Das könnte Ihnen auch gefallen
- 10 ReactionDokument6 Seiten10 ReactionKarl Jason Dolar CominNoch keine Bewertungen
- Lesson Plan - Genograms Focusing and Empathic ConfrontationDokument5 SeitenLesson Plan - Genograms Focusing and Empathic Confrontationapi-246356859Noch keine Bewertungen
- Unit 1 The Capitalist Revolution 1.0Dokument33 SeitenUnit 1 The Capitalist Revolution 1.0knowme73Noch keine Bewertungen
- Multiple RegressionDokument100 SeitenMultiple RegressionNilton de SousaNoch keine Bewertungen
- 2013-01-28 203445 International Fault Codes Eges350 DTCDokument8 Seiten2013-01-28 203445 International Fault Codes Eges350 DTCVeterano del CaminoNoch keine Bewertungen
- Basic Terms/Concepts IN Analytical ChemistryDokument53 SeitenBasic Terms/Concepts IN Analytical ChemistrySheralyn PelayoNoch keine Bewertungen
- BDI3C Evaluation Rubric For Entrepreneurial Venture PlanDokument3 SeitenBDI3C Evaluation Rubric For Entrepreneurial Venture PlanRenante DeseoNoch keine Bewertungen
- Booklet Exam TemplateDokument2 SeitenBooklet Exam TemplateerrolNoch keine Bewertungen
- Midterm Examination in Business Math: C. Income StatementDokument4 SeitenMidterm Examination in Business Math: C. Income StatementMarilyn TorresNoch keine Bewertungen
- Mark On Mark Down Mark UpDokument26 SeitenMark On Mark Down Mark UpPrencis Iya MalanNoch keine Bewertungen
- ECONOassessment of Budget Preparation and Performance EvaluationDokument50 SeitenECONOassessment of Budget Preparation and Performance EvaluationMubarak100% (1)
- Business MathematicsDokument2 SeitenBusiness MathematicsLuz Gracia OyaoNoch keine Bewertungen
- Accounting1 Midterm Exam 1st Sem Ay2017-18Dokument13 SeitenAccounting1 Midterm Exam 1st Sem Ay2017-18Uy SamuelNoch keine Bewertungen
- Business Finance Summative Test 3Dokument3 SeitenBusiness Finance Summative Test 3Juanito II Balingsat100% (1)
- Hawassa University College of Business ADokument112 SeitenHawassa University College of Business AJeji HirboraNoch keine Bewertungen
- CH (10) - Book AnswersDokument17 SeitenCH (10) - Book AnswersabdulraufdghaybeejNoch keine Bewertungen
- HW3Dokument14 SeitenHW3Cheram Delapeña BoholNoch keine Bewertungen
- 1 Nature of StatisticsDokument7 Seiten1 Nature of StatisticsJay SerdonNoch keine Bewertungen
- Principles of Marketing ABM Chapter 4Dokument45 SeitenPrinciples of Marketing ABM Chapter 4Ariel TorialesNoch keine Bewertungen
- Minyichel BayeDokument86 SeitenMinyichel BayeMilkias MenaNoch keine Bewertungen
- Chap4 - Market StructureDokument29 SeitenChap4 - Market StructureThọ ĐỗNoch keine Bewertungen
- Chapter Five: Market Structure 5.1 Perfectly Competition Market StructureDokument27 SeitenChapter Five: Market Structure 5.1 Perfectly Competition Market StructureBlack boxNoch keine Bewertungen
- AdmasDokument170 SeitenAdmasHMichael AbeNoch keine Bewertungen
- Internship Report 5 SemDokument41 SeitenInternship Report 5 SemAayush SomaniNoch keine Bewertungen
- Time Value of Money: Family Economics & Financial EducationDokument32 SeitenTime Value of Money: Family Economics & Financial EducationBhagirath AshiyaNoch keine Bewertungen
- International Trade Midterm ExamDokument3 SeitenInternational Trade Midterm ExamRucha NimjeNoch keine Bewertungen
- Mas MCQDokument13 SeitenMas MCQIm In TroubleNoch keine Bewertungen
