Das könnte Ihnen auch gefallen
- Concrete and Essential OilsDokument51 SeitenConcrete and Essential Oilssony9680% (1)
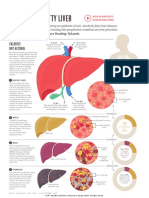
- Fatty LiverDokument2 SeitenFatty LiverKarla Edith Rodriguez Nava100% (2)
- Oncology 101: Cancer BasicsDokument74 SeitenOncology 101: Cancer BasicsMary Rose Jose GragasinNoch keine Bewertungen
- Mark Scheme (Results) October 2020: Pearson Edexcel International Advanced Subsidiary Level in Biology (WBI12) Paper 01Dokument27 SeitenMark Scheme (Results) October 2020: Pearson Edexcel International Advanced Subsidiary Level in Biology (WBI12) Paper 01Ahmad Luqman100% (2)
- Kalish GI ProtocolsDokument5 SeitenKalish GI Protocolsgoosenl100% (1)
- Complete Nucleotide Sequence of The Sugarcane (Four Monocot Chloroplast GenomesDokument7 SeitenComplete Nucleotide Sequence of The Sugarcane (Four Monocot Chloroplast GenomesmemorieleNoch keine Bewertungen
- Cladistic Relationships Among The Pleurotus Ostreatus Complex, The Pleurotus Pulmonarius Complex, and Pleurotus Eryngii Based On The Mitochondrial Small Subunit Ribosomal DNA Sequence AnalysisDokument6 SeitenCladistic Relationships Among The Pleurotus Ostreatus Complex, The Pleurotus Pulmonarius Complex, and Pleurotus Eryngii Based On The Mitochondrial Small Subunit Ribosomal DNA Sequence AnalysisAlejandro Murillo V.Noch keine Bewertungen
- The Pineapple Genome and The Evolution of CAM PhotosynthesisDokument11 SeitenThe Pineapple Genome and The Evolution of CAM Photosynthesisomprakash2592Noch keine Bewertungen
- Ijms 21113778Dokument20 SeitenIjms 21113778Alejandro GutiérrezNoch keine Bewertungen
- Srep 04089Dokument11 SeitenSrep 04089Patricia UntuNoch keine Bewertungen
- Plant Functional Genomics 99Dokument4 SeitenPlant Functional Genomics 99Vanessa GroberNoch keine Bewertungen
- Dynamics of The Chili Pepper Transcriptome During Fruit DevelopmentDokument18 SeitenDynamics of The Chili Pepper Transcriptome During Fruit DevelopmentPamela AboytesNoch keine Bewertungen
- PNAS 1998 Martienssen 2021 6Dokument6 SeitenPNAS 1998 Martienssen 2021 6Aseliajulia JuliaNoch keine Bewertungen
- Genes 11080879Dokument12 SeitenGenes 11080879ΑΝΑΣΤΑΣΙΑ ΝΕΡΑΝΤΖΗNoch keine Bewertungen
- SSR Potato Genetic DiversityDokument9 SeitenSSR Potato Genetic DiversityM. Rehman Gul KhanNoch keine Bewertungen
- 1471 2164 11 726Dokument14 Seiten1471 2164 11 726Trần T. MơNoch keine Bewertungen
- CAM PlantDokument10 SeitenCAM PlantAficko Razaky PratamaNoch keine Bewertungen
- Development of Chloroplast Genome Resources For Peanut (Arachis Hypogaea L.) and Other Species of ArachisDokument11 SeitenDevelopment of Chloroplast Genome Resources For Peanut (Arachis Hypogaea L.) and Other Species of ArachisWulan NursyiamNoch keine Bewertungen
- Characterization of Anatolian Traditional Quince CultivarsDokument9 SeitenCharacterization of Anatolian Traditional Quince Cultivarsrichard.schumacherNoch keine Bewertungen
- New Haplotypes of Black-Bearded Tomb Bat (Taphozous Melanopogon) From Puncakwangi Cave (East Java, Indonesia)Dokument5 SeitenNew Haplotypes of Black-Bearded Tomb Bat (Taphozous Melanopogon) From Puncakwangi Cave (East Java, Indonesia)bambang awanNoch keine Bewertungen
- s12864 015 1534 0 PDFDokument18 Seitens12864 015 1534 0 PDFPrima HerdiantoNoch keine Bewertungen
