a esto es validar el acarreo de salida de los bloques de 4 con la seal de acarreo generado haciendo que el mximo numero de saltos sea 7 al igual que para el 1. La ecuacin de acarreo saliendo para cada bloque se dedujo de su correspondiente mapa K, a partir de las seales de acarreo entrando, saliendo generado y propagado y resulto as: Cnext = (Cpp * Ci)+(Cgg*Co) (4.11)
4.4 Anlisis de resultados.
A partir de un conjunto de seales regulares de frecuencia diferente se estableci un patrn binario de ondas de prueba. Utilizando este patrn se efectu la simulacin del diseo fsico. Las ondas se alimentaron a cada bloque funcional representativo de una etapa del diseo. Cabe notar que el resultado de estas simulaciones por etapas fue la influencia principal detrs de las ediciones del plano fsico. Los diferentes resultados fueron a la vez motor y validador de las mejoras de interconexin que se realizaron. La figura 4.14 muestra los resultados de la primera simulacin. El bloque sumador de 1 bit sintetizado se aliment con las seales de entrada visibles en las primeras lineas de la figura y se utiliz la misma herramienta para determinar los retrasos asociados a las seales.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
58
Figura 4.14: Diagrama de tiempos del sumador de 1 bit con generador de propagado. La herramienta nos permiti evaluar un retraso de 645ps entre los flancos de A y el respectivo punto medio en el flanco del acarreo. Se escogi el acarreo por ser la seal crtica de inters en nuestro caso. El bloque sinttico se volvi a simular luego de las ediciones de interconexin. La caracterstica principal que la edicin alter es el valor de las constantes de resistenc ia por capacitancia de cada malla de metal entre las salidas y las compuertas de los transistores. La manera en que estos parmetros se afectaron fue cambiando la longitud de los cables, ya sea acercando las barras de M2 al cuerpo de la lgica o alterando la cantidad de vas en una ruta. La figura 4.15 muestra las nuevas curvas de simulacin que reflejaron las mejoras hechas a la celda:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
59
Figura 4.15: Diagrama de tiempos del sumador de 1 bit con generador de propagado e interconexiones manuales. Se observ una mejora significativa en el tiempo de respuesta de la senal de acarreo, el nuevo retraso se midi en 460ps, esto represent un a mejora de 185ps. La magnitud de la variacin es importante especialmente por el hecho de que se logr efectuando cambios sencillos. Es de notar que a consecuencia de esta mejora el tempo de un acareo completo en grupo de 4 se redujo en cuatro veces la mejora de 1 bit. El diagrama de tiempos del bloque de 4 en su peor camino de retraso se muestra en la figura 4.12. Se gener un acarreo en la posicin menos significativa y se propag hasta el acarreo de la 4 tajada:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
60
Figura 4.16: Diagrama de tiempos del sumador de 4 bits: Se observ el acarreo propagndose por las distintas etapas y el retraso entre el segundo flanco creciente de A y el acarreo de 3 etapa C3; en este punto se determin en aproximadamente 3.04ns este retraso no slo reduce el tiempo valido de C3 dentro de una fase de B sino tambin contamina en 2.84ns el siguiente resultado. Este diagrama caracteriz el bloque bsico de 4 bits. Fue importante notar que la propagacin del 1 y la del 0 lgicos no son simtricas en el caso de acarreo generado y propagado. La caracterizacin en tiempos debe siempre tomar el peor caso. En este caso por eso se escogi 3.04ns como tiempo de propagacin del 1 lgico an cuando el acarreo por propagado fue simtrico con el cero. Recordemos que el peor caso de propagacin de acarreo se dio cuando se gener acarreo en la primera posicin de un bloque de 4 y se propag hasta la suma de la ltima posic in del siguiente bloque. En este caso no se habilit salto de acarreo en ninguno de los 2 bloques. Por la forma en que se gener la seal de propagado, el primer bloque no pudo tener acarreo entrando o habra sido saltado por este. Se efectu la simulacin de dicho caso en le plano fsico de l sumador de 8 bits. El vector de pruebas se aplic al bit menos significativo y el resto de entradas se dispusieron a modo de entrar en situacin de acarreo generado hasta la 7 entrada.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