- CW Simple InterestDokument9 SeitenCW Simple Interestapi-269188118Noch keine Bewertungen
- QA Assignment II 2023Dokument3 SeitenQA Assignment II 2023eyob yohannesNoch keine Bewertungen
- Business Finance ReviewerDokument4 SeitenBusiness Finance ReviewerJanna rae BionganNoch keine Bewertungen
- Chapter1 - Statistics For Managerial DecisionsDokument26 SeitenChapter1 - Statistics For Managerial DecisionsRanjan Raj UrsNoch keine Bewertungen
- Income Tax 2022 Part 2Dokument6 SeitenIncome Tax 2022 Part 2Chezkie EmiaNoch keine Bewertungen
- Liul Dessie MBA Final Thesis IDNoMBA-388-13 Sec-7 PDFDokument68 SeitenLiul Dessie MBA Final Thesis IDNoMBA-388-13 Sec-7 PDFliulNoch keine Bewertungen
- Unconstrained OptimizationDokument11 SeitenUnconstrained OptimizationAndualem Begashaw100% (1)
- Pricing Factor of ProductionDokument17 SeitenPricing Factor of ProductionNeelamaQureshi100% (1)
- ReferencesDokument2 SeitenReferencesShrutiSharmaNoch keine Bewertungen
- Problem Exercises On Profit MaximizationDokument2 SeitenProblem Exercises On Profit MaximizationMarilou GabayaNoch keine Bewertungen
- Chapter One: 1.1 Background of The StudyDokument65 SeitenChapter One: 1.1 Background of The StudyJeji HirboraNoch keine Bewertungen
- SM Assignment 2019Dokument3 SeitenSM Assignment 2019Sarika AroteNoch keine Bewertungen
- Quiz Bee Problems Version 1Dokument68 SeitenQuiz Bee Problems Version 1Lalaine De JesusNoch keine Bewertungen
- MARKET RESEARCH - PPTDokument40 SeitenMARKET RESEARCH - PPTRodel lamanNoch keine Bewertungen
- Syllabus For Managerial EconomicsDokument18 SeitenSyllabus For Managerial EconomicsCharo GironellaNoch keine Bewertungen
- Inear RogrammingDokument20 SeitenInear Rogrammingmanjunath koraddiNoch keine Bewertungen
- Business Finance Introduction To Financial Management 05Dokument24 SeitenBusiness Finance Introduction To Financial Management 05Melvin J. ReyesNoch keine Bewertungen
- CVP AnalysisDokument11 SeitenCVP AnalysisPratiksha GaikwadNoch keine Bewertungen
- Ojt Parent Concent FormDokument1 SeiteOjt Parent Concent Formcytnhia bulikdayNoch keine Bewertungen
- Business Simulation - Diagnostic ExamDokument7 SeitenBusiness Simulation - Diagnostic Examdandy boneteNoch keine Bewertungen
- Oral CommunicationDokument17 SeitenOral Communicationmargilyn ramos100% (1)
- Tme 601Dokument14 SeitenTme 601dearsaswatNoch keine Bewertungen
- Industrial Management Beyond The SyllabusDokument17 SeitenIndustrial Management Beyond The SyllabusPrem Swarup100% (1)
- Business Mathematics Mid TermDokument2 SeitenBusiness Mathematics Mid Termaks1982Noch keine Bewertungen
- Activity 1 - Important TermsDokument1 SeiteActivity 1 - Important TermsAl BinnNoch keine Bewertungen
- Personal Data Sheet: Single Married Annulled Widowed Separated Others, SpecifyDokument4 SeitenPersonal Data Sheet: Single Married Annulled Widowed Separated Others, SpecifyEd Jaylan Manucdoc RamiscalNoch keine Bewertungen
- The Theory of Trade and Investment: True/False QuestionsDokument25 SeitenThe Theory of Trade and Investment: True/False QuestionsAshok SubramaniamNoch keine Bewertungen
- Ch1-5 Entrepreneurship For Common Course CompleteDokument178 SeitenCh1-5 Entrepreneurship For Common Course CompleteJaatooNoch keine Bewertungen
- Chapter 7 09302019Dokument38 SeitenChapter 7 09302019Arjay Molina100% (1)
