Das könnte Ihnen auch gefallen
- Lecture Notes On Differential EquationsDokument156 SeitenLecture Notes On Differential EquationsAyesha KhanNoch keine Bewertungen
- Introduction To Algebraic Geometry - Dolgachev PDFDokument198 SeitenIntroduction To Algebraic Geometry - Dolgachev PDFDavidNoch keine Bewertungen
- A Study On School DropoutsDokument6 SeitenA Study On School DropoutsApam BenjaminNoch keine Bewertungen
- Cyclotomic PolynomialsDokument13 SeitenCyclotomic PolynomialsPh HuyamNoch keine Bewertungen
- A General Approach To Derivative Calculation Using WaveletDokument9 SeitenA General Approach To Derivative Calculation Using WaveletDinesh ZanwarNoch keine Bewertungen
- HJB EquationsDokument38 SeitenHJB EquationsbobmezzNoch keine Bewertungen
- On The Geometry of Grassmannians and The Symplectic Group: The Maslov Index and Its ApplicationsDokument177 SeitenOn The Geometry of Grassmannians and The Symplectic Group: The Maslov Index and Its ApplicationsMiguel OrrilloNoch keine Bewertungen
- The Riccati EquationDokument345 SeitenThe Riccati EquationfisikaNoch keine Bewertungen
- Bob Coecke - Quantum Information-Flow, Concretely, AbstractlyDokument17 SeitenBob Coecke - Quantum Information-Flow, Concretely, AbstractlyGholsasNoch keine Bewertungen
- Lecture 3 EigenvaluesDokument38 SeitenLecture 3 EigenvaluesRamzan8850Noch keine Bewertungen
- Test Strategy DocumentDokument10 SeitenTest Strategy DocumentshahidJambagiNoch keine Bewertungen
- Oxygen Cycle: PlantsDokument3 SeitenOxygen Cycle: PlantsApam BenjaminNoch keine Bewertungen
- Topological Quantum Field Theory - WikipediaDokument49 SeitenTopological Quantum Field Theory - WikipediaBxjdduNoch keine Bewertungen
- Boarding PassDokument1 SeiteBoarding Passagoyal5145Noch keine Bewertungen
- Basic Elements of Queueing Theory Lec Notes Philippe NAINDokument110 SeitenBasic Elements of Queueing Theory Lec Notes Philippe NAINjoystick2inNoch keine Bewertungen
- Random MatricesDokument27 SeitenRandom MatricesolenobleNoch keine Bewertungen
- App.A - Detection and Estimation in Additive Gaussian Noise PDFDokument55 SeitenApp.A - Detection and Estimation in Additive Gaussian Noise PDFLê Dương LongNoch keine Bewertungen
- An Invitation To General Algebra and Invitation To Construction 3.0Dokument469 SeitenAn Invitation To General Algebra and Invitation To Construction 3.0Debraj SarkarNoch keine Bewertungen
- Lecture Notes in Mathematics: 240 Adalbert KerberDokument197 SeitenLecture Notes in Mathematics: 240 Adalbert KerberbabakmiNoch keine Bewertungen
- CW ComplexesDokument6 SeitenCW ComplexesBa NguyenNoch keine Bewertungen
- Lecture 23Dokument38 SeitenLecture 23Azhar MahmoodNoch keine Bewertungen
- Dynamical Systems Method for Solving Nonlinear Operator EquationsVon EverandDynamical Systems Method for Solving Nonlinear Operator EquationsBewertung: 5 von 5 Sternen5/5 (1)
- Linear Dynamical Systems - Course ReaderDokument414 SeitenLinear Dynamical Systems - Course ReaderTraderCat SolarisNoch keine Bewertungen
- Probability and Geometry On Groups Lecture Notes For A Graduate CourseDokument209 SeitenProbability and Geometry On Groups Lecture Notes For A Graduate CourseChristian Bazalar SalasNoch keine Bewertungen
- Exercises For Stochastic CalculusDokument85 SeitenExercises For Stochastic CalculusA.Benhari100% (2)
- MATH2045: Vector Calculus & Complex Variable TheoryDokument50 SeitenMATH2045: Vector Calculus & Complex Variable TheoryAnonymous 8nJXGPKnuW100% (2)