- Haplotype-Phased Genome and Evolution of PhytonutrDokument29 SeitenHaplotype-Phased Genome and Evolution of PhytonutrDavid CultureNoch keine Bewertungen
- Agronomy 10 01182 v2887Dokument15 SeitenAgronomy 10 01182 v2887RITESH CHANDANoch keine Bewertungen
- Sequence Analysis of Cultivated Strawberry (Fragaria × Ananassa Duch.) Using Microdissected Single Somatic ChromosomesDokument10 SeitenSequence Analysis of Cultivated Strawberry (Fragaria × Ananassa Duch.) Using Microdissected Single Somatic ChromosomesEfrain Lazo CastillonNoch keine Bewertungen
- Exome Capture From SalivaDokument17 SeitenExome Capture From SalivaJobin John PR15BI1001Noch keine Bewertungen
- Indonesian Journal of BiotechnologyDokument6 SeitenIndonesian Journal of Biotechnologyandi reskiNoch keine Bewertungen
- Chromosome-Scale Genome Assembly of A Natural Diploid Kiwifruit (Actinidia Chinensis VarDokument9 SeitenChromosome-Scale Genome Assembly of A Natural Diploid Kiwifruit (Actinidia Chinensis VarMARIA SHELLANE ARAÑEZNoch keine Bewertungen
- Transcriptome Sequencing of A Large Human Family Identifies The Impact of Rare Noncoding VariantsDokument12 SeitenTranscriptome Sequencing of A Large Human Family Identifies The Impact of Rare Noncoding VariantsJacintoOrozcoSamuelNoch keine Bewertungen
- Research Papers On Molecular Genetics PDFDokument7 SeitenResearch Papers On Molecular Genetics PDFafmclccre100% (1)
- tmp3103 TMPDokument12 Seitentmp3103 TMPFrontiersNoch keine Bewertungen
- Chloroplast Genes Reveal Hybridity in Mango (Mangifera Indica L.)Dokument5 SeitenChloroplast Genes Reveal Hybridity in Mango (Mangifera Indica L.)Shailendra RajanNoch keine Bewertungen
- NGS From BSA Identifies A Dwarfism Gene in WatermelonDokument7 SeitenNGS From BSA Identifies A Dwarfism Gene in Watermelonfrau54000Noch keine Bewertungen
- A Simple Plant Polytene Chromosome SystemDokument4 SeitenA Simple Plant Polytene Chromosome Systemiancaruso27Noch keine Bewertungen
- 2015 Article 1815Dokument15 Seiten2015 Article 1815Houda LaatabiNoch keine Bewertungen
- PQ 0403001990Dokument6 SeitenPQ 0403001990Yuwono WibowoNoch keine Bewertungen
- Bulu BabiDokument17 SeitenBulu BabiAswad AffandiNoch keine Bewertungen
- Doritis Pulcherrima: Nuclear DNA Contents of Phalaenopsis Sp. andDokument5 SeitenDoritis Pulcherrima: Nuclear DNA Contents of Phalaenopsis Sp. andTallie ZeidlerNoch keine Bewertungen
- KB FileDokument18 SeitenKB FileKaushik BanikNoch keine Bewertungen
- tmpF2D0 TMPDokument7 SeitentmpF2D0 TMPFrontiersNoch keine Bewertungen
- Jurnal Kel 6Dokument8 SeitenJurnal Kel 6Rahmy KartikaNoch keine Bewertungen
- Forests 11 00469Dokument15 SeitenForests 11 00469Silvermist EiceliNoch keine Bewertungen
- Plant Genome Projects PDFDokument4 SeitenPlant Genome Projects PDFmanoj_rkl_07100% (1)
- Dai Et Al-2017-Plant Biotechnology JournalDokument34 SeitenDai Et Al-2017-Plant Biotechnology JournalMichellePezNoch keine Bewertungen
- Mitochondrial Genome of The Freshwater JellyfishDokument9 SeitenMitochondrial Genome of The Freshwater JellyfishyangNoch keine Bewertungen
- Genotyping by Sequencing in Almond: SNP Discovery, Linkage Mapping, and Marker DesignDokument12 SeitenGenotyping by Sequencing in Almond: SNP Discovery, Linkage Mapping, and Marker DesignNicol TatelNoch keine Bewertungen