61
Figura 4.17: Diagrama de tiempos del bloque de 8 bits propagando acarreo de la posicin cero a la suma de la posicin siete. En este caso el retraso a lo largo de 8 tajadas fue de 6.51ns despus del flanco incidente y 4.80ns luego de la cada de la seal. De esta manera se simul el peor caso de acarreo simple dentro de la arquitectura del sumador. Este retraso es parte del retraso mximo posible pero debera ocurrir en 2 partes al principio y al final del sumador. A partir de los bloques bsicos se construy el plano fsico para 32 bits. Del mismo modo que para las simulaciones anteriores se utiliz el vector de entradas en el bit menos significativo y se preparo el reto de las entradas para generar acarreo en todas las posiciones. De acuerdo a la construccin del sumador de salto de acarreo se simul su peor camino de propagacin a travs del primer bloque; el ltimo y toda la lnea de acarreo saltado. Las curvas de simulacin se presentan a continuacin:
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
62
Figura 4.18: Diagrama de tiempos de los acarreos generados por salto, por ltima entrada de cada bloque de 4 y suma de la posicin 31. El retraso observable entre el flanco incidente de A0 y S31 fue de 12ns al igual que el flanco de cada. Este retraso simtrico es el peor que se puede esperar del sumador y corresponde al retraso de propagacin de un uno y un cero respectivamente a lo largo de la cadena de salto de acarreo . Se observ en este punto un fenmeno importante, las curves representan en grupos los acarreos saliendo de cada grupo de 4 y entrando en su consecutivo, las pendientes de las curvas de entrada en la propagacin de cero mostraron una constante RC mayor. Es decir, las curvas de acarreo entrando presentaron flancos mas lentos en la transicin a cero que en la transicin a uno. La casi simetra de los tiempos de retraso facilit la de terminacin terica de una frecuencia mxima de operacin a partir de la frecuencia requerida por los vectores de entrada. El tiempo mnimo de ciclo se defini como el tiempo mximo de retraso del sumador adicionado el tiempo de preparacin del elemento de memoria que habra de leer el dato de salida. El tiempo de retraso se conoce en 12ns y el tiempo de preparacin del elemento de memoria se aproxima generalmente al retraso de 4T. Para este caso se us una mtrica ms conservadora, se decidi para asegurar que la salida fuese estable que el retrase constituyera menos de la mitad del ciclo. De esta manera se escogi 25ns como tiempo de ciclo a partir de 12ns de retraso, an cuando tericamente pudo ser bastante menor.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
63
CAPTULO 5: Conclusiones y recomendaciones 5.1 Conclusiones. El producto del trabajo que aqu se reporta fue un sumador completo de 32 bits con arquitectura de propagacin de acarreo por salto. De dicho dispositivo se crearon cuatro modelos diferentes, Cada modelo representa un nivel de abstraccin decreciente. Se creo un modelo de simulacin lgica que representa el comportamiento general del sistema. Este consiste de un arreglo de funciones Booleanas interdependientes que representan la lgica que constituira el sistema final. Como segundo modelo, se construy un diagrama esquemtico jerrquico. En este modelo se represent adems de la lgica del circuito una descripcin muy bsica de sus caractersticas elctricas. El tercer modelo es un mapa en lenguaje de descripcin de hardware. Dicho modelo represent las estructuras lgicas y las interconexiones al mismo nivel de abstraccin que el diagrama esquemtico. La diferencia esencial radic en que no se obtuvo una imagen grfica del sistema. El modelo final y menos abstracto es un grfico en polgonos que representan las estructuras que se construiran en le silicio para formar la mquina. En los casos de los modelos lgico, esquemtico y plano fsico, se aprovecharon las capacidades de simulacin que los editores respectivos proporcionaron. Desde un inicio se pretendi recorrer en el proceso de diseo las etapas generales que se siguen en la industria de microprocesadores. A grandes rasgos se efectu una subdivisin de las labores en cuatro etapas interdependientes y dinmicamente interactivas. Las cuatro etapas que se llegaron a reconocer