- Introduction To Economics 2 PDFDokument26 SeitenIntroduction To Economics 2 PDFSelvaraj VillyNoch keine Bewertungen
- Article Reviewed For Economic ResearchDokument29 SeitenArticle Reviewed For Economic ResearchUrji Terefe100% (1)
- International Business Module 1Dokument22 SeitenInternational Business Module 1Ajesh Mukundan P0% (1)
- MARGINAL COSTING ExamplesDokument10 SeitenMARGINAL COSTING ExamplesLaljo VargheseNoch keine Bewertungen
- Chapter 4 Constrained Optimization: I) With Equality ConstraintDokument27 SeitenChapter 4 Constrained Optimization: I) With Equality ConstraintRoba Jirma BoruNoch keine Bewertungen
- Chapter 4 Demand EstimationDokument9 SeitenChapter 4 Demand EstimationdelisyaaamilyNoch keine Bewertungen
- Product Management MKT 534 OCT2009Dokument3 SeitenProduct Management MKT 534 OCT2009myraNoch keine Bewertungen
- Brand Equity & Brand IdentityDokument29 SeitenBrand Equity & Brand IdentitymyraNoch keine Bewertungen
- MKT534/531 October 2007Dokument3 SeitenMKT534/531 October 2007myraNoch keine Bewertungen
- Statistics & SPSSDokument49 SeitenStatistics & SPSSmyraNoch keine Bewertungen
- Product Management MKT 534 OCT2010Dokument3 SeitenProduct Management MKT 534 OCT2010myraNoch keine Bewertungen
- Features of Four Market StructuresDokument11 SeitenFeatures of Four Market StructuresmyraNoch keine Bewertungen
- ECO415 November 2005Dokument6 SeitenECO415 November 2005myra0% (1)
- Internet Marketing MKT544 OCT 2008Dokument4 SeitenInternet Marketing MKT544 OCT 2008myraNoch keine Bewertungen
- Product Management MKT 534 OCT2008Dokument3 SeitenProduct Management MKT 534 OCT2008myraNoch keine Bewertungen
- MKT534/531 October 2007Dokument3 SeitenMKT534/531 October 2007myraNoch keine Bewertungen
- ECO415 November 2005Dokument6 SeitenECO415 November 2005myra0% (1)
- MKT 535/532/561 April 2007Dokument3 SeitenMKT 535/532/561 April 2007myraNoch keine Bewertungen
- Marketing Research Mkt537 April 2009Dokument4 SeitenMarketing Research Mkt537 April 2009myraNoch keine Bewertungen
- Eco415 October 2007Dokument5 SeitenEco415 October 2007myra0% (1)
- MKT537/536/562 April 2008Dokument5 SeitenMKT537/536/562 April 2008myraNoch keine Bewertungen
- MKT537/536/562 October 2009Dokument5 SeitenMKT537/536/562 October 2009myraNoch keine Bewertungen
- MKT535/532/561/520 April 2008Dokument3 SeitenMKT535/532/561/520 April 2008myraNoch keine Bewertungen
- MKT537 536 562Dokument4 SeitenMKT537 536 562xone1215Noch keine Bewertungen
- MKT535/532/561/520 April 2009Dokument3 SeitenMKT535/532/561/520 April 2009myraNoch keine Bewertungen
- Marketing Research Mkt537 April 2009Dokument4 SeitenMarketing Research Mkt537 April 2009myraNoch keine Bewertungen
- MKT535/532/561/520 April 2008Dokument3 SeitenMKT535/532/561/520 April 2008myraNoch keine Bewertungen
- MKT 537/536 Oct 2007Dokument8 SeitenMKT 537/536 Oct 2007myraNoch keine Bewertungen
- MKT 537/536 April 2007Dokument7 SeitenMKT 537/536 April 2007myraNoch keine Bewertungen
- MKT535/532/561/520 October 2009Dokument3 SeitenMKT535/532/561/520 October 2009myraNoch keine Bewertungen
- MKT535/532/561/520 October 2008Dokument3 SeitenMKT535/532/561/520 October 2008myra100% (1)
- MKT 543/531 Apr2010Dokument3 SeitenMKT 543/531 Apr2010myraNoch keine Bewertungen
- MKT 544 Apr - 2008 - MKTDokument4 SeitenMKT 544 Apr - 2008 - MKTmyraNoch keine Bewertungen
