Das könnte Ihnen auch gefallen
- Indoor Radio Planning: A Practical Guide for 2G, 3G and 4GVon EverandIndoor Radio Planning: A Practical Guide for 2G, 3G and 4GBewertung: 5 von 5 Sternen5/5 (1)
- EEP Ubmicron Icroprocessor Esign Ssues: D - S M D IDokument12 SeitenEEP Ubmicron Icroprocessor Esign Ssues: D - S M D IBárbara RanieriNoch keine Bewertungen
- Digital Electronics, Computer Architecture and Microprocessor Design PrinciplesVon EverandDigital Electronics, Computer Architecture and Microprocessor Design PrinciplesNoch keine Bewertungen
- A Software-Programmable Multiple-Standard Radio PlatformDokument5 SeitenA Software-Programmable Multiple-Standard Radio PlatformdvdreadsNoch keine Bewertungen
- 2.1 Embedded SystemsDokument44 Seiten2.1 Embedded SystemsAakash SheelvantNoch keine Bewertungen
- VLSI Design Fault Tolerant Network On Chip: IPASJ International Journal of Electronics & Communication (IIJEC)Dokument3 SeitenVLSI Design Fault Tolerant Network On Chip: IPASJ International Journal of Electronics & Communication (IIJEC)IPASJNoch keine Bewertungen
- From GSM to LTE-Advanced Pro and 5G: An Introduction to Mobile Networks and Mobile BroadbandVon EverandFrom GSM to LTE-Advanced Pro and 5G: An Introduction to Mobile Networks and Mobile BroadbandNoch keine Bewertungen
- Embedded Node Around A DSP Core For Mobile Sensor Networks Over 802.11 InfrastructureDokument4 SeitenEmbedded Node Around A DSP Core For Mobile Sensor Networks Over 802.11 Infrastructureb42eluNoch keine Bewertungen
- ISSCC 2011 T R: Rends EportDokument16 SeitenISSCC 2011 T R: Rends Eportajith7Noch keine Bewertungen
- Multifunction Peripherals for PCs: Technology, Troubleshooting and RepairVon EverandMultifunction Peripherals for PCs: Technology, Troubleshooting and RepairNoch keine Bewertungen
- Internet of Things IotDokument18 SeitenInternet of Things IotElvis RodriguezNoch keine Bewertungen
- An Introduction To Multimedia Processors: Stephan SossauDokument11 SeitenAn Introduction To Multimedia Processors: Stephan SossauHyder LutfyNoch keine Bewertungen
- PLC in Energy MarketsDokument15 SeitenPLC in Energy MarketsKarim SenhajiNoch keine Bewertungen
- 1Q. Explain The Fundamentals of Computer Design 1.1 Fundamentals of Computer DesignDokument19 Seiten1Q. Explain The Fundamentals of Computer Design 1.1 Fundamentals of Computer DesigntgvrharshaNoch keine Bewertungen
- Power Consumption in Wireless Networks: Techniques & OptimizationsDokument4 SeitenPower Consumption in Wireless Networks: Techniques & OptimizationsAvrie MercadoNoch keine Bewertungen
- Alagappa Chettiar College of Engineering and Technology-Karaikudi 630 004Dokument12 SeitenAlagappa Chettiar College of Engineering and Technology-Karaikudi 630 004Ashwin JilNoch keine Bewertungen
- Ece3 - 4g Magic CommunicationDokument13 SeitenEce3 - 4g Magic Communicationitabassum5Noch keine Bewertungen
- Practical Troubleshooting of G729 Codec in A VoIP NetworkDokument10 SeitenPractical Troubleshooting of G729 Codec in A VoIP NetworkJournal of Telecommunications100% (14)
- Shivi PDFDokument4 SeitenShivi PDFPrasad BcNoch keine Bewertungen
- Analog Challenge of Nanometer CMOSDokument8 SeitenAnalog Challenge of Nanometer CMOSurpublicNoch keine Bewertungen
- 4G TechnologybitDokument9 Seiten4G TechnologybitsrinivasanramarajuNoch keine Bewertungen
- Optimization and Implementation of Speech Codec Based On Symmetric Multi-Processor PlatformDokument4 SeitenOptimization and Implementation of Speech Codec Based On Symmetric Multi-Processor PlatformJawad KhokharNoch keine Bewertungen
- Final DocumentationDokument63 SeitenFinal DocumentationSwamy NallabelliNoch keine Bewertungen
- Faculty Class Alert Using GSMDokument80 SeitenFaculty Class Alert Using GSMpraveen_kodgirwarNoch keine Bewertungen
