Das könnte Ihnen auch gefallen
- Additional Notes On BackpropagationDokument2 SeitenAdditional Notes On Backpropagationballsarini aNoch keine Bewertungen
- Con 1Dokument1 SeiteCon 1silverpenNoch keine Bewertungen
- Adj 1Dokument1 SeiteAdj 1silverpenNoch keine Bewertungen
- "Nothing For Other People" - Class War in The United StatesDokument4 Seiten"Nothing For Other People" - Class War in The United Statesgreatguns2kNoch keine Bewertungen
- Modeling The Internet and The Web Chapter4Dokument67 SeitenModeling The Internet and The Web Chapter4greatguns2kNoch keine Bewertungen
- Eisenstein NLP NotesDokument587 SeitenEisenstein NLP NotesaklfkasdfjNoch keine Bewertungen
- Magna Carta Messed Up The World, Here's How To Fix It - OdtDokument6 SeitenMagna Carta Messed Up The World, Here's How To Fix It - OdtThavam Ratna100% (1)
- Market Democracy in A Neoliberal OrderDokument23 SeitenMarket Democracy in A Neoliberal Ordergreatguns2kNoch keine Bewertungen
- The Social Contract (1762)Dokument79 SeitenThe Social Contract (1762)Tomás Cardoso100% (2)
- Poverty Reduction Without Economic GrowthDokument47 SeitenPoverty Reduction Without Economic Growthgreatguns2kNoch keine Bewertungen
- Notes On Anarchism: Noam ChomskyDokument12 SeitenNotes On Anarchism: Noam Chomskygreatguns2kNoch keine Bewertungen
- The Soviet Union Vs SocialismDokument3 SeitenThe Soviet Union Vs Socialismgreatguns2kNoch keine Bewertungen
- NumPy, SciPy, Pandas, Quandl Cheat SheetDokument4 SeitenNumPy, SciPy, Pandas, Quandl Cheat Sheetseanrwcrawford100% (3)
- The One/two State Debate Is IrrelevantDokument5 SeitenThe One/two State Debate Is Irrelevantgreatguns2kNoch keine Bewertungen
- The Passion For Free MarketsDokument10 SeitenThe Passion For Free Marketsgreatguns2kNoch keine Bewertungen
- Chomsky Old Wine in New BottlesDokument9 SeitenChomsky Old Wine in New Bottlesgreatguns2kNoch keine Bewertungen
- Destroying The Commons: How The Magna Carta Became A Minor CartaDokument8 SeitenDestroying The Commons: How The Magna Carta Became A Minor Cartagreatguns2kNoch keine Bewertungen
- Pycon 2010Dokument19 SeitenPycon 2010Abd Rahman HidayatNoch keine Bewertungen
- Chomsky Impressions GazaDokument5 SeitenChomsky Impressions Gazagreatguns2kNoch keine Bewertungen
- IcelandDokument3 SeitenIcelandgreatguns2kNoch keine Bewertungen
- The Social Contract (1762)Dokument79 SeitenThe Social Contract (1762)Tomás Cardoso100% (2)
- Python Introduction PDFDokument381 SeitenPython Introduction PDFRahul SarafNoch keine Bewertungen
- Lebowitz1 310104Dokument24 SeitenLebowitz1 310104greatguns2kNoch keine Bewertungen
- The Governance of The IMF in A Global EconomyDokument26 SeitenThe Governance of The IMF in A Global Economygreatguns2kNoch keine Bewertungen
- The Communist ManifestoDokument34 SeitenThe Communist ManifestoRohin VajawatNoch keine Bewertungen
- Indian GrowthDokument43 SeitenIndian Growthgreatguns2kNoch keine Bewertungen
- Why Did Financial Globalization DissapointDokument29 SeitenWhy Did Financial Globalization Dissapointgreatguns2kNoch keine Bewertungen
- Why Did Financial Globalization DissapointDokument29 SeitenWhy Did Financial Globalization Dissapointgreatguns2kNoch keine Bewertungen
- LogicDokument39 SeitenLogicأبو عبد السلام100% (1)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Basic Statistics: Confidential, Proprietary Information of Tyco International LTDDokument74 SeitenBasic Statistics: Confidential, Proprietary Information of Tyco International LTDgaryNoch keine Bewertungen
- Syllabus of BcaiiDokument1 SeiteSyllabus of BcaiiARUNABH DAYALNoch keine Bewertungen