- MKT 534/531/530 Apr2008Dokument3 SeitenMKT 534/531/530 Apr2008myraNoch keine Bewertungen
- MKT 543/541 Apr2009Dokument3 SeitenMKT 543/541 Apr2009myraNoch keine Bewertungen
- 3R Leaflet BIoutlineDokument1 Seite3R Leaflet BIoutlinemyraNoch keine Bewertungen
- The Bio-Based Economy in The NetherlandsDokument12 SeitenThe Bio-Based Economy in The NetherlandsIrving Toloache FloresNoch keine Bewertungen
- Man Bni PNT XXX 105 Z015 I17 Dok 886160 03 000Dokument36 SeitenMan Bni PNT XXX 105 Z015 I17 Dok 886160 03 000Eozz JaorNoch keine Bewertungen
- Test On Real NumberaDokument1 SeiteTest On Real Numberaer.manalirathiNoch keine Bewertungen
- Applications of Wireless Sensor Networks: An Up-to-Date SurveyDokument24 SeitenApplications of Wireless Sensor Networks: An Up-to-Date SurveyFranco Di NataleNoch keine Bewertungen
- Atmel 46003 SE M90E32AS DatasheetDokument84 SeitenAtmel 46003 SE M90E32AS DatasheetNagarajNoch keine Bewertungen
- Mahindra&mahindraDokument95 SeitenMahindra&mahindraAshik R GowdaNoch keine Bewertungen
- Approvals Management Responsibilities and Setups in AME.B PDFDokument20 SeitenApprovals Management Responsibilities and Setups in AME.B PDFAli LoganNoch keine Bewertungen
- Pam8610 PDFDokument15 SeitenPam8610 PDFRaka Satria PradanaNoch keine Bewertungen
- There Will Come Soft RainsDokument8 SeitenThere Will Come Soft RainsEng ProfNoch keine Bewertungen
- How To Install Metal LathDokument2 SeitenHow To Install Metal LathKfir BenishtiNoch keine Bewertungen
- A Short Survey On Memory Based RLDokument18 SeitenA Short Survey On Memory Based RLcnt dvsNoch keine Bewertungen
- L GSR ChartsDokument16 SeitenL GSR ChartsEmerald GrNoch keine Bewertungen
- Aristotle - OCR - AS Revision NotesDokument3 SeitenAristotle - OCR - AS Revision NotesAmelia Dovelle0% (1)
- Logistic RegressionDokument7 SeitenLogistic RegressionShashank JainNoch keine Bewertungen
- Life and Works of Jose Rizal Modified ModuleDokument96 SeitenLife and Works of Jose Rizal Modified ModuleRamos, Queencie R.Noch keine Bewertungen
- Data SheetDokument56 SeitenData SheetfaycelNoch keine Bewertungen
- 11-Rubber & PlasticsDokument48 Seiten11-Rubber & PlasticsJack NgNoch keine Bewertungen
- Hitachi Vehicle CardDokument44 SeitenHitachi Vehicle CardKieran RyanNoch keine Bewertungen
- ISO Position ToleranceDokument15 SeitenISO Position ToleranceНиколай КалугинNoch keine Bewertungen
- CPD - SampleDokument3 SeitenCPD - SampleLe Anh DungNoch keine Bewertungen
- Chakir Sara 2019Dokument25 SeitenChakir Sara 2019hiba toubaliNoch keine Bewertungen
- Michael Clapis Cylinder BlocksDokument5 SeitenMichael Clapis Cylinder Blocksapi-734979884Noch keine Bewertungen
- IPA Smith Osborne21632Dokument28 SeitenIPA Smith Osborne21632johnrobertbilo.bertilloNoch keine Bewertungen
- File RecordsDokument161 SeitenFile RecordsAtharva Thite100% (2)
- MATH CIDAM - PRECALCULUS (Midterm)Dokument4 SeitenMATH CIDAM - PRECALCULUS (Midterm)Amy MendiolaNoch keine Bewertungen
- KK AggarwalDokument412 SeitenKK AggarwalEnrico Miguel AquinoNoch keine Bewertungen
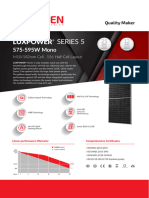
- Ficha Técnica Panel Solar 590W LuxenDokument2 SeitenFicha Técnica Panel Solar 590W LuxenyolmarcfNoch keine Bewertungen
- Atoma Amd Mol&Us CCTK) : 2Nd ErmDokument4 SeitenAtoma Amd Mol&Us CCTK) : 2Nd ErmjanviNoch keine Bewertungen