fueron: El estudio de factibilidad micro arquitectnico y de circuitos, El modelado lgico y la verificacin de este modelo, El modelado esquemtico o en descripcin de estructuras y finalmente el diseo en plano fsico. Estas etapas ordenadas cronolgicamente en apariencia se nutrieron entre s en todo momento entre ellas se estableci una realimentacin continua. Todo este proceso que la metodologa presentaba como una secuencia ordenada result en una forma de ciclo desordenado que dio forma al producto final. Esto era de esperar y fue de hecho beneficioso para la agilidad del proceso. Todo el diseo aunque de complejidad moderada, logr realizarse sin problemas con las herramientas escogidas inicialmente. El programa de hoja de clculo Excel, mostr ser una herramienta sencilla de utilizar y muy efectiva, El paquete MICROWIND, DSCH2 result una plataforma excelente, con una razonable capacidad d simulacin. El funcionamiento del e sistema final comprob que para aplicaciones de moderada complejidad el paquete responde eficientemente. Se aprovech durante el proceso para experimentar con la facilidad del usuario novato de aprovechar la herramienta. Alcanzar el dominio del paquete result sencillo. La herramienta como utensilio acadmico fue excelente.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
64
Entrando en le detalle de los resultados de acuerdo a los objetivos especficos: Como se plante inicialmente, un esfuerzo considerable se dedic a recopilar informacin sobre las arquitecturas posibles a utilizar. Esta etapa de recoleccin terica no se menospreci. La decisin de implementar tal o cual arquitectura es determinante para todos los aspectos de desarrollo del proyecto. La arquitectura delimit la complejidad del sistema, la facilidad de simulacin, la cantidad de trabajo que requerira la creacin de los diferentes modelos, y por ende el tiempo que se invertira y la capacidad requerida de las herramientas de trabajo. Se compararon varias arquitecturas comunes y finalmente se decidi utilizar un sumador de salto de acarreo. El sumador, qued constituido en ocho bloques regulares de 4 bits. Cada uno opera independientemente como sumador de propagacin sencilla. Entre los sumadores posib les a escoger se decidi implementar el de salto de acarreo por su alta regularidad en plano fsico, desempeo razonablemente bueno, rea moderada y facilidad de sntesis en sus bloques ms sencillos. En resumen es una buena combinacin de caractersticas. Es muy adaptable a las herramientas disponibles pues no representa un grado de complejidad demasiado alto a ninguna de las etapas del diseo vertical. Esta suposicin inicial entreg fruto puesto que la implementacin, anlisis, validacin y comprensin de los diferentes modelos (lgico, fsico, esquemtico y cdice) fue relativamente simple y fcilmente comprensible. No requiere herramientas de alta complejidad o poder de cmputo ni muchas horas de trabajo lo cul se adapta a las condiciones de nuestro dispositivo electrnico hipottico.
Para juzgar los beneficios de las opciones arquitectnicas se estableci un conjunto de requerimientos que el sumador habra de cumplir. Se supuso inicialmente que se deseaba un dispositivo de uso general que reuniera la mayor cantidad de caractersticas que se buscan en un circuito integrado. Se buscaba sencillez de diseo e implementacin. Garantas de verificacin funcional. rea reducida tanto como fuese posible en el proceso a utilizar. Relativa rapidez (ancho de ba nda) del circuito. Consumo de corriente tan bajo como sea posible. Fue obvio desde el principio que todo conjunto de requerimientos conlleva un balance, y toda variable a la que le asign importancia, da otra variable. La arquitectura se escogi a modo de balancear los requerimientos por igual. No se escogi el ms veloz para poder tener regularidad fsica, ni el ms simple, para ahorrar tiempo de diseo. De la misma forma se le dio importancia a los dems requerimientos. La implementacin combinacional libre de reloj provoca que en las compuertas conmuten nicamente cuando las entradas de datos cambian. Los tiempos de propagacin de los caminos de datos pueden resultar en la aparicin de pulsos no deseados, pero en general el beneficio de no tener una ejecucin sincrnica es importante. El consumo de potencia no es puntual para el 100% de las compuertas lo que mejora la estabilidad de la red de distribucin de potencia en el rea del sumador y ayuda al bajo consumo y regulacin trmica. La posibilidad de enviar datos espalda con espalda al circuito, se conjuga con el tiempo que se gana por el salto de acarreo y los resultados de una rigurosa edicin manual, para aumentar un poco la frecuencia.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