- Cortex R4 White PaperDokument20 SeitenCortex R4 White PaperRAJARAMNoch keine Bewertungen
- NOVALIZA - 09071002016-DPSbringDVDqualityToPDAsDokument4 SeitenNOVALIZA - 09071002016-DPSbringDVDqualityToPDAsNova LizaNoch keine Bewertungen
- Software Defined Radio Implementation of A DVB S Transceiver PaperDokument5 SeitenSoftware Defined Radio Implementation of A DVB S Transceiver PaperLalchand MangalNoch keine Bewertungen
- Machine Design 10 May 2012Dokument100 SeitenMachine Design 10 May 2012Daniel Leal NevesNoch keine Bewertungen
- I R D S: Nternational Oadmap FOR Evices and YstemsDokument23 SeitenI R D S: Nternational Oadmap FOR Evices and YstemsSnehaNoch keine Bewertungen
- New Trends in Mobile Computing ArchitectureDokument8 SeitenNew Trends in Mobile Computing ArchitectureBibinMathewNoch keine Bewertungen
- Wideband Voice Coding - Opportunities and Implementation ChallengesDokument6 SeitenWideband Voice Coding - Opportunities and Implementation ChallengeshoainamcomitNoch keine Bewertungen
- Traffic Control SystemDokument57 SeitenTraffic Control SystemA.jeevithaNoch keine Bewertungen
- Unit I Fundamentals of Computer Design and Ilp-1-14Dokument14 SeitenUnit I Fundamentals of Computer Design and Ilp-1-14vamsidhar2008Noch keine Bewertungen
- Chameleon Chips Full ReportDokument24 SeitenChameleon Chips Full ReportSai Sree CharanNoch keine Bewertungen
- Eecs 318 Cad Computer Aided DesignDokument36 SeitenEecs 318 Cad Computer Aided Designshilpaa11Noch keine Bewertungen
- 4g Magic CommunicationDokument9 Seiten4g Magic CommunicationSurya Pratap DesaiNoch keine Bewertungen
- Selection of Voip Codecs For Different Networks Based On Qos AnalysisDokument7 SeitenSelection of Voip Codecs For Different Networks Based On Qos Analysiswaty5340Noch keine Bewertungen
- Btech Project On GSM Modem Pic16f877a ControllerDokument52 SeitenBtech Project On GSM Modem Pic16f877a ControllerTafadzwa Murwira100% (4)
- Embedded Real Time Video Monitoring System Using Arm: Kavitha Mamindla, Dr.V.Padmaja, CH - NagadeepaDokument5 SeitenEmbedded Real Time Video Monitoring System Using Arm: Kavitha Mamindla, Dr.V.Padmaja, CH - Nagadeepabrao89Noch keine Bewertungen
- WordlengthresuctionDokument18 SeitenWordlengthresuctionswetha sillveriNoch keine Bewertungen
- Low Power 3G MobilesDokument7 SeitenLow Power 3G MobilesAry SetiyonoNoch keine Bewertungen
- IC FabricatingDokument56 SeitenIC FabricatingAkshat MehrotraNoch keine Bewertungen
- Debugging Under LinuxDokument5 SeitenDebugging Under LinuxarunkumsinghNoch keine Bewertungen
- An Algorithm For Image Compression Using 2D Wavelet TransformDokument5 SeitenAn Algorithm For Image Compression Using 2D Wavelet TransformIJMERNoch keine Bewertungen
- The H.263 Video Coding StandardDokument4 SeitenThe H.263 Video Coding StandardPawan Kumar ThakurNoch keine Bewertungen
- The Role of Programmable Digital Signal Processors (DSP) For 3G Mobile Communication SystemsDokument8 SeitenThe Role of Programmable Digital Signal Processors (DSP) For 3G Mobile Communication Systemsdd bohraNoch keine Bewertungen
- Nokia Siemens Networks Master ThesisDokument5 SeitenNokia Siemens Networks Master ThesisBuyWritingPaperSpringfield100% (2)
- Mobile LinuxDokument8 SeitenMobile LinuxNavneet SinghNoch keine Bewertungen
- Seminar Report DSPDokument34 SeitenSeminar Report DSPwmallanNoch keine Bewertungen
- Implementation of DSP Algorithms On Reconfigurable Embedded PlatformDokument7 SeitenImplementation of DSP Algorithms On Reconfigurable Embedded PlatformGV Avinash KumarNoch keine Bewertungen
- 1.1 Reflex Technology: Department of ECE, VVCE Mysuru 1Dokument48 Seiten1.1 Reflex Technology: Department of ECE, VVCE Mysuru 1Harini MNoch keine Bewertungen