- Information Theory and Coding: 4 Electrical Engineering by DR Wassan SaadDokument26 SeitenInformation Theory and Coding: 4 Electrical Engineering by DR Wassan Saadtareq omarNoch keine Bewertungen
- Hydrologic Statistics: Reading: Chapter 11, Sections 12-1 and 12-2 of Applied HydrologyDokument32 SeitenHydrologic Statistics: Reading: Chapter 11, Sections 12-1 and 12-2 of Applied HydrologyRichardNoch keine Bewertungen
- Stat 350 Midterm 2Dokument6 SeitenStat 350 Midterm 2sin117Noch keine Bewertungen
- HW1 SolDokument8 SeitenHW1 SolKuangye ChenNoch keine Bewertungen
- Econometrics Final Exam Questions: Full Name - Altynai Kubatova - Group - Fin-18Dokument2 SeitenEconometrics Final Exam Questions: Full Name - Altynai Kubatova - Group - Fin-18Altynai KubatovaNoch keine Bewertungen
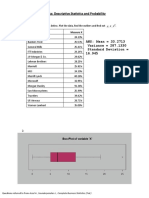
- Topics: Descriptive Statistics and Probability: Name of Company Measure XDokument4 SeitenTopics: Descriptive Statistics and Probability: Name of Company Measure XSimarjeet SinghNoch keine Bewertungen
- Chapter Two: Simple Linear Regression Models: Assumptions and EstimationDokument34 SeitenChapter Two: Simple Linear Regression Models: Assumptions and Estimationeferem100% (2)
- S03 mth243 Exam1 AnsDokument8 SeitenS03 mth243 Exam1 AnsAlice KrodeNoch keine Bewertungen
- Best Linear PredictorDokument15 SeitenBest Linear PredictorHoracioCastellanosMuñoaNoch keine Bewertungen
- The Normal Binomial and Poisson DistributionsDokument25 SeitenThe Normal Binomial and Poisson DistributionsDeepak RanaNoch keine Bewertungen
- Probability: An Introduction To Modeling UncertaintyDokument98 SeitenProbability: An Introduction To Modeling UncertaintyjoseNoch keine Bewertungen
- MIT18 05S14 ps1 Solutions PDFDokument6 SeitenMIT18 05S14 ps1 Solutions PDFJayant DarokarNoch keine Bewertungen
- Tute - 04Dokument6 SeitenTute - 04Kamsha NathanNoch keine Bewertungen
- Sampling DistributionDokument13 SeitenSampling DistributionASHISH100% (3)
- Random VariableDokument4 SeitenRandom VariableTehseen ShahNoch keine Bewertungen
- Chapter 6 RecitationDokument7 SeitenChapter 6 RecitationNagulNoch keine Bewertungen
- Q 10-14 Samad SiddiquiDokument13 SeitenQ 10-14 Samad SiddiquiSamad SiddiquiNoch keine Bewertungen
- Probability For Dummies Cheat Sheet - For DummiesDokument3 SeitenProbability For Dummies Cheat Sheet - For DummiesBrian O'ConnellNoch keine Bewertungen
- Econometrics II CH 1Dokument48 SeitenEconometrics II CH 1nigusu deguNoch keine Bewertungen
- ErmDokument319 SeitenErmrather fodlingNoch keine Bewertungen
- Measures of Relative PositionDokument11 SeitenMeasures of Relative PositionrolandNoch keine Bewertungen
- Quiz 3: Statistics A. MULTIPLE CHOICE. Write The Letter of Your On The Space Provided Before The NumberDokument5 SeitenQuiz 3: Statistics A. MULTIPLE CHOICE. Write The Letter of Your On The Space Provided Before The NumberPatrick GoNoch keine Bewertungen
- 3-1-Lossless CompressionDokument10 Seiten3-1-Lossless CompressionMuhamadAndiNoch keine Bewertungen
- 14-Article Text-88-1-10-20200715Dokument15 Seiten14-Article Text-88-1-10-20200715Friskilia RenmaurNoch keine Bewertungen
- JCGM - 106 - 2012 (M C 7)Dokument14 SeitenJCGM - 106 - 2012 (M C 7)Quốc Tuấn ĐặngNoch keine Bewertungen
- Mcqs Eas Matlab 17 Ms PT Amd 06 and 17 Ms FT Amd 16Dokument2 SeitenMcqs Eas Matlab 17 Ms PT Amd 06 and 17 Ms FT Amd 16Engr Mujahid IqbalNoch keine Bewertungen
- Project 3Dokument4 SeitenProject 3Mona SinghNoch keine Bewertungen
- Fa Question Sta104 Qmt181 July 2020 1Dokument10 SeitenFa Question Sta104 Qmt181 July 2020 1NafriRoem99Noch keine Bewertungen