65
Se intent mostrar claramente las etapas generales del pr oceso de diseo. La primera fue la escogencia de la arquitectura ms viable. La segunda etapa fue el modelado lgico. El modelo de hoja de clculo fue la herramienta ms poderosa descubierta a lo largo de este proceso de diseo, el simple y rudimentario modelo creado para el sumador es un burdo ejemplo muy limitado de la potencia de la herramienta. La facilidad de uso, diseo, adecuacin y la enorme gama de posibilidades de uso que se puede dar a los modelos es lo que ms impresion. Los modelos se presentan en un formato hbrido donde a la vez son fsicos, lgicos, conductuales y visuales. La hoja de clculo a su vez posee herramientas grficas que facilitan la visualizacin y representacin de los bloques bsicos de diseo. Los mltiples niveles de abstraccin tan tiles en el proceso de diseo vertical se representan con facilidad y todo el potencial de la programacin estructurada se ofrece al usuario. Es importante ver la analoga existente entre todos los procesos de diseo que utilizan estructuras regulares y paramtricas; como los programas de cmputo, los circuitos digitales, procesos industriales en planta y otros. Esto nos puede llevar a incluir en nuestros procesos de diseo herramientas muy eficientes y tiles como se aprendi en este caso. El modelado lgico hecho en hoja de clculo permite comprobar el funcionamiento, interconexin y forma fsica general del diseo. La creacin de este modelo requiri 10 horas hombre incluida su validacin y mejora. Y permite generar patrones aleatorios de prueba. El sumador se dise luego en el diagrama esquemtico con la herramienta Dsch2 y se gener un archivo de Verilog correspondiente. La importancia de ste modelo radic en que conjug la efectividad grfica de los esquemticos con una simulacin controlable. La jerarqua del esquemtico forma un sistema modular que muestra el nivel de granularidad requerida por el plano fsico. Las estructuras esquemticas empataron una a una con las estructuras de polgonos. Y el modelo permiti observar de primera mano el problema de la interconexin. El subproducto del modelo esquemtico es el Cdigo de Verilog. Microwind es capaz de sintetizar las estructuras de polgonos a partir de las lneas de cdigo. Esto permiti sintetizar con gran facilidad las estructura s bsicas del modelo fsico y crecer sobre ellas. El modelo esquemtico y de simulacin lgica tom un aproximado de 15 horas hombre y permite ejecutar una simulacin visual de entrada salida en forma interactiva. Con un retraso mximo de 17ns. Se rest importancia a estos resultados pues nicamente consideran retardos de compuerta normalizados y retardos de lnea de transmisin fijos. Cabe destacar que se compararon 3 diferentes herramientas de diseo, Microwind, DLS y Magic. Las tres son de libre ditribucin, Se escogi Microwind, por su facilidad de sintetizar Verilog y la simpleza de su interfaz, las otras herramientas habran requerido un tiempo de aprendizaje significativamente mayor adems de tener requerimientos computacionales elevados.
De las mltiples versiones de plano fsico que se crearon se destacan dos: La primera es una versin sinttica creada por el editor de polgonos Microwind a partir de la descripcin en lenguaje Verilog. La segunda es la versin diseada a mano a partir de celdas estndar IEEE que posee Microwind. El modelo sintetizado tom aproximadamente 2 segundos en generarse y desplegarse. En el caso del plano no sinttico de mejor desempeo el 100% de las compuertas
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
66
fueron modificadas de su forma original de librera por factores de interconexin. Se aprovech para ruteo el espacio interior de las celdas (entre las barras de poder). Una de las mejoras ms significativas fue el eliminar contactos innecesarios. Esto liber espacio en 2 metales para dibujar rutas ms directas.
