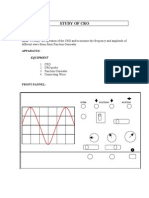
Das könnte Ihnen auch gefallen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- G.O For PHMED Interstate Transfers PDFDokument10 SeitenG.O For PHMED Interstate Transfers PDFEE PH KHAMMAMNoch keine Bewertungen
- Balcons Loggias Garde CorpsDokument3 SeitenBalcons Loggias Garde CorpsNazim KASSABNoch keine Bewertungen
- Static Analysis Laterally Loaded Pile Design PPTX CaliendoDokument55 SeitenStatic Analysis Laterally Loaded Pile Design PPTX CaliendoAshishNoch keine Bewertungen
- Investigation of Chloro Pentaammine Cobalt (III) Chloride - Polyvinyl Alcohol CompositesDokument5 SeitenInvestigation of Chloro Pentaammine Cobalt (III) Chloride - Polyvinyl Alcohol CompositesAlexander DeckerNoch keine Bewertungen
- Pumping MachinesDokument2 SeitenPumping MachinesKerwinPerezNoch keine Bewertungen
- Steel Castings HandbookDokument58 SeitenSteel Castings Handbookgalici2002100% (3)
- Modul Perefect Score Matematik Tambahan Melaka 2014Dokument65 SeitenModul Perefect Score Matematik Tambahan Melaka 2014Muhammad Hazwan RahmanNoch keine Bewertungen
- Texas Essential Knowledge and Skills (TEKS) : Lesson Plan Type: Inquiry Based Learning, Discovery Learning and DiscussionDokument13 SeitenTexas Essential Knowledge and Skills (TEKS) : Lesson Plan Type: Inquiry Based Learning, Discovery Learning and Discussionapi-322902620Noch keine Bewertungen
- CRODokument4 SeitenCROboopathy566Noch keine Bewertungen
- Method of Calculating TonicityDokument22 SeitenMethod of Calculating TonicityNajma Annuria FithriNoch keine Bewertungen
- Relative Humidity: CalculationDokument6 SeitenRelative Humidity: CalculationAnto FumiantNoch keine Bewertungen
- Tutorial 1 - Getting Started On EnergyPlus - 20120618 - 0Dokument28 SeitenTutorial 1 - Getting Started On EnergyPlus - 20120618 - 0PaulaErikaMANoch keine Bewertungen
- 6 Odinary Differential Equations NotesDokument11 Seiten6 Odinary Differential Equations NotesJadon TheophilusNoch keine Bewertungen
- Quizlet Com 8175072 Atpl Ins Formulas Flash CardsDokument6 SeitenQuizlet Com 8175072 Atpl Ins Formulas Flash Cardsnathan zizekNoch keine Bewertungen
- Wetscrubber VenturiDokument10 SeitenWetscrubber Venturiakifah100% (1)
- Tapas Question Paper 2017 PDFDokument20 SeitenTapas Question Paper 2017 PDFRamesh G100% (1)
- A Seminar On MetaphysicsDokument26 SeitenA Seminar On MetaphysicsMark Anthony DacelaNoch keine Bewertungen
- Gravitation - JEE Main 2024 January Question Bank - MathonGoDokument4 SeitenGravitation - JEE Main 2024 January Question Bank - MathonGoAnil KhandekarNoch keine Bewertungen
- Steel DesignDokument3 SeitenSteel Designriz2010Noch keine Bewertungen
- Fiberbond Fiberglass Piping Systems Series 110FW: DescriptionDokument2 SeitenFiberbond Fiberglass Piping Systems Series 110FW: DescriptionIbhar Santos MumentheyNoch keine Bewertungen
- THERMOREGULATIONDokument8 SeitenTHERMOREGULATIONDewiSartikaNoch keine Bewertungen
- Forces & Motion, IGCSEDokument4 SeitenForces & Motion, IGCSEsapiniNoch keine Bewertungen
- 12 M High Retaining Wall Design For Seismic LoadingDokument27 Seiten12 M High Retaining Wall Design For Seismic Loadingaminjoles0% (1)
- StructuralMechanicsModuleUsersGuide PDFDokument420 SeitenStructuralMechanicsModuleUsersGuide PDFFrancisco RibeiroNoch keine Bewertungen
- Part A1 Chapter 2 - ASME Code Calculations Stayed Surfaces Safety Valves FurnacesDokument25 SeitenPart A1 Chapter 2 - ASME Code Calculations Stayed Surfaces Safety Valves Furnacesfujiman35100% (1)
- ET205 Densimeter RepairDokument191 SeitenET205 Densimeter RepairFredyMirreNoch keine Bewertungen
- Vector Calculus+ShawDokument336 SeitenVector Calculus+Shawrichardfisica100% (1)
- 000 Free Energy Ac GeneratorDokument5 Seiten000 Free Energy Ac GeneratorKatamba Rogers100% (1)
- Thicken Er Design and ControlDokument20 SeitenThicken Er Design and ControlHarshalNoch keine Bewertungen
- Combustion Process SimulationDokument6 SeitenCombustion Process SimulationKingsley Etornam AnkuNoch keine Bewertungen