- Chloroplast Polymorphisms in Lodgepole and Jack Pines and Their HybridsDokument4 SeitenChloroplast Polymorphisms in Lodgepole and Jack Pines and Their HybridsJorgeVictorMauriceLiraNoch keine Bewertungen
- Assembly of The Durian Chloroplast Genome Using Long Pacbio ReadsDokument8 SeitenAssembly of The Durian Chloroplast Genome Using Long Pacbio ReadsFauzanNoch keine Bewertungen
- (2015) Paenibacilluspuernese Sp. Nov., A Β-glucosidase-producing Bacterium Isolated From Pu'Er TeaDokument7 Seiten(2015) Paenibacilluspuernese Sp. Nov., A Β-glucosidase-producing Bacterium Isolated From Pu'Er TeaLeonardo LopesNoch keine Bewertungen
- Plant Genome ProjectDokument5 SeitenPlant Genome Projectsamina iqbal100% (1)
- Molecular Characterization of A cDNA Clone Encoding Glutamine Synthetase From A Gymnosperm, Pinus Sylvestris, PMBDokument10 SeitenMolecular Characterization of A cDNA Clone Encoding Glutamine Synthetase From A Gymnosperm, Pinus Sylvestris, PMBAngel GarciaNoch keine Bewertungen
- SRMV RTDokument8 SeitenSRMV RTAlejandra SalamandraNoch keine Bewertungen
- TMP 58 BDokument9 SeitenTMP 58 BFrontiersNoch keine Bewertungen
- PDA-Global Oct 2011 Poster MR2Dokument1 SeitePDA-Global Oct 2011 Poster MR2sblazej7118Noch keine Bewertungen
- Jannotti Passos, 2010Dokument8 SeitenJannotti Passos, 2010xicoalexandreNoch keine Bewertungen
- The Complete Chloroplast Genome and Phylogenetic Analysis of Sida Szechuensis Matsuda MalvaceaeDokument3 SeitenThe Complete Chloroplast Genome and Phylogenetic Analysis of Sida Szechuensis Matsuda MalvaceaeIgnacio Jiménez VélizNoch keine Bewertungen
- Kohlmann Kersten New 1 2017Dokument7 SeitenKohlmann Kersten New 1 2017Elena TaflanNoch keine Bewertungen
- 2010 (Quin Et Al.) A Human Gut Microbial Gene Catalogue Established by Metagenomic SequencingDokument9 Seiten2010 (Quin Et Al.) A Human Gut Microbial Gene Catalogue Established by Metagenomic SequencingDaniel AlonsoNoch keine Bewertungen
- Analysis of Genetic Diversity and Phylogenetic Relationships in Crocus Genus of Iran Using Inter-Retrotransposon Amplified PolymorphismDokument6 SeitenAnalysis of Genetic Diversity and Phylogenetic Relationships in Crocus Genus of Iran Using Inter-Retrotransposon Amplified PolymorphismHenary ChongthamNoch keine Bewertungen
- tmp85B7 TMPDokument11 Seitentmp85B7 TMPFrontiersNoch keine Bewertungen
- 2050 2389 1 3 PDFDokument12 Seiten2050 2389 1 3 PDFAyman RabieNoch keine Bewertungen
- Unknown - 2010 - Book Announcements Book ShelfDokument209 SeitenUnknown - 2010 - Book Announcements Book Shelfmarcos_de_carvalhoNoch keine Bewertungen
- Iove Ne 2013Dokument10 SeitenIove Ne 2013harry jonesNoch keine Bewertungen
- Ijms 21 01344 v2Dokument17 SeitenIjms 21 01344 v2Diane Fernandez BenesioNoch keine Bewertungen
- 1723 UploadDokument5 Seiten1723 UploadbodhidharNoch keine Bewertungen
- Gene Flow: Monitoring, Modeling and MitigationVon EverandGene Flow: Monitoring, Modeling and MitigationWei WeiNoch keine Bewertungen
- Maru Bagwani Pomegranate Physiological DisordersDokument5 SeitenMaru Bagwani Pomegranate Physiological Disorderssony968Noch keine Bewertungen
- PGS Letter - Merit Medal Best Students Year 2021Dokument2 SeitenPGS Letter - Merit Medal Best Students Year 2021sony968Noch keine Bewertungen
- Vigyan Garima Sindhu 2018Dokument142 SeitenVigyan Garima Sindhu 2018sony968Noch keine Bewertungen
- Phal Phool Nov Dec 2019Dokument5 SeitenPhal Phool Nov Dec 2019sony968Noch keine Bewertungen