El sumador tiene un retraso mximo total de 12ns. nicamente se utilizaron compuertas estndar y no se cambio el tamao a ningn transistor. Se utiliz modelado de transistores de nivel 3 en el proceso de 0.2um. El sumador cuenta con 686 transistores N y P por igual, toda la lgica es esttica complementaria. Los diagramas de tiempo fueron generados por el simulador de Microwind suponiendo voltaje de operacin de 5v a 25?C. El rea rectangular que ocupa es de 20000 * 160000um. El circuito utiliza 63 pistas de M1 entre una malla regular de fuente y tierra en tecnologa de 2 metales. El trabajo de diseo fsico implic 9 horas hombre que incluyen planeamiento de las tajadas de bits interconexin y prueba por simulacin. Esto es similar para cada uno d los 4 modelos no sintticos. Ya que se supuso un sistema de cola de ejecucin con e cada etapa enmarcada en un ciclo de reloj, podramos utilizar este sumador en un sistema a 400 MHz dnde los datos son vlidos a la entrada de la etapa de ejecucin durante todo un ciclo de reloj en este caso de 25ns de perodo. Podramos recuperar los datos a mitad de ese ciclo con un lector de flanco creciente en un esquema de reloj 0-1 bien al final del ciclo para que sea valido por todo el ciclo siguiente. La intencin de la latencia simtrica de la peor propagacin es poder utilizar el sistema con datos entrando en cada ciclo, espalda con espalda. En ambos casos se habr de asegurar que el retraso no influye en el tiempo de preparacin ni mantenimiento del secuencial de lectura. El sumador no necesita reloj, es totalmente combinacional. Una intencin bsica detrs de los modelos lgico, esquemtico y fsico es que sean modulares y puedan combinarse con modelos similares para facilitar la insercin del sistema en uno mayor.
5.2 Recomendaciones: Las herramientas Dsch, y Microwind son un excelente conjunto para aplicaciones acadmicas como en este caso. La modularidad de los diseos es importante por cuanto la capacidad de las herramientas en lo que a manejo de memor ia se refiere es limitada y diseos de muy grandes o de gran complejidad podran volverse prohibitivos. Aun as para efectos de este diseo fueron eficientes en grado sumo. Las capacidades de edicin fsica y esquemtica son excepcionales y fciles de dominar. La herramienta no se vuelve limitante para el diseador.
La simulacin se efectu a 25?C y 5v condiciones demasiado ideales. Estas entregaron una frecuencia mxima de entrada de datos espalda con espalda de 400 Mhz. Se recomienda 333Mhz para tomar en cuenta los efectos de la temperatura y tiempos de lectura ms realistas. Aunque 400Mhz es factible si se decide otorgar 2 ciclos de reloj al tiempo de ejecucin en la
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
67
cola. Se recomendada una mejor simulacin a voltaje menor y mayor temperatura. Se recomendaron 80C y 1.2V Es necesario encontrar maneras de cuantificar la potencia consumida considerando los retrasos de las etapas de suma. Mejoras al modelo lgico podran ayudar a simular estos fenmenos. La experiencia de este diseo reafirm la conviccin de que no se puede generar un plano fsico de calidad sin intervencin humana y menos con las nuevas tecnologas en las cuales la impedancia de la interconexin cada vez cobra ms importancia ante la de las difusiones. El uso de sintetizadores debera darse para generar un plano sobre el cual se trabaja con mayor facilidad y ms rpido que si se dibujase desde cero. nicamente con trabajo manual se puede aprovechar ms el rea y se puede mejorar el desempeo.
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
68
BIBLIOGRAFA Artculos de revistas: 1. Gurkayna, F.K. et al, Higher radix Kogge-Stone parallel prefix adder architectures IEEE CNF, Vol 5, 2000. 2. Srinivas, H.R. et al, A fast VLSI adder architecture. IEEE Journal of Solid-State Circuits, Vol 27 No5, 1997. 3. Liming X. et al A "flying-adder" architecture of frequency and phase synthesis with scalability, IEEE Transactions on Very Large Scale Integration (VLSI) Systems. Vol 10 No 5 ,2002 4. Kernhof, J et al High-speed CMOS adder and multiplier modules for digital signal processing in a semicustom environment, IEEE Journal of Solid-State Circuits, Vol 24 No 3, 1989. 5. Farooqui, A. et al, Area-time optimal adder with relative placement generator, Proceedings of the 2003 International Symposium on Circuits and Systems, 2003. ISCAS '03, Vol 5, No 1, 2003 6. Efstathiou, C. et al Ling adders in CMOS standard cell technologies, 9th International Conference on Electronics, Circuits and Systems, 2002,Vol 2, No 1, 2002. Libros: 7. Chandrakasan, A. et al. Design of high performance microprocessor circuits, 1a edicin, IEEE Press Editorial board, EEUU, 2001. 8. John, M. et al. Application specific integrated circuits, 1a edicin, Addison Wesley, EEUU, 2001. 9. Hennessey, J et al. Computer architecture a quantitative approach , 2a edicin, Morgan Kaufmann Publishers, Inc.,EEUU, 1996. 10. Sutherland, I. et al Logical Effort, 1a edicin, Morgan Kaufmann Publishers, Inc., 1999. 11. Thomas, D. et al. The verilog Hardware description lannguage, 4a edicin, Kluwer academic publishers,EEUU, 2001. 12. Weste N. et al. Principles of CMOS VLSI design., 2a edicin, Addison Wesley, EEUU, 1994. Pginas web: 13. Sicard Etienne Microwind et DSCH, http://www.microwind.org/
Agosto del 2004
IE-0502
Diseo de un sumador digital de 32 bits para circuitos integrados.