- Categorical Operational PhysicsDokument181 SeitenCategorical Operational PhysicswrdoNoch keine Bewertungen
- Professor Emeritus K. S. Spiegler Auth. Principles of Energetics Based On Applications de La Thermodynamique Du Non Équilibre by P. Chartier M. Gross and K. S. Spiegler Springer Verlag Berlin Hei1Dokument172 SeitenProfessor Emeritus K. S. Spiegler Auth. Principles of Energetics Based On Applications de La Thermodynamique Du Non Équilibre by P. Chartier M. Gross and K. S. Spiegler Springer Verlag Berlin Hei1bigdevil11Noch keine Bewertungen
- Stochastic Modelling 2000-2004Dokument189 SeitenStochastic Modelling 2000-2004Brian KufahakutizwiNoch keine Bewertungen
- Classical Descriptive Set Theory: 1.1 Topological and Metric SpacesDokument14 SeitenClassical Descriptive Set Theory: 1.1 Topological and Metric SpacesKarn KumarNoch keine Bewertungen
- Harmonic Analysis and Rational ApproximationDokument307 SeitenHarmonic Analysis and Rational ApproximationياسينبوهراوةNoch keine Bewertungen
- Quadratic Form Theory and Differential EquationsVon EverandQuadratic Form Theory and Differential EquationsNoch keine Bewertungen
- Sylvester Criterion For Positive DefinitenessDokument4 SeitenSylvester Criterion For Positive DefinitenessArlette100% (1)
- Milne - Fields and Galois TheoryDokument111 SeitenMilne - Fields and Galois TheoryDavid FerreiraNoch keine Bewertungen
- Mathematica SolutionDokument38 SeitenMathematica SolutionShakeel Ahmad KasuriNoch keine Bewertungen
- Part1 20180910.13500.1596979305.4946 PDFDokument94 SeitenPart1 20180910.13500.1596979305.4946 PDFpattrapong pongpattraNoch keine Bewertungen
- Chaos NotesDokument395 SeitenChaos NotessunrababNoch keine Bewertungen
- Hopf Bifurcation Normal FormDokument3 SeitenHopf Bifurcation Normal FormJohnv13100% (2)
- Statistical Signal ProcessingDokument125 SeitenStatistical Signal Processingchegu.balaji100% (3)
- Stochastic Process by J Medhi PDFDokument2 SeitenStochastic Process by J Medhi PDFgauravroongta0% (2)
- Lab 04 Eigen Value Partial Pivoting and Elimination PDFDokument12 SeitenLab 04 Eigen Value Partial Pivoting and Elimination PDFUmair Ali ShahNoch keine Bewertungen
- Ma Thematic A Cheat SheetDokument2 SeitenMa Thematic A Cheat Sheetlpauling100% (1)
- Dynamic Programming Value IterationDokument36 SeitenDynamic Programming Value Iterationernestdautovic100% (1)
- Math CatalogDokument24 SeitenMath Catalogrrockel0% (1)
- Eigenvalues and Eigen Vector SlidesDokument41 SeitenEigenvalues and Eigen Vector SlidesMayur GhatgeNoch keine Bewertungen
- Ex4 Tutorial - Forward and Back-PropagationDokument20 SeitenEx4 Tutorial - Forward and Back-PropagationAnandNoch keine Bewertungen
- MSM Specification: Discrete TimeDokument5 SeitenMSM Specification: Discrete TimeNicolas MarionNoch keine Bewertungen
- The Hopf Bifurcation: Maple SolutionDokument5 SeitenThe Hopf Bifurcation: Maple Solutionghouti ghouti100% (1)
- MIT - Stochastic ProcDokument88 SeitenMIT - Stochastic ProccosmicduckNoch keine Bewertungen
- Project MphilDokument64 SeitenProject Mphilrameshmaths_aplNoch keine Bewertungen
- Nge KuttaDokument10 SeitenNge Kuttaaislah_1Noch keine Bewertungen
- Chapter 17 PDFDokument10 SeitenChapter 17 PDFChirilicoNoch keine Bewertungen
- Tuyeras Thesis 1 03 PDFDokument353 SeitenTuyeras Thesis 1 03 PDFDaniel AlejandroNoch keine Bewertungen
