Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Ignazio Basile, Pierpaolo Ferrari (Eds.) - Asset Management and Institutional Investors-Springer International Publishing (2016) PDFDokument469 SeitenIgnazio Basile, Pierpaolo Ferrari (Eds.) - Asset Management and Institutional Investors-Springer International Publishing (2016) PDFrhinolovescokeNoch keine Bewertungen
- Engineering Economy 3Dokument37 SeitenEngineering Economy 3Steven SengNoch keine Bewertungen
- How To Be A Mathemagician PDFDokument331 SeitenHow To Be A Mathemagician PDFmadhav1967% (3)
- 01 IoT Based Smart AgricultureDokument45 Seiten01 IoT Based Smart AgricultureGautam DemattiNoch keine Bewertungen
- Dbms QP-15Dokument22 SeitenDbms QP-15Gautam DemattiNoch keine Bewertungen
- Cse-Iv-Engineering Mathematics - Iv (10mat41) - Notes PDFDokument132 SeitenCse-Iv-Engineering Mathematics - Iv (10mat41) - Notes PDFGautam Dematti100% (1)
- Information For Authors: Full Papers Are Characterized by Novel Contributions of Archival Nature in DevelopingDokument1 SeiteInformation For Authors: Full Papers Are Characterized by Novel Contributions of Archival Nature in DevelopingGautam DemattiNoch keine Bewertungen
- 10.1.4 Unit Testing of Explicit Random Algorithm: SL No. of Test Case Name of Test Feature Being Tested DescriptionDokument1 Seite10.1.4 Unit Testing of Explicit Random Algorithm: SL No. of Test Case Name of Test Feature Being Tested DescriptionGautam DemattiNoch keine Bewertungen
- DBMS Lesson PlanDokument8 SeitenDBMS Lesson PlanGautam DemattiNoch keine Bewertungen
- Uscert CloudcomputinghuthcebulaDokument4 SeitenUscert CloudcomputinghuthcebulaGautam DemattiNoch keine Bewertungen
- The Use of Underwater Wireless Networks in Pisciculture at AmazonDokument5 SeitenThe Use of Underwater Wireless Networks in Pisciculture at AmazonGautam DemattiNoch keine Bewertungen
- SDRP: A Secure and Distributed Reprogramming Protocol For Wireless Sensor NetworksDokument9 SeitenSDRP: A Secure and Distributed Reprogramming Protocol For Wireless Sensor NetworksGautam DemattiNoch keine Bewertungen
- Vehicle ViewDokument7 SeitenVehicle ViewGautam DemattiNoch keine Bewertungen
- Enhanced Communication Scheme For Mobile Agents: Geetha Priya. B, Suba. S, Tanya Bansal, P.BoominathanDokument6 SeitenEnhanced Communication Scheme For Mobile Agents: Geetha Priya. B, Suba. S, Tanya Bansal, P.BoominathanGautam DemattiNoch keine Bewertungen
- Aquatic ApplicationsDokument8 SeitenAquatic ApplicationsGautam DemattiNoch keine Bewertungen
- Active Learning From Multiple Knowledge SourcesDokument8 SeitenActive Learning From Multiple Knowledge SourcesGautam DemattiNoch keine Bewertungen
- FANUC Series 16i 18i 21i Expansion of Custom Macro Interface SignalDokument10 SeitenFANUC Series 16i 18i 21i Expansion of Custom Macro Interface Signalmahdi elmayNoch keine Bewertungen
- Landing Gear Design and DevelopmentDokument12 SeitenLanding Gear Design and DevelopmentC V CHANDRASHEKARANoch keine Bewertungen
- Time SignatureDokument13 SeitenTime SignaturecornelNoch keine Bewertungen
