Das könnte Ihnen auch gefallen
- A Color Atlas For Oral PathologyDokument6 SeitenA Color Atlas For Oral PathologyMohammed S. Al Ghamdi0% (2)
- A Color Atlas For Oral PathologyDokument6 SeitenA Color Atlas For Oral PathologyMohammed S. Al Ghamdi0% (2)
- Prof. Dr. Md. Mozammel Hoque: Department of Biochemistry & Molecular Biology BSMMU, Dhaka, BangladeshDokument165 SeitenProf. Dr. Md. Mozammel Hoque: Department of Biochemistry & Molecular Biology BSMMU, Dhaka, BangladeshInzamamul Haque ShihabNoch keine Bewertungen
- IPCA Precast Concrete Frames GuideDokument58 SeitenIPCA Precast Concrete Frames GuideMaurício Ferreira100% (1)
- BMS1042 Module 1Dokument7 SeitenBMS1042 Module 1hafsatutuNoch keine Bewertungen
- Introduction PDFDokument29 SeitenIntroduction PDFhadin khanNoch keine Bewertungen
- Lectures On Biostatistics-ocr4.PDF 123Dokument100 SeitenLectures On Biostatistics-ocr4.PDF 123DrAmit VermaNoch keine Bewertungen
- Statistics NotesDokument15 SeitenStatistics NotesBalasubrahmanya K. R.Noch keine Bewertungen
- Data Collection and HandlingDokument19 SeitenData Collection and HandlingteklayNoch keine Bewertungen
- Lecture 1 - Statistics, Types of Data - Data Collection Batch 11Dokument39 SeitenLecture 1 - Statistics, Types of Data - Data Collection Batch 11gothai sivapragasamNoch keine Bewertungen
- Lesson1 1446Dokument46 SeitenLesson1 1446gm hashNoch keine Bewertungen
- Statistics Eye HealthDokument19 SeitenStatistics Eye HealthPabitra ChaudharyNoch keine Bewertungen
- Biostatistics For Health Science Students: College of Medicine & Health SciencesDokument238 SeitenBiostatistics For Health Science Students: College of Medicine & Health SciencesRamzi JamalNoch keine Bewertungen
- Introduction To Biostatistics: DR Asim WarisDokument37 SeitenIntroduction To Biostatistics: DR Asim WarisNaveed Malik0% (1)
- Medical Statistics - PPTX Lecture 1 To 10Dokument185 SeitenMedical Statistics - PPTX Lecture 1 To 10Kylie NNoch keine Bewertungen
- Biostatistics and ExerciseDokument97 SeitenBiostatistics and ExerciseMINANI Theobald100% (4)
- Biostatistics Word NewDokument43 SeitenBiostatistics Word NewMereesha K MoideenNoch keine Bewertungen
- Lecture 1Dokument33 SeitenLecture 1Tanya garg100% (1)
- Stats Definitions-1Dokument4 SeitenStats Definitions-1nimrashahidcommerceicomNoch keine Bewertungen
- Basic Statistics (3685) PPT - Lecture On 20-01-2019Dokument64 SeitenBasic Statistics (3685) PPT - Lecture On 20-01-2019M Hammad ManzoorNoch keine Bewertungen
- Introduction To Biostatistics: Dr. M. H. RahbarDokument35 SeitenIntroduction To Biostatistics: Dr. M. H. Rahbarfandy faidhulNoch keine Bewertungen
- Biostatics For NursesDokument74 SeitenBiostatics For NursesAmmar BhattiNoch keine Bewertungen
- Biostatistics Word NewDokument43 SeitenBiostatistics Word NewMereesha K MoideenNoch keine Bewertungen
- Introduction To BiostatisticsDokument19 SeitenIntroduction To BiostatisticsAhmad AnsariNoch keine Bewertungen
- Biostatistics (Introduction)Dokument66 SeitenBiostatistics (Introduction)Dr. Muhammad Bilal SiddiquiNoch keine Bewertungen
