Das könnte Ihnen auch gefallen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Brazilian Crisis OF 1998-1999: ORIGINS: and ConsequencesDokument42 SeitenThe Brazilian Crisis OF 1998-1999: ORIGINS: and ConsequencesJoab Dan Valdivia CoriaNoch keine Bewertungen
- Microfoundations of A Monetary Policy Rule, Poole's Rule: SSRN Electronic Journal April 2019Dokument45 SeitenMicrofoundations of A Monetary Policy Rule, Poole's Rule: SSRN Electronic Journal April 2019Joab Dan Valdivia CoriaNoch keine Bewertungen
- Graduate Macro Theory II: The Real Business Cycle Model: Eric Sims University of Notre Dame Spring 2017Dokument25 SeitenGraduate Macro Theory II: The Real Business Cycle Model: Eric Sims University of Notre Dame Spring 2017Joab Dan Valdivia CoriaNoch keine Bewertungen
- Weighted Nadaraya-Watson Regression Estimation: Statistics & Probability Letters February 2001Dokument13 SeitenWeighted Nadaraya-Watson Regression Estimation: Statistics & Probability Letters February 2001Joab Dan Valdivia CoriaNoch keine Bewertungen
- COVID-19 Pandemic in Bolivia - Wikipedia PDFDokument18 SeitenCOVID-19 Pandemic in Bolivia - Wikipedia PDFJoab Dan Valdivia CoriaNoch keine Bewertungen
- Stata PresentacionDokument109 SeitenStata PresentacionJoab Dan Valdivia CoriaNoch keine Bewertungen
- Monetary PolicyDokument30 SeitenMonetary PolicyJoab Dan Valdivia CoriaNoch keine Bewertungen
- Gls Int Macro PDFDokument1.018 SeitenGls Int Macro PDFJoab Dan Valdivia CoriaNoch keine Bewertungen
- Estimating A Vecm in StataDokument3 SeitenEstimating A Vecm in StataJoab Dan Valdivia CoriaNoch keine Bewertungen
- Myrdal's Analysis of Monetary Equilibrium Author(s) : G. L. S. Shackle Source: Oxford Economic Papers, No. 7 (Mar., 1945), Pp. 47-66 Published By: Stable URL: Accessed: 20/06/2014 21:46Dokument21 SeitenMyrdal's Analysis of Monetary Equilibrium Author(s) : G. L. S. Shackle Source: Oxford Economic Papers, No. 7 (Mar., 1945), Pp. 47-66 Published By: Stable URL: Accessed: 20/06/2014 21:46Joab Dan Valdivia CoriaNoch keine Bewertungen
- 2015 AprilDokument37 Seiten2015 AprilJoab Dan Valdivia CoriaNoch keine Bewertungen
- The B.E. Journal of Macroeconomics: TopicsDokument30 SeitenThe B.E. Journal of Macroeconomics: TopicsJoab Dan Valdivia CoriaNoch keine Bewertungen
- Financial Systems and Income Inequality: Joana Elisa MALDONADODokument40 SeitenFinancial Systems and Income Inequality: Joana Elisa MALDONADOJoab Dan Valdivia CoriaNoch keine Bewertungen
- WP Tse 983Dokument64 SeitenWP Tse 983Joab Dan Valdivia CoriaNoch keine Bewertungen
- Guide PDFDokument8 SeitenGuide PDFJoab Dan Valdivia CoriaNoch keine Bewertungen
- Accounting For Differences in Aggregate State ProductivityDokument21 SeitenAccounting For Differences in Aggregate State ProductivityJoab Dan Valdivia CoriaNoch keine Bewertungen
- Stata - Outreg CommandDokument16 SeitenStata - Outreg CommandCagri YildirimNoch keine Bewertungen
- The Basic RBC Model With Dynare: Petros Varthalitis December 2010Dokument11 SeitenThe Basic RBC Model With Dynare: Petros Varthalitis December 2010Joab Dan Valdivia CoriaNoch keine Bewertungen
- Estimating House Price Appreciation: A Comparison of MethodsDokument15 SeitenEstimating House Price Appreciation: A Comparison of MethodsJoab Dan Valdivia CoriaNoch keine Bewertungen
- 34 2017 Eusepi PrestonDokument42 Seiten34 2017 Eusepi PrestonJoab Dan Valdivia CoriaNoch keine Bewertungen
- Outreg Help PagesDokument16 SeitenOutreg Help PagesJoab Dan Valdivia CoriaNoch keine Bewertungen
- DynareDokument28 SeitenDynareJoab Dan Valdivia CoriaNoch keine Bewertungen
- Could A Monetary Base Rule Have Prevented The Great Demession?Dokument24 SeitenCould A Monetary Base Rule Have Prevented The Great Demession?Joab Dan Valdivia CoriaNoch keine Bewertungen
- Oreign Shocks in An Estimated Multi Sector ModelDokument29 SeitenOreign Shocks in An Estimated Multi Sector ModelJoab Dan Valdivia CoriaNoch keine Bewertungen
- International Journal of Forecasting: Marcin Kolasa Michał RubaszekDokument19 SeitenInternational Journal of Forecasting: Marcin Kolasa Michał RubaszekJoab Dan Valdivia CoriaNoch keine Bewertungen