- Lecture Notes On Graph TheoryDokument99 SeitenLecture Notes On Graph TheoryAjith SureshNoch keine Bewertungen
- Nonlinear Control, Supplementary Notes To Khalil's Nonlinear Systems - Rafael WisniewskiDokument19 SeitenNonlinear Control, Supplementary Notes To Khalil's Nonlinear Systems - Rafael WisniewskiMustafa KösemNoch keine Bewertungen
- Problems and Solutions in Real and Complex AnalysiDokument82 SeitenProblems and Solutions in Real and Complex AnalysiahjeNoch keine Bewertungen
- Speech Signal ProcessingDokument135 SeitenSpeech Signal Processingqwwq215Noch keine Bewertungen
- Gröbner Bases Tutorial I - Slides PDFDokument40 SeitenGröbner Bases Tutorial I - Slides PDFAnonymous Tph9x741Noch keine Bewertungen
- On The Sum of The K Largest Eigenvalues of A Symmetric MatrixDokument5 SeitenOn The Sum of The K Largest Eigenvalues of A Symmetric MatrixsmashouffNoch keine Bewertungen
- Counting of Ring HomomorphismDokument122 SeitenCounting of Ring HomomorphismUnos0% (1)
- Vector-Valued Optimization Problems in Control TheoryVon EverandVector-Valued Optimization Problems in Control TheoryNoch keine Bewertungen
- Nitrogen Cycle: Ecological FunctionDokument8 SeitenNitrogen Cycle: Ecological FunctionApam BenjaminNoch keine Bewertungen
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenDokument12 SeitenCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminNoch keine Bewertungen
- Research ProposalDokument6 SeitenResearch ProposalApam BenjaminNoch keine Bewertungen
- Multivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Dokument8 SeitenMultivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Apam BenjaminNoch keine Bewertungen
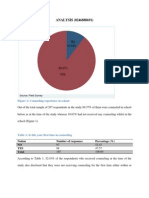
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolDokument8 SeitenANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminNoch keine Bewertungen
- Lecture6 Module2 Anova 1Dokument10 SeitenLecture6 Module2 Anova 1Apam BenjaminNoch keine Bewertungen
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsDokument14 SeitenHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminNoch keine Bewertungen
- Finish WorkDokument116 SeitenFinish WorkApam BenjaminNoch keine Bewertungen
- Lecture4 Module2 Anova 1Dokument9 SeitenLecture4 Module2 Anova 1Apam BenjaminNoch keine Bewertungen
- Evaluating The Effects of The National Health Insurance Act in Ghana: BaselineDokument75 SeitenEvaluating The Effects of The National Health Insurance Act in Ghana: BaselineApam BenjaminNoch keine Bewertungen
- Lecture5 Module2 Anova 1Dokument9 SeitenLecture5 Module2 Anova 1Apam BenjaminNoch keine Bewertungen
- PLMDokument5 SeitenPLMApam BenjaminNoch keine Bewertungen
- Personal Information: Curriculum VitaeDokument6 SeitenPersonal Information: Curriculum VitaeApam BenjaminNoch keine Bewertungen
- Project ReportsDokument31 SeitenProject ReportsBilal AliNoch keine Bewertungen
- l.4. Research QuestionsDokument1 Seitel.4. Research QuestionsApam BenjaminNoch keine Bewertungen
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaDokument7 SeitenRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminNoch keine Bewertungen
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteDokument1 SeiteMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminNoch keine Bewertungen
- Tutorials in Statistics - Chapter 4 NewDokument11 SeitenTutorials in Statistics - Chapter 4 NewApam BenjaminNoch keine Bewertungen
- Trapezoidal Rule EditedDokument3 SeitenTrapezoidal Rule EditedApam BenjaminNoch keine Bewertungen