- 1 - Introduction To BiostatisticsDokument321 Seiten1 - Introduction To Biostatisticshfkxbbbty2Noch keine Bewertungen
- Bio StatsDokument19 SeitenBio StatsAmisha MahajanNoch keine Bewertungen
- Introduction To Bio-Statistics and Research Methods (HMN 1204)Dokument57 SeitenIntroduction To Bio-Statistics and Research Methods (HMN 1204)kihembo pamelahNoch keine Bewertungen
- SFB Module I 2019Dokument37 SeitenSFB Module I 2019Ashwani SharmaNoch keine Bewertungen
- Topic OneDokument20 SeitenTopic OneHamse HusseinNoch keine Bewertungen
- Introduction To Biostatistics1Dokument23 SeitenIntroduction To Biostatistics1Noha SalehNoch keine Bewertungen
- Test 09iouujjkkllDokument11 SeitenTest 09iouujjkkllzola_getNoch keine Bewertungen
- 1 - First Lecture - Introduction & DataDokument6 Seiten1 - First Lecture - Introduction & DataFatma ElzaytNoch keine Bewertungen
- Introduction To BiostatisticsDokument19 SeitenIntroduction To BiostatisticsMuhammad ShahidNoch keine Bewertungen
- Stat Basic DefinitionsDokument4 SeitenStat Basic DefinitionsPiyush MoradiyaNoch keine Bewertungen
- Statistics Definitions From Pagano TextbookDokument13 SeitenStatistics Definitions From Pagano TextbookIngenious AngelNoch keine Bewertungen
- Epidemiologica L Studies: Epidemiology CHS234Dokument34 SeitenEpidemiologica L Studies: Epidemiology CHS234اسامة محمد السيد رمضانNoch keine Bewertungen
- Bio-Statistics and RD Lecture NoteDokument176 SeitenBio-Statistics and RD Lecture NotefayanNoch keine Bewertungen
- ModLec273 2Dokument84 SeitenModLec273 2bernabasNoch keine Bewertungen
- Important Concepts DocDokument40 SeitenImportant Concepts DocemranalshaibaniNoch keine Bewertungen
- احصاءDokument20 SeitenاحصاءTawfek RedaNoch keine Bewertungen
- Basic Concepts of VariablesDokument1 SeiteBasic Concepts of VariablesCindy Mae CamohoyNoch keine Bewertungen
- BiostasticsDokument430 SeitenBiostasticsDaniel kebedeNoch keine Bewertungen
- Statistics LessonsDokument57 SeitenStatistics LessonsismaelkellyNoch keine Bewertungen
- Styudy Notes 2015 2Dokument105 SeitenStyudy Notes 2015 2Gayathri RNoch keine Bewertungen
- Data and VariablesDokument49 SeitenData and VariablesMaritza Mendez ReinaNoch keine Bewertungen
- Measurement ScalesDokument18 SeitenMeasurement Scaleseddache04Noch keine Bewertungen
- Introduction To Biostatistics: Reynaldo G. San Luis III, MDDokument28 SeitenIntroduction To Biostatistics: Reynaldo G. San Luis III, MDAileen JaymeNoch keine Bewertungen
- Statistical Random Population Statistical Inference Data CollectionDokument4 SeitenStatistical Random Population Statistical Inference Data CollectionloiselleilanoNoch keine Bewertungen
- StatDokument23 SeitenStatDoc_mmaNoch keine Bewertungen
- Introductiontobasicsofbio Statistics 180127163400Dokument48 SeitenIntroductiontobasicsofbio Statistics 180127163400shariquesarwar01Noch keine Bewertungen
- 01 Nature of Statistics-1-1Dokument13 Seiten01 Nature of Statistics-1-1Muhsin Sa-eedNoch keine Bewertungen
- What Is Statistics1Dokument20 SeitenWhat Is Statistics1Candy ChocolateNoch keine Bewertungen
- BIO STATISTICS of First SemesterDokument143 SeitenBIO STATISTICS of First SemesterRabiaa QureshiNoch keine Bewertungen