69
ANEXOS Referirse a los archivos en formato digital.
Agosto del 2004
Das könnte Ihnen auch gefallen
- 02 Framework de Ciberseguridad NIST CSF v1Dokument41 Seiten02 Framework de Ciberseguridad NIST CSF v1Miguel Reynaldo Callizaya Meave100% (2)
- TransformadoresDokument36 SeitenTransformadoreselvergonzalez1Noch keine Bewertungen
- PLC, Arduino y PicDokument13 SeitenPLC, Arduino y PicSamuel J. GamezNoch keine Bewertungen
- Ccna Semestre 1 Examen 10 (100%)Dokument8 SeitenCcna Semestre 1 Examen 10 (100%)rukismenNoch keine Bewertungen
- Procedimiento de Trabajo Mantención TransformadoresDokument4 SeitenProcedimiento de Trabajo Mantención Transformadoressalmo83:18Noch keine Bewertungen
- 08 - 0283 - CS La Voz Sobre IP Una Guia PracticaDokument122 Seiten08 - 0283 - CS La Voz Sobre IP Una Guia Practicasalmo83:18Noch keine Bewertungen
- Sistemas Eléctricos - Problemas de Transformadores TrifásicosDokument4 SeitenSistemas Eléctricos - Problemas de Transformadores Trifásicossalmo83:18Noch keine Bewertungen
- EODokument129 SeitenEOAbraham CandelariaNoch keine Bewertungen
- 08 - 0297 - EO Simulador para Estudio de Comportamiento Relacion Señal Ruido en Transmision de DatosDokument196 Seiten08 - 0297 - EO Simulador para Estudio de Comportamiento Relacion Señal Ruido en Transmision de Datossalmo83:18Noch keine Bewertungen
- 08 - 0303 - EO Procedimiento para El Estudio de La Potencia Electrica para Reducir Costos de Operacion y MantenimientoDokument143 Seiten08 - 0303 - EO Procedimiento para El Estudio de La Potencia Electrica para Reducir Costos de Operacion y Mantenimientosalmo83:18Noch keine Bewertungen
- 5 Grito San JoseDokument2 Seiten5 Grito San Josesalmo83:18Noch keine Bewertungen
- 08 - 0304 - EO Diseño de Aplicaciones Virtuales para El Analisis Preliminar de Los Sistemas Automaticos de Control Implementadas en LABVIEWDokument127 Seiten08 - 0304 - EO Diseño de Aplicaciones Virtuales para El Analisis Preliminar de Los Sistemas Automaticos de Control Implementadas en LABVIEWsalmo83:18Noch keine Bewertungen
- 08 - 0290 - EO Diseño de Un Modelo de Simulacion para Enseñanza de Electronica Utilizando Software LABVIEWDokument161 Seiten08 - 0290 - EO Diseño de Un Modelo de Simulacion para Enseñanza de Electronica Utilizando Software LABVIEWsalmo83:18Noch keine Bewertungen
- 08 - 0302 - CS Los Siete Habitos de Los Sitios Web Altamente EfectivosDokument267 Seiten08 - 0302 - CS Los Siete Habitos de Los Sitios Web Altamente Efectivossalmo83:18Noch keine Bewertungen
- Redes InalambricasDokument116 SeitenRedes InalambricasFrancisco MedinaNoch keine Bewertungen
- 08 - 0301 - EO Diseño de Un Punto de Acceso Bluetooth para El Envio de Datos Bajo Demanda y Por Difusion SelectivaDokument144 Seiten08 - 0301 - EO Diseño de Un Punto de Acceso Bluetooth para El Envio de Datos Bajo Demanda y Por Difusion Selectivasalmo83:18Noch keine Bewertungen
- 08 - 0299 - EO Analisis de Redes Inhalambricas Su ImplementacionDokument193 Seiten08 - 0299 - EO Analisis de Redes Inhalambricas Su Implementacionsalmo83:18Noch keine Bewertungen