- Cost-Volume-Profit Relationships: © 2010 The Mcgraw-Hill Companies, IncDokument97 SeitenCost-Volume-Profit Relationships: © 2010 The Mcgraw-Hill Companies, IncInga ApseNoch keine Bewertungen
- Advanced Digital Image Processing: Course ObjectivesDokument3 SeitenAdvanced Digital Image Processing: Course ObjectivesvineelaNoch keine Bewertungen
- Calibration of SensorsDokument5 SeitenCalibration of SensorsSubhrajit MoharanaNoch keine Bewertungen
- Large Power Transformers - Karsai-Kerenyi-Kiss - OcrDokument622 SeitenLarge Power Transformers - Karsai-Kerenyi-Kiss - OcrJuan Jerez100% (1)
- Emf Questions For AssignmentDokument7 SeitenEmf Questions For AssignmentDrGopikrishna PasamNoch keine Bewertungen
- Programme Number: 1 InputDokument18 SeitenProgramme Number: 1 InputroshanNoch keine Bewertungen
- Sr. No. A B C D Ans: Engineering Mechanics (2019 Pattern) Unit 2Dokument14 SeitenSr. No. A B C D Ans: Engineering Mechanics (2019 Pattern) Unit 2Ajit MoreNoch keine Bewertungen
- Machine LearningDokument216 SeitenMachine LearningTharshninipriya RajasekarNoch keine Bewertungen
- Liquid Holdup in PackedDokument11 SeitenLiquid Holdup in PackedVictor VazquezNoch keine Bewertungen
- Measure of Variability - Data Management PDFDokument79 SeitenMeasure of Variability - Data Management PDFPolly VicenteNoch keine Bewertungen
- Ebookdjj5113 Mechanics of Machines WatermarkDokument272 SeitenEbookdjj5113 Mechanics of Machines WatermarkXCarlZNoch keine Bewertungen
- REF615 Standard ConfigurationDokument11 SeitenREF615 Standard Configurationmaruf048Noch keine Bewertungen
- Chapter 1 Thinking Like An EconomistDokument41 SeitenChapter 1 Thinking Like An EconomistWeaam AbdelmoniemNoch keine Bewertungen
- WiproDokument44 SeitenWiproapi-26541915Noch keine Bewertungen
- Rish em 3490 Ss Manual Rev-C 1phDokument7 SeitenRish em 3490 Ss Manual Rev-C 1phpitambervermaNoch keine Bewertungen
- Design of Passenger Aerial Ropeway For Urban EnvirDokument13 SeitenDesign of Passenger Aerial Ropeway For Urban EnvirmaniNoch keine Bewertungen
- Diagnosis: Highlights: Cita Rosita Sigit PrakoeswaDokument68 SeitenDiagnosis: Highlights: Cita Rosita Sigit PrakoeswaAdniana NareswariNoch keine Bewertungen
- FEEDBACKDokument43 SeitenFEEDBACKMenaka kaulNoch keine Bewertungen
- Rakesh Mandal 180120031Dokument7 SeitenRakesh Mandal 180120031Rakesh RajputNoch keine Bewertungen
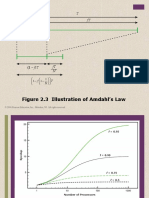
- Figure 2.3 Illustration of Amdahl's Law: © 2016 Pearson Education, Inc., Hoboken, NJ. All Rights ReservedDokument10 SeitenFigure 2.3 Illustration of Amdahl's Law: © 2016 Pearson Education, Inc., Hoboken, NJ. All Rights ReservedAhmed AyazNoch keine Bewertungen
- MODULE 3 and 4Dokument6 SeitenMODULE 3 and 4Jellene Jem RonarioNoch keine Bewertungen
- Cse PDFDokument33 SeitenCse PDFSha Nkar JavleNoch keine Bewertungen
- PuzzlesDokument47 SeitenPuzzlesGeetha Priya100% (1)
- Geometry Class 6 Final ExamDokument4 SeitenGeometry Class 6 Final ExamTanzimNoch keine Bewertungen