- 6 Sampling and Basic Descriptive StatisticsDokument38 Seiten6 Sampling and Basic Descriptive Statisticsnasz_aliaNoch keine Bewertungen
- Abs&rm 01Dokument47 SeitenAbs&rm 01kiranNoch keine Bewertungen
- Datasets 551982 1490480 Kaggle Target Tables 0 Table Formats and Column Definitions Column DefinitionsDokument5 SeitenDatasets 551982 1490480 Kaggle Target Tables 0 Table Formats and Column Definitions Column Definitionsbala bhavani peddiNoch keine Bewertungen
- 1 - Basic ConceptsDokument71 Seiten1 - Basic Conceptslyriemaecutara0Noch keine Bewertungen
- 3 - Tiki Taka Statistics 1Dokument23 Seiten3 - Tiki Taka Statistics 1Mohammed Hosen0% (1)
- Statistics Long EssayDokument22 SeitenStatistics Long EssayMohamed NasarNoch keine Bewertungen
- Analysis for Time-to-Event Data under Censoring and TruncationVon EverandAnalysis for Time-to-Event Data under Censoring and TruncationBewertung: 5 von 5 Sternen5/5 (1)
- Biostatistics Explored Through R Software: An OverviewVon EverandBiostatistics Explored Through R Software: An OverviewBewertung: 3.5 von 5 Sternen3.5/5 (2)
- Overview Of Bayesian Approach To Statistical Methods: SoftwareVon EverandOverview Of Bayesian Approach To Statistical Methods: SoftwareNoch keine Bewertungen
- Body BufferDokument64 SeitenBody BufferrozhaNoch keine Bewertungen
- Anticoagulant PresentationDokument29 SeitenAnticoagulant Presentationrozha100% (2)
- Abnormal Carbohydrate MetabolismDokument67 SeitenAbnormal Carbohydrate MetabolismrozhaNoch keine Bewertungen
- Anxiolytic2003.Lec - New Microsoft Office Power Point PresentationDokument29 SeitenAnxiolytic2003.Lec - New Microsoft Office Power Point PresentationrozhaNoch keine Bewertungen
- Analgesics - New Microsoft Office Power Point PresentationDokument21 SeitenAnalgesics - New Microsoft Office Power Point Presentationrozha100% (4)
- Anticoagulant PresentationDokument29 SeitenAnticoagulant Presentationrozha100% (2)
- Anxiolytic2003.Lec - New Microsoft Office Power Point PresentationDokument29 SeitenAnxiolytic2003.Lec - New Microsoft Office Power Point PresentationrozhaNoch keine Bewertungen
- Analgesics - New Microsoft Office Power Point PresentationDokument21 SeitenAnalgesics - New Microsoft Office Power Point Presentationrozha100% (4)
- Physiology of SecretionDokument14 SeitenPhysiology of Secretionrozha100% (2)
- Periodontal ReceptorsDokument18 SeitenPeriodontal Receptorsrozha88% (16)
- PPT10-super and UltracapacitorDokument22 SeitenPPT10-super and UltracapacitorChaudhari Jainish100% (1)
- Pakistan Academy School Al-Ahmadi Kuwait Monthly Test Schedule Class: AS-LEVELDokument9 SeitenPakistan Academy School Al-Ahmadi Kuwait Monthly Test Schedule Class: AS-LEVELapi-126472277Noch keine Bewertungen
- Parts Catalog: Imagerunner Advance 6075/6065/6055 SeriesDokument201 SeitenParts Catalog: Imagerunner Advance 6075/6065/6055 SeriesTally LeonNoch keine Bewertungen
- Queuing Model: Basic TerminologiesDokument11 SeitenQueuing Model: Basic TerminologiesHamzaNoch keine Bewertungen
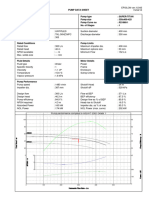