- Dept. of Ece, Sreebuddha College of Engineering 1Dokument34 SeitenDept. of Ece, Sreebuddha College of Engineering 1SARATH MOHANDASNoch keine Bewertungen
- DSP Modem/codec Implementation For Long Range Radio ApplicationsDokument10 SeitenDSP Modem/codec Implementation For Long Range Radio ApplicationsBhupendra singhNoch keine Bewertungen
- Application of DSP On Tms320c6713 DSKDokument50 SeitenApplication of DSP On Tms320c6713 DSKRain VIINoch keine Bewertungen
- International Journal Comp Tel - 1Dokument5 SeitenInternational Journal Comp Tel - 1shafa18Noch keine Bewertungen
- High-Performance 8-Bit Modulator Used For Sigma-Delta Analog To Digital ConverterDokument7 SeitenHigh-Performance 8-Bit Modulator Used For Sigma-Delta Analog To Digital ConverterAmeya DeshpandeNoch keine Bewertungen
- Fundamentals of Floor Planning A Complex Soc: Andre HassanDokument6 SeitenFundamentals of Floor Planning A Complex Soc: Andre HassanBaluvu JagadishNoch keine Bewertungen
- 12 Business Studies Impq CH07 DirectingDokument9 Seiten12 Business Studies Impq CH07 DirectingdeepashajiNoch keine Bewertungen
- Stanengding Rules&OrdersDokument130 SeitenStanengding Rules&OrdersdeepashajiNoch keine Bewertungen
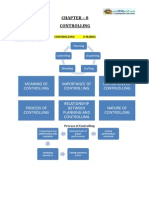
- 12 Business Studies Impq CH08 ControllingDokument9 Seiten12 Business Studies Impq CH08 ControllingdeepashajiNoch keine Bewertungen
- 38432reading 4Dokument28 Seiten38432reading 4deepashajiNoch keine Bewertungen
- English MattersDokument1 SeiteEnglish MattersdeepashajiNoch keine Bewertungen
- NWMP Engfull PackageDokument38 SeitenNWMP Engfull Packagedeepashaji100% (1)
- Police Injustice Responding Together To Chaengnge The StoryDokument4 SeitenPolice Injustice Responding Together To Chaengnge The StorydeepashajiNoch keine Bewertungen
- 170 Eng 10Dokument224 Seiten170 Eng 10deepashajiNoch keine Bewertungen
- Commonlit Reading LiteratureDokument77 SeitenCommonlit Reading LiteraturedeepashajiNoch keine Bewertungen
- Pages Froebom Police StoriesDokument17 SeitenPages Froebom Police StoriesdeepashajiNoch keine Bewertungen
- PSB Guidelinreadinges July2013Dokument25 SeitenPSB Guidelinreadinges July2013deepashajiNoch keine Bewertungen
- Parliamentary Procedures: Local Action GuideDokument2 SeitenParliamentary Procedures: Local Action GuidedeepashajiNoch keine Bewertungen
- Parliamentarengy ProcedureDokument1 SeiteParliamentarengy ProceduredeepashajiNoch keine Bewertungen
- Marking Scheme ScienceSubject XII 2010Dokument438 SeitenMarking Scheme ScienceSubject XII 2010Ashish KumarNoch keine Bewertungen
- Englishtagore The Home-ComingDokument5 SeitenEnglishtagore The Home-ComingdeepashajiNoch keine Bewertungen
- Parliamentary Procedure: Simplified Handbook ofDokument23 SeitenParliamentary Procedure: Simplified Handbook ofdeepashajiNoch keine Bewertungen
- Parliamentary Procedure - Quick Questions and Answers: T L C W S UDokument4 SeitenParliamentary Procedure - Quick Questions and Answers: T L C W S UdeepashajiNoch keine Bewertungen
- The Innovators: How a Group of Hackers, Geniuses, and Geeks Created the Digital RevolutionVon EverandThe Innovators: How a Group of Hackers, Geniuses, and Geeks Created the Digital RevolutionBewertung: 4.5 von 5 Sternen4.5/5 (543)
- Arduino and Raspberry Pi Sensor Projects for the Evil GeniusVon EverandArduino and Raspberry Pi Sensor Projects for the Evil GeniusNoch keine Bewertungen
- Secrets of the Millionaire Mind: Mastering the Inner Game of WealthVon EverandSecrets of the Millionaire Mind: Mastering the Inner Game of WealthBewertung: 4.5 von 5 Sternen4.5/5 (197)
- The Journeyman Electrician Exam Study Guide: Proven Methods for Successfully Passing the Journeyman Electrician Exam with ConfidenceVon EverandThe Journeyman Electrician Exam Study Guide: Proven Methods for Successfully Passing the Journeyman Electrician Exam with ConfidenceNoch keine Bewertungen