- 08 - 0296 - EO Estrategias para Aplicacion de Recursos de Red 2G para Mejorar Desempeño de Red 3G y Del Servicio de Telefonia CelularDokument220 Seiten08 - 0296 - EO Estrategias para Aplicacion de Recursos de Red 2G para Mejorar Desempeño de Red 3G y Del Servicio de Telefonia Celularsalmo83:18Noch keine Bewertungen
- 08 - 0296 - CS Internet Por Red ElectricaDokument107 Seiten08 - 0296 - CS Internet Por Red Electricasalmo83:18Noch keine Bewertungen
- Redes de conmutación de circuitos y softswitchDokument159 SeitenRedes de conmutación de circuitos y softswitchsalmo83:18Noch keine Bewertungen
- 08 - 0283 - EO Diseño e Implementacion de Un Electrocardiografo Portatil y Del Procesamiento Digital de Las SeñalesDokument135 Seiten08 - 0283 - EO Diseño e Implementacion de Un Electrocardiografo Portatil y Del Procesamiento Digital de Las Señalessalmo83:18Noch keine Bewertungen
- 08 - 0262 - M Consideraciones para El Diseño de Cuartos Refrigerados para Alta y Baja T°Dokument188 Seiten08 - 0262 - M Consideraciones para El Diseño de Cuartos Refrigerados para Alta y Baja T°salmo83:18Noch keine Bewertungen
- Redes InalambricasDokument116 SeitenRedes InalambricasFrancisco MedinaNoch keine Bewertungen
- 08 - 0262 - M Consideraciones para El Diseño de Cuartos Refrigerados para Alta y Baja T°Dokument188 Seiten08 - 0262 - M Consideraciones para El Diseño de Cuartos Refrigerados para Alta y Baja T°salmo83:18Noch keine Bewertungen
- 08 - 0264 - M Guia para El Calculo Diseño y Fabricacion de Construciones SoldadasDokument425 Seiten08 - 0264 - M Guia para El Calculo Diseño y Fabricacion de Construciones Soldadassalmo83:18Noch keine Bewertungen
- 08 - 0264 - EO Optimizacion de La Generacion de Planta HidroelectricaDokument181 Seiten08 - 0264 - EO Optimizacion de La Generacion de Planta Hidroelectricasalmo83:18Noch keine Bewertungen
- 08 - 0264 - M Guia para El Calculo Diseño y Fabricacion de Construciones SoldadasDokument425 Seiten08 - 0264 - M Guia para El Calculo Diseño y Fabricacion de Construciones Soldadassalmo83:18Noch keine Bewertungen
- Redes de conmutación de circuitos y softswitchDokument159 SeitenRedes de conmutación de circuitos y softswitchsalmo83:18Noch keine Bewertungen
- 08 - 0264 - EO Optimizacion de La Generacion de Planta HidroelectricaDokument181 Seiten08 - 0264 - EO Optimizacion de La Generacion de Planta Hidroelectricasalmo83:18Noch keine Bewertungen
- 08 - 0270 - EO Asesoria Tecnica para El Mejoramiento y Ampliacion de Señal de RadiofrecuenciaDokument237 Seiten08 - 0270 - EO Asesoria Tecnica para El Mejoramiento y Ampliacion de Señal de Radiofrecuenciasalmo83:18Noch keine Bewertungen
- Aplicación medidor electrónico energía GuatemalaDokument161 SeitenAplicación medidor electrónico energía Guatemalasalmo83:18Noch keine Bewertungen
- 08 - 0273 - CS Utilizacion de Tecnicas de Auditoria Asistidas Por ComputadorDokument92 Seiten08 - 0273 - CS Utilizacion de Tecnicas de Auditoria Asistidas Por Computadorsalmo83:18Noch keine Bewertungen
- 08 - 0269 - M Soldabilidad de Los AcerosDokument113 Seiten08 - 0269 - M Soldabilidad de Los Acerossalmo83:18Noch keine Bewertungen
- Copia de Copia de FR-PY-12 Protocolo - Verificación Del Sistema de Aire Acondicionado v4Dokument3 SeitenCopia de Copia de FR-PY-12 Protocolo - Verificación Del Sistema de Aire Acondicionado v4Calderón InésNoch keine Bewertungen