- Comparison of Chi-Square and Likelihood Ratio Chi-Square Tests: Power of TestDokument3 SeitenComparison of Chi-Square and Likelihood Ratio Chi-Square Tests: Power of TestApam BenjaminNoch keine Bewertungen
- Unit 2 CST Review InequalitiesDokument2 SeitenUnit 2 CST Review InequalitiesMisterLemusNoch keine Bewertungen
- ITIL v3 CSI Sample Questions2Dokument35 SeitenITIL v3 CSI Sample Questions2kultiwett100% (1)
- HP Deskjet F2100 All-in-One Series: Basics GuideDokument17 SeitenHP Deskjet F2100 All-in-One Series: Basics GuideTaoufiq YasNoch keine Bewertungen
- XPath Extension FunctionsDokument69 SeitenXPath Extension FunctionsAlfaNoch keine Bewertungen
- Programmable Array Logic (Denil)Dokument15 SeitenProgrammable Array Logic (Denil)VD-ALL IN ONENoch keine Bewertungen
- Post Codes of BhutanDokument4 SeitenPost Codes of BhutanGyamba Dukpa50% (2)
- Evermotion Archmodels Vol 54 PDFDokument2 SeitenEvermotion Archmodels Vol 54 PDFKimberlyNoch keine Bewertungen
- ENG Change Order ProcessDokument2 SeitenENG Change Order Processsoureddy1981Noch keine Bewertungen
- Introduction To deDokument49 SeitenIntroduction To deJacinto SiqueiraNoch keine Bewertungen
- EFIS002 Fall 06Dokument52 SeitenEFIS002 Fall 06padmarao1Noch keine Bewertungen
- FTang C310 17-04-19Dokument4 SeitenFTang C310 17-04-19bolsjhevikNoch keine Bewertungen
- Fuzzy Ideals and Fuzzy Quasi-Ideals in Ternary Semirings: J. Kavikumar and Azme Bin KhamisDokument5 SeitenFuzzy Ideals and Fuzzy Quasi-Ideals in Ternary Semirings: J. Kavikumar and Azme Bin KhamismsmramansrimathiNoch keine Bewertungen
- An Approach To Detect Remote Access Trojan in The Early Stage of CommunicationDokument8 SeitenAn Approach To Detect Remote Access Trojan in The Early Stage of CommunicationDeri AndhanyNoch keine Bewertungen
- SRIM Setup MessageDokument3 SeitenSRIM Setup MessageRicardo Bim100% (1)
- HDL Description of AluDokument8 SeitenHDL Description of AluRavi HattiNoch keine Bewertungen
- Nilesh Roy ResumeDokument6 SeitenNilesh Roy ResumeNilesh RoyNoch keine Bewertungen
- UsingDokument28 SeitenUsingCristo_Alanis_8381Noch keine Bewertungen
- Use Python & R With ReticulateDokument2 SeitenUse Python & R With ReticulateDipanwita BhuyanNoch keine Bewertungen
- Brocade Icx7x50 Stacking DPDokument83 SeitenBrocade Icx7x50 Stacking DPAshutosh SrivastavaNoch keine Bewertungen
- Digital Marketing Scope and Career OpportunitiesDokument15 SeitenDigital Marketing Scope and Career Opportunitiesarunmittal1985Noch keine Bewertungen
- UGC NET Answer Key Home Science - July 2016 UGC NET JULY 2016 - CBSE-NETDokument5 SeitenUGC NET Answer Key Home Science - July 2016 UGC NET JULY 2016 - CBSE-NETsubirNoch keine Bewertungen
- pcm5121 PDFDokument121 Seitenpcm5121 PDFdubby trap4Noch keine Bewertungen
- A Star Search PDFDokument6 SeitenA Star Search PDFtechwizseetha100% (1)
- C Programming Lab Manual by Om Prakash MahatoDokument7 SeitenC Programming Lab Manual by Om Prakash MahatoAnonymous 4iFUXUTNoch keine Bewertungen
- Computer Lab Rules-SecondaryDokument2 SeitenComputer Lab Rules-SecondaryEli90099Noch keine Bewertungen
- Raghavendra Rao: Sap-Abap/4 ConsultantDokument3 SeitenRaghavendra Rao: Sap-Abap/4 ConsultantKapil SharmaNoch keine Bewertungen
- MA-2018Dokument261 SeitenMA-2018Dr Luis e Valdez rico0% (1)
- Yoni Miller - Invariance-PrincipleDokument4 SeitenYoni Miller - Invariance-PrincipleElliotNoch keine Bewertungen