Das könnte Ihnen auch gefallen
- Mahadiscom JuneDokument2 SeitenMahadiscom JuneMumbai AcademicsNoch keine Bewertungen
- Sensitive Label Privacy Protection On Social Network DataDokument9 SeitenSensitive Label Privacy Protection On Social Network DataMumbai AcademicsNoch keine Bewertungen
- SpringDokument65 SeitenSpringMumbai AcademicsNoch keine Bewertungen
- Detecting Malicious Facebook ApplicationsDokument14 SeitenDetecting Malicious Facebook ApplicationsMumbai AcademicsNoch keine Bewertungen
- Virtual Classroom-@mumbai-AcademicsDokument8 SeitenVirtual Classroom-@mumbai-AcademicsMumbai AcademicsNoch keine Bewertungen
- VideoStegnography (Synopsis) @mumbai AcademicsDokument17 SeitenVideoStegnography (Synopsis) @mumbai AcademicsMumbai AcademicsNoch keine Bewertungen
- Tic Toe Game-@mumbai-AcademicsDokument9 SeitenTic Toe Game-@mumbai-AcademicsMumbai AcademicsNoch keine Bewertungen
- ImageStegnography (Synopsis) @mumbai AcademicsDokument7 SeitenImageStegnography (Synopsis) @mumbai AcademicsMumbai AcademicsNoch keine Bewertungen
- Human Face Identification-@mumbai-AcademicsDokument5 SeitenHuman Face Identification-@mumbai-AcademicsMumbai AcademicsNoch keine Bewertungen
- SNMPSimulatorDokument7 SeitenSNMPSimulatorMumbai AcademicsNoch keine Bewertungen
- (Synopsis) GoverLanScanner @mumbai AcademicsDokument8 Seiten(Synopsis) GoverLanScanner @mumbai AcademicsMumbai AcademicsNoch keine Bewertungen
- Text Editor-@mumbai-AcademicsDokument6 SeitenText Editor-@mumbai-AcademicsMumbai AcademicsNoch keine Bewertungen
- Accelerator-@mumbai-AcademicsDokument2 SeitenAccelerator-@mumbai-AcademicsMumbai AcademicsNoch keine Bewertungen
- Bankingsystems (Synopsis) @mumbai AcademicsDokument7 SeitenBankingsystems (Synopsis) @mumbai AcademicsMumbai AcademicsNoch keine Bewertungen
- Desktop Videoconference-@mumbai-AcademicsDokument11 SeitenDesktop Videoconference-@mumbai-AcademicsMumbai AcademicsNoch keine Bewertungen
- (Synopsis) ErrortrackingsystemDokument7 Seiten(Synopsis) ErrortrackingsystemMumbai AcademicsNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- SEO Audit Sample PDFDokument10 SeitenSEO Audit Sample PDFFoLLow mENoch keine Bewertungen
- Csip 2016Dokument2 SeitenCsip 2016CS & ITNoch keine Bewertungen
- Microwave Network Planning and Design - Frequency PlanningDokument38 SeitenMicrowave Network Planning and Design - Frequency PlanningAdesoji Lawal100% (1)
- Cse Btech2016-17Dokument25 SeitenCse Btech2016-17Vruttant Balde (Nyuke)Noch keine Bewertungen
- Motorola SBV6220 Data SheetDokument4 SeitenMotorola SBV6220 Data SheetBenjamin DoverNoch keine Bewertungen
- Breaking SLL With SllstripDokument14 SeitenBreaking SLL With SllstripsfdsgturtjNoch keine Bewertungen
- RRU3965&RRU3965d Description: Huawei Technologies Co., LTDDokument22 SeitenRRU3965&RRU3965d Description: Huawei Technologies Co., LTDercanaktas100% (2)
- Quick Guide - Restore Default PasswordDokument13 SeitenQuick Guide - Restore Default PasswordluisvillasecaretoNoch keine Bewertungen
- CIS NGINX Benchmark v1.0.0 PDFDokument132 SeitenCIS NGINX Benchmark v1.0.0 PDFkagisomNoch keine Bewertungen
- Online Documentation For Altium Products - CircuitMaker - ( (FAQs) ) - 2016-03-10Dokument27 SeitenOnline Documentation For Altium Products - CircuitMaker - ( (FAQs) ) - 2016-03-10Eddie M. KaufmannNoch keine Bewertungen
- PSG College of Technology, Coimbatore: Department of Instrumentation and Control Systems EngineeringDokument17 SeitenPSG College of Technology, Coimbatore: Department of Instrumentation and Control Systems Engineering18U208 - ARJUN ANoch keine Bewertungen
- Fortigate 80C QuickstartDokument2 SeitenFortigate 80C QuickstartZbrda ZdolaNoch keine Bewertungen
- Sh79f166 App - Note v2.1Dokument21 SeitenSh79f166 App - Note v2.1nongNoch keine Bewertungen
- MCQs On Computer by Dr. Alok KumarDokument151 SeitenMCQs On Computer by Dr. Alok KumarGtxpreetNoch keine Bewertungen
- OpenScape Voice V7 Brief Overview - V7R1Dokument16 SeitenOpenScape Voice V7 Brief Overview - V7R1Md AlauddinNoch keine Bewertungen
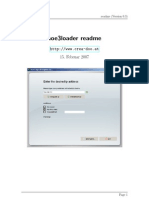
- Aoe3loader Readme 0.3Dokument3 SeitenAoe3loader Readme 0.3jmathis9223Noch keine Bewertungen
- 17 Ijcse 01468Dokument7 Seiten17 Ijcse 01468sai takanomeNoch keine Bewertungen
- Microsoft Word - Wikipedia, The Free EncyclopediaDokument14 SeitenMicrosoft Word - Wikipedia, The Free Encyclopediabeta2009Noch keine Bewertungen
- Raspberry PiDokument16 SeitenRaspberry PiHema Anilkumar100% (1)
- Evaluation of MinstrelDokument6 SeitenEvaluation of MinstrelSIDDESH L CNoch keine Bewertungen
- Intelligent Contact Management Solution: Software PBX, IVR, CTI BasedDokument17 SeitenIntelligent Contact Management Solution: Software PBX, IVR, CTI Basedki leeNoch keine Bewertungen
- Assignment 2Dokument4 SeitenAssignment 2JobaliskNoch keine Bewertungen
- XD1150 1250 SGDokument168 SeitenXD1150 1250 SGimdmutasaNoch keine Bewertungen
- NTG 2017 Evolutions in Wireless Access Domain and Microwaves v1.0Dokument93 SeitenNTG 2017 Evolutions in Wireless Access Domain and Microwaves v1.0SORO YALAMOUSSANoch keine Bewertungen
- Internet Edge Implementation GuideDokument63 SeitenInternet Edge Implementation Guideopenid_dr4OPAdENoch keine Bewertungen
- Module - 07 F2833x PWM, Capture and QEPDokument90 SeitenModule - 07 F2833x PWM, Capture and QEPMaria MEKLINoch keine Bewertungen
- ETX-203AM: Universal Carrier Ethernet Demarcation DeviceDokument8 SeitenETX-203AM: Universal Carrier Ethernet Demarcation Devicechinkayaby16Noch keine Bewertungen
- N61PB-M2S 090918Dokument47 SeitenN61PB-M2S 090918Juan Bascuñán YevenesNoch keine Bewertungen
- Improve Your Portrait Shots!Dokument140 SeitenImprove Your Portrait Shots!api-3808225Noch keine Bewertungen
- EC6711-Embedded Lab MannualDokument149 SeitenEC6711-Embedded Lab MannualvinothNoch keine Bewertungen