- Ruge Murcia PDFDokument43 SeitenRuge Murcia PDFJoab Dan Valdivia CoriaNoch keine Bewertungen
- Determinants of Financial Inclusion in Mexico Based On The 2012 National Financial Inclusion Survey (ENIF)Dokument31 SeitenDeterminants of Financial Inclusion in Mexico Based On The 2012 National Financial Inclusion Survey (ENIF)Joab Dan Valdivia CoriaNoch keine Bewertungen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Experiment SCDokument5 SeitenExperiment SCnitinmgNoch keine Bewertungen
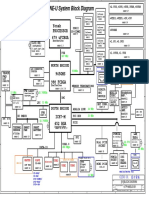
- Clevo M620ne-UDokument34 SeitenClevo M620ne-UHh woo't hoofNoch keine Bewertungen
- 400017A C65 Users Manual V5XXDokument61 Seiten400017A C65 Users Manual V5XXwhusada100% (1)
- Lord!: KnowledgeDokument161 SeitenLord!: KnowledgeAsra Zafar khanNoch keine Bewertungen
- Seafastening Calculations Transit ModifiedDokument380 SeitenSeafastening Calculations Transit ModifiedUtkarsh RamayanNoch keine Bewertungen
- Steering Gear TestingDokument9 SeitenSteering Gear TestingArun GK100% (1)
- Bloomberg - Transport - SecurityDokument13 SeitenBloomberg - Transport - SecurityFernandoNoch keine Bewertungen
- Velocloud OverviewDokument29 SeitenVelocloud OverviewFebri RawlinsNoch keine Bewertungen
- MET Till DEC 2018 PDFDokument171 SeitenMET Till DEC 2018 PDFt.srinivasanNoch keine Bewertungen
- Pt. Partono Fondas: Company ProfileDokument34 SeitenPt. Partono Fondas: Company Profileiqbal urbandNoch keine Bewertungen
- (Ebook - Electronics) - Principles of PLL - Tutorial (Kroupa 2000)Dokument66 Seiten(Ebook - Electronics) - Principles of PLL - Tutorial (Kroupa 2000)양종렬Noch keine Bewertungen
- Is 15707 2006Dokument23 SeitenIs 15707 2006anupam789Noch keine Bewertungen
- SuperOhm 3754 (3748-11) - Technical Data Sheet - ECC - Rev 2 - 2016-09Dokument2 SeitenSuperOhm 3754 (3748-11) - Technical Data Sheet - ECC - Rev 2 - 2016-09igor brocaNoch keine Bewertungen
- Rubber FaberDokument10 SeitenRubber FabersoldatechNoch keine Bewertungen
- SW Product SummaryDokument64 SeitenSW Product SummaryFabio MenegatoNoch keine Bewertungen
- Reverse Logistics: Overview and Challenges For Supply Chain ManagementDokument7 SeitenReverse Logistics: Overview and Challenges For Supply Chain ManagementSri WulandariNoch keine Bewertungen
- Design For X (DFX) Guidance Document: PurposeDokument3 SeitenDesign For X (DFX) Guidance Document: PurposeMani Rathinam RajamaniNoch keine Bewertungen
- Final Upcat Mock ExamDokument24 SeitenFinal Upcat Mock Examjbgonzales8Noch keine Bewertungen
- Planning and Site Investigation in TunnellingDokument6 SeitenPlanning and Site Investigation in TunnellingJean DalyNoch keine Bewertungen
- Ceilcote 383 Corocrete: Hybrid Polymer Broadcast FlooringDokument3 SeitenCeilcote 383 Corocrete: Hybrid Polymer Broadcast FlooringNadia AgdikaNoch keine Bewertungen
- Udyam Registration Certificate UDYAM-MH-26-0097771Dokument3 SeitenUdyam Registration Certificate UDYAM-MH-26-0097771Suresh D ChemateNoch keine Bewertungen
- Oracle E-Business Suite Release 12.2.6 Readme (Doc ID 2114016.1)Dokument18 SeitenOracle E-Business Suite Release 12.2.6 Readme (Doc ID 2114016.1)KingNoch keine Bewertungen
- AVR Interrupt Programming in Assembly and CDokument38 SeitenAVR Interrupt Programming in Assembly and CK142526 AlishanNoch keine Bewertungen
- Bomba FlightDokument2 SeitenBomba FlightGustavo HRNoch keine Bewertungen
- University of Mumbai: Syllabus For Sem V & VI Program: B.Sc. Course: PhysicsDokument18 SeitenUniversity of Mumbai: Syllabus For Sem V & VI Program: B.Sc. Course: Physicsdbhansali57Noch keine Bewertungen
- Tda - 2002 PDFDokument19 SeitenTda - 2002 PDFJose M PeresNoch keine Bewertungen
- Floor Plans & ElevationsDokument6 SeitenFloor Plans & Elevationsbryan cardonaNoch keine Bewertungen
- Cyclic Redundancy CheckDokument3 SeitenCyclic Redundancy CheckmeerashekarNoch keine Bewertungen
- AN127Dokument32 SeitenAN127piyushpandeyNoch keine Bewertungen
- 1504805126-HPI - CR-Series Copper Crusher - 04-2021ENDokument1 Seite1504805126-HPI - CR-Series Copper Crusher - 04-2021ENCaio BittencourtNoch keine Bewertungen