- TKL Pump - Data - SheetDokument1 SeiteTKL Pump - Data - Sheetธนาชัย เต็งจิรธนาภาNoch keine Bewertungen
- Epf011acd Ug V02-7302Dokument124 SeitenEpf011acd Ug V02-7302sluz2000Noch keine Bewertungen
- Condition Monitoring of Pumps - How To Save Three Ways: Session OneDokument35 SeitenCondition Monitoring of Pumps - How To Save Three Ways: Session OneJorge FracaroNoch keine Bewertungen
- Acumuladores de AP Atlas CopcoDokument32 SeitenAcumuladores de AP Atlas CopcovictorhernandezregaNoch keine Bewertungen
- Lesson Plan Letter MDokument3 SeitenLesson Plan Letter Mapi-307404579Noch keine Bewertungen
- The Health and Sanitary Status of Mamanwa IndigenoDokument9 SeitenThe Health and Sanitary Status of Mamanwa IndigenoRush VeltranNoch keine Bewertungen
- Sec D CH 12 Regression Part 2Dokument66 SeitenSec D CH 12 Regression Part 2Ranga SriNoch keine Bewertungen
- SQL Webinar FinalDokument21 SeitenSQL Webinar FinalYaswanth ReddyNoch keine Bewertungen
- Bending Moment PresentationDokument21 SeitenBending Moment PresentationRiethanelia UsunNoch keine Bewertungen
- Application For Petitioned Class: College of Engineering and ArchitectureDokument2 SeitenApplication For Petitioned Class: College of Engineering and ArchitectureJohn A. CenizaNoch keine Bewertungen
- 4456 PDFDokument978 Seiten4456 PDFVentasVarias Antofa100% (1)
- Rocket PropulsionDokument29 SeitenRocket PropulsionPrajwal Vemala JagadeeshwaraNoch keine Bewertungen
- B.tech Project Stage-II Presentation - MidsemDokument25 SeitenB.tech Project Stage-II Presentation - Midsemkaalin bhaiyaNoch keine Bewertungen
- BPMDokument3 SeitenBPMarunsawaiyanNoch keine Bewertungen
- Attitude Summary MFDokument8 SeitenAttitude Summary MFAraz YagubluNoch keine Bewertungen
- About The ProjectDokument5 SeitenAbout The Projectanand kumarNoch keine Bewertungen
- Performance of A Load-Immune Classifier For Robust Identification of Minor Faults in Induction Motor Stator WindingDokument12 SeitenPerformance of A Load-Immune Classifier For Robust Identification of Minor Faults in Induction Motor Stator Windingm.ebrahim moazzenNoch keine Bewertungen
- Guided Tuning ManualDokument3 SeitenGuided Tuning Manualspectrum777Noch keine Bewertungen
- ISD1820 Voice Recorder Module User Guide: Rev 1.0, Oct 2012Dokument5 SeitenISD1820 Voice Recorder Module User Guide: Rev 1.0, Oct 2012HARFA industriesNoch keine Bewertungen
- Engagement : Rebecca StobaughDokument188 SeitenEngagement : Rebecca StobaughAli AhmadNoch keine Bewertungen
- Parts Catalogue YAMAHA ET-1Dokument18 SeitenParts Catalogue YAMAHA ET-1walterfrano6523Noch keine Bewertungen
- Analysis of Transfer Lines: UNIT-3 Automation Manufracturing PvpsitDokument14 SeitenAnalysis of Transfer Lines: UNIT-3 Automation Manufracturing PvpsitSravanth KondetiNoch keine Bewertungen
- 7.proceeding Snib-Eng Dept, Pnp-IndonesiaDokument11 Seiten7.proceeding Snib-Eng Dept, Pnp-IndonesiamissfifitNoch keine Bewertungen
- DR TahaniCV 2012Dokument5 SeitenDR TahaniCV 2012Yousif_AbdalhalimNoch keine Bewertungen
- Akash IntenshipDokument28 SeitenAkash IntenshipAkash TaradaleNoch keine Bewertungen