- MS Word historia y versionesDokument3 SeitenMS Word historia y versionesNicoll RizoNoch keine Bewertungen
- Diferencia Entre Un Traductor y Un Compilador PDFDokument6 SeitenDiferencia Entre Un Traductor y Un Compilador PDFBenjamin Viramontes JuarezNoch keine Bewertungen
- Sistemas Operativos InfoDokument143 SeitenSistemas Operativos InfoWilliam Aldair Cañas MartinezNoch keine Bewertungen
- Manual Configuracion ElastixDokument13 SeitenManual Configuracion ElastixJoan ViloriaNoch keine Bewertungen
- 02 Instala APA 6 en Word2010 o MenorDokument3 Seiten02 Instala APA 6 en Word2010 o MenorLuis Argueta MogollónNoch keine Bewertungen
- Mapa Conceptual de ArañaDokument1 SeiteMapa Conceptual de ArañaGEOVANNY ISRAEL DE LA TORRE OLEASNoch keine Bewertungen
- Tema BUSES PDFDokument72 SeitenTema BUSES PDFJuanjo herrera arandaNoch keine Bewertungen
- Easy UPS On-Line - SRV1KADokument3 SeitenEasy UPS On-Line - SRV1KADaniel BarriosNoch keine Bewertungen
- GLOSARIODokument25 SeitenGLOSARIOWilson FonsecaNoch keine Bewertungen
- Contadores PLCDokument10 SeitenContadores PLCLuis Angel Soto EscribaNoch keine Bewertungen
- Az 104 Parte 3Dokument259 SeitenAz 104 Parte 3CopyrightFreMusicNoch keine Bewertungen
- Tipos de memoria ROM: ROM, PROM, EPROM, EEPROM y sus característicasDokument2 SeitenTipos de memoria ROM: ROM, PROM, EPROM, EEPROM y sus característicasMerin MerinNoch keine Bewertungen
- Analisis de La Arquitectura Interna Del Pic16f887Dokument12 SeitenAnalisis de La Arquitectura Interna Del Pic16f887jared porfirioNoch keine Bewertungen
- Metodologias para El Desarrollo de Software Modelo RadialDokument31 SeitenMetodologias para El Desarrollo de Software Modelo RadialDiego HNoch keine Bewertungen
- PIC Introduccion A Los MicrocontroladoresDokument79 SeitenPIC Introduccion A Los MicrocontroladoresWilliam GutierrezNoch keine Bewertungen
- Validaciones - CurpDokument10 SeitenValidaciones - CurpElohpi Tika-RoseNoch keine Bewertungen
- Topologías de Redes PDHDokument9 SeitenTopologías de Redes PDHLozano Sanchez Miguel AngelNoch keine Bewertungen
- Practica 5Dokument7 SeitenPractica 5gestradag-1Noch keine Bewertungen
- Bascula SEN 5500 AluazDokument8 SeitenBascula SEN 5500 AluazEdelmer Vivero GraciaNoch keine Bewertungen
- Project 2013.Dokument11 SeitenProject 2013.Anonymous YPZpkJNoch keine Bewertungen
- Curso Hacking Android Windows Kali LinuxDokument2 SeitenCurso Hacking Android Windows Kali Linuxjose luis parra0% (1)
- TOOp2 PDFDokument13 SeitenTOOp2 PDFClaudia GuerreroNoch keine Bewertungen
- Data ModelerDokument18 SeitenData ModelerXxHonJxXNoch keine Bewertungen
- Convertidor, Decimal - Binario - Hexadecimal - Octal - Jose German Torres CalvaDokument3 SeitenConvertidor, Decimal - Binario - Hexadecimal - Octal - Jose German Torres CalvaGerman MattNoch keine Bewertungen
- SP85 RevF UserGde 59064 es-ESDokument122 SeitenSP85 RevF UserGde 59064 es-ESRodrigo caballeroNoch keine Bewertungen
- Programacion VHDL Con (PLD)Dokument61 SeitenProgramacion VHDL Con (PLD)Luis Fernando BravoNoch keine Bewertungen