- The Homeowner's DIY Guide to Electrical WiringVon EverandThe Homeowner's DIY Guide to Electrical WiringBewertung: 5 von 5 Sternen5/5 (2)
- Practical Troubleshooting of Electrical Equipment and Control CircuitsVon EverandPractical Troubleshooting of Electrical Equipment and Control CircuitsBewertung: 4 von 5 Sternen4/5 (5)
- The Innovators: How a Group of Hackers, Geniuses, and Geeks Created the Digital RevolutionVon EverandThe Innovators: How a Group of Hackers, Geniuses, and Geeks Created the Digital RevolutionBewertung: 4 von 5 Sternen4/5 (331)
- Electrical Engineering 101: Everything You Should Have Learned in School...but Probably Didn'tVon EverandElectrical Engineering 101: Everything You Should Have Learned in School...but Probably Didn'tBewertung: 4.5 von 5 Sternen4.5/5 (27)
- Conquering the Electron: The Geniuses, Visionaries, Egomaniacs, and Scoundrels Who Built Our Electronic AgeVon EverandConquering the Electron: The Geniuses, Visionaries, Egomaniacs, and Scoundrels Who Built Our Electronic AgeBewertung: 4.5 von 5 Sternen4.5/5 (10)
- The Game: Penetrating the Secret Society of Pickup ArtistsVon EverandThe Game: Penetrating the Secret Society of Pickup ArtistsBewertung: 4 von 5 Sternen4/5 (131)
- Foundations of Western Civilization II: A History of the Modern Western World (Transcript)Von EverandFoundations of Western Civilization II: A History of the Modern Western World (Transcript)Bewertung: 4.5 von 5 Sternen4.5/5 (12)
- Beginner's Guide to Reading Schematics, Fourth EditionVon EverandBeginner's Guide to Reading Schematics, Fourth EditionBewertung: 3.5 von 5 Sternen3.5/5 (10)
- 2022 Adobe® Premiere Pro Guide For Filmmakers and YouTubersVon Everand2022 Adobe® Premiere Pro Guide For Filmmakers and YouTubersBewertung: 5 von 5 Sternen5/5 (1)
- The Fast Track to Your Extra Class Ham Radio License: Covers All FCC Amateur Extra Class Exam Questions July 1, 2020 Through June 30, 2024Von EverandThe Fast Track to Your Extra Class Ham Radio License: Covers All FCC Amateur Extra Class Exam Questions July 1, 2020 Through June 30, 2024Noch keine Bewertungen
- A Mind at Play: How Claude Shannon Invented the Information AgeVon EverandA Mind at Play: How Claude Shannon Invented the Information AgeBewertung: 4 von 5 Sternen4/5 (53)
- Multiplexed Networks for Embedded Systems: CAN, LIN, FlexRay, Safe-by-Wire...Von EverandMultiplexed Networks for Embedded Systems: CAN, LIN, FlexRay, Safe-by-Wire...Noch keine Bewertungen
- Guide to the IET Wiring Regulations: IET Wiring Regulations (BS 7671:2008 incorporating Amendment No 1:2011)Von EverandGuide to the IET Wiring Regulations: IET Wiring Regulations (BS 7671:2008 incorporating Amendment No 1:2011)Bewertung: 4 von 5 Sternen4/5 (2)
- Retro Gaming with Raspberry Pi: Nearly 200 Pages of Video Game ProjectsVon EverandRetro Gaming with Raspberry Pi: Nearly 200 Pages of Video Game ProjectsNoch keine Bewertungen
- Hacking Electronics: An Illustrated DIY Guide for Makers and HobbyistsVon EverandHacking Electronics: An Illustrated DIY Guide for Makers and HobbyistsBewertung: 3.5 von 5 Sternen3.5/5 (2)
- Power System Control and ProtectionVon EverandPower System Control and ProtectionB. Don RussellBewertung: 4 von 5 Sternen4/5 (11)
- Practical Electrical Wiring: Residential, Farm, Commercial, and IndustrialVon EverandPractical Electrical Wiring: Residential, Farm, Commercial, and IndustrialBewertung: 3.5 von 5 Sternen3.5/5 (3)
- Programming the Raspberry Pi, Third Edition: Getting Started with PythonVon EverandProgramming the Raspberry Pi, Third Edition: Getting Started with PythonBewertung: 5 von 5 Sternen5/5 (2)