Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Automatic Gearbox ZF 4HP 20Dokument40 SeitenAutomatic Gearbox ZF 4HP 20Damien Jorgensen100% (3)
- Numerical Modelling and Design of Electrical DevicesDokument69 SeitenNumerical Modelling and Design of Electrical Devicesfabrice mellantNoch keine Bewertungen
- NABARD R&D Seminar FormatDokument7 SeitenNABARD R&D Seminar FormatAnupam G. RatheeNoch keine Bewertungen
- Assignment 4Dokument5 SeitenAssignment 4Hafiz AhmadNoch keine Bewertungen
- Concrete Repair Manual (2017)Dokument59 SeitenConcrete Repair Manual (2017)Fernando EscriváNoch keine Bewertungen
- Low Budget Music Promotion and PublicityDokument41 SeitenLow Budget Music Promotion and PublicityFola Folayan100% (3)
- Internship Report Format For Associate Degree ProgramDokument5 SeitenInternship Report Format For Associate Degree ProgramBisma AmjaidNoch keine Bewertungen
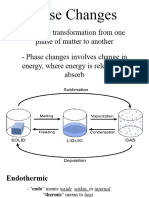
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDokument19 SeitenGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaNoch keine Bewertungen
- Mathematics Mock Exam 2015Dokument4 SeitenMathematics Mock Exam 2015Ian BautistaNoch keine Bewertungen
- Forex Day Trading SystemDokument17 SeitenForex Day Trading SystemSocial Malik100% (1)
- Contoh Discussion Text Tentang HomeworkDokument8 SeitenContoh Discussion Text Tentang Homeworkg3p35rs6100% (1)
- Wallem Philippines Shipping Inc. v. S.R. Farms (Laxamana)Dokument2 SeitenWallem Philippines Shipping Inc. v. S.R. Farms (Laxamana)WENDELL LAXAMANANoch keine Bewertungen
- I I Formularies Laundry Commercial Liquid Detergents 110-12-020 USDokument6 SeitenI I Formularies Laundry Commercial Liquid Detergents 110-12-020 USfaissalNoch keine Bewertungen
- M. Ircham Mansyur 07224005 Microprocessor-2 (H13)Dokument7 SeitenM. Ircham Mansyur 07224005 Microprocessor-2 (H13)emiierNoch keine Bewertungen
- Ecs h61h2-m12 Motherboard ManualDokument70 SeitenEcs h61h2-m12 Motherboard ManualsarokihNoch keine Bewertungen
- Facebook: Daisy BuchananDokument5 SeitenFacebook: Daisy BuchananbelenrichardiNoch keine Bewertungen
- To Find Fatty Material of Different Soap SamplesDokument17 SeitenTo Find Fatty Material of Different Soap SamplesRohan Singh0% (2)
- S4 HANALicensing Model External V19Dokument28 SeitenS4 HANALicensing Model External V19Edir JuniorNoch keine Bewertungen
- Introduction To Retail LoansDokument2 SeitenIntroduction To Retail LoansSameer ShahNoch keine Bewertungen
- HFE0106 TraskPart2Dokument5 SeitenHFE0106 TraskPart2arunkr1Noch keine Bewertungen
- CORP2165D Lecture 04Dokument26 SeitenCORP2165D Lecture 04kinzi chesterNoch keine Bewertungen
- When A Snobbish Gangster Meets A Pervert CassanovaDokument62 SeitenWhen A Snobbish Gangster Meets A Pervert CassanovaMaria Shiela Mae Baratas100% (1)
- GE 7 ReportDokument31 SeitenGE 7 ReportMark Anthony FergusonNoch keine Bewertungen
- Hazardous Locations: C.E.C. ClassificationsDokument4 SeitenHazardous Locations: C.E.C. ClassificationsThananuwat SuksaroNoch keine Bewertungen
- Smart Gas Leakage Detection With Monitoring and Automatic Safety SystemDokument4 SeitenSmart Gas Leakage Detection With Monitoring and Automatic Safety SystemYeasin Arafat FahadNoch keine Bewertungen
- Math Review CompilationDokument9 SeitenMath Review CompilationJessa Laika CastardoNoch keine Bewertungen
- PP Master Data Version 002Dokument34 SeitenPP Master Data Version 002pranitNoch keine Bewertungen
- Hydraulic Mining ExcavatorDokument8 SeitenHydraulic Mining Excavatorasditia_07100% (1)
- Union Test Prep Nclex Study GuideDokument115 SeitenUnion Test Prep Nclex Study GuideBradburn Nursing100% (2)
- Semi Detailed Lesson PlanDokument2 SeitenSemi Detailed Lesson PlanJean-jean Dela Cruz CamatNoch keine Bewertungen