- Phal Phool Sept Oct 2020Dokument6 SeitenPhal Phool Sept Oct 2020sony968Noch keine Bewertungen
- Phal Phool Sept Oct 2019Dokument5 SeitenPhal Phool Sept Oct 2019sony968Noch keine Bewertungen
- Phal Phool July Aug 2019Dokument6 SeitenPhal Phool July Aug 2019sony968Noch keine Bewertungen
- 408 Pooja Shinde PROJECTDokument35 Seiten408 Pooja Shinde PROJECTPooja ShindeNoch keine Bewertungen
- Bio2 Test 3Dokument16 SeitenBio2 Test 3Carrie NortonNoch keine Bewertungen
- Nadiparikshan 1Dokument42 SeitenNadiparikshan 1AmitNoch keine Bewertungen
- Cnvert 1-Halaman-392-397Dokument6 SeitenCnvert 1-Halaman-392-397atma cansNoch keine Bewertungen
- Characteristics of Living OrganismsDokument71 SeitenCharacteristics of Living OrganismsNishant JainNoch keine Bewertungen
- Dental HistologyDokument65 SeitenDental HistologyMustafa H. KadhimNoch keine Bewertungen
- Fraga - 2005 - Epigenetic Differences Arise During The Lifetime of Mono Zygotic TwinsDokument6 SeitenFraga - 2005 - Epigenetic Differences Arise During The Lifetime of Mono Zygotic TwinstechnopsychNoch keine Bewertungen
- SD BIOLINE HIV 12 3.0 BrochureDokument2 SeitenSD BIOLINE HIV 12 3.0 BrochureDina Friance ManihurukNoch keine Bewertungen
- Conspectus of The Bulgarian Vascular Flora. Third EditionDokument454 SeitenConspectus of The Bulgarian Vascular Flora. Third EditionBoris AssyovNoch keine Bewertungen
- Q2 Sci3Dokument5 SeitenQ2 Sci3Yunilyn GallardoNoch keine Bewertungen
- Term Paper ON: Transgenic PlantsDokument17 SeitenTerm Paper ON: Transgenic PlantsVikal RajputNoch keine Bewertungen
- Catalog Life SciencesDokument15 SeitenCatalog Life SciencesSasmita NayakNoch keine Bewertungen
- FAQs: Dr. Sarojini SahooDokument4 SeitenFAQs: Dr. Sarojini SahooSarojini SahooNoch keine Bewertungen
- Extracting DNA From PeasDokument4 SeitenExtracting DNA From Peasradhika somayyaNoch keine Bewertungen
- BC34.1 E5 Isolation of DNA From Bovine SpleenDokument4 SeitenBC34.1 E5 Isolation of DNA From Bovine SpleenGlenn Vincent TumimbangNoch keine Bewertungen
- Kami Export - Mya Bennett - Intro To Cells Recap by Amoeba SistersDokument2 SeitenKami Export - Mya Bennett - Intro To Cells Recap by Amoeba SistersMya BennettNoch keine Bewertungen
- Preclass Quiz 14 - Fa19 - MOLECULAR BIOLOGY (47940) PDFDokument4 SeitenPreclass Quiz 14 - Fa19 - MOLECULAR BIOLOGY (47940) PDFElizabeth DouglasNoch keine Bewertungen
- Applications of Next Generation SequencinginhematologyDokument6 SeitenApplications of Next Generation SequencinginhematologyAbhishek SharmaNoch keine Bewertungen
- About ThalassaemiaDokument192 SeitenAbout Thalassaemiafarah0001Noch keine Bewertungen
- Modul FisTan 1Dokument45 SeitenModul FisTan 1RafliNoch keine Bewertungen
- Netters Essential Histology With Student Consult Access 2nd Edition Ovalle Test BankDokument35 SeitenNetters Essential Histology With Student Consult Access 2nd Edition Ovalle Test Bankjacobnigordon100% (14)
- IAL Timetable January 2018 FinalDokument18 SeitenIAL Timetable January 2018 FinalAminul Islam IshmamNoch keine Bewertungen
- Glukoneogenesis: Prof - Dr. Suhartati, DR., MSDokument25 SeitenGlukoneogenesis: Prof - Dr. Suhartati, DR., MSDinda DhitaNoch keine Bewertungen
- Herb-All Organic (Treatment For Cancer) : How It WorksDokument44 SeitenHerb-All Organic (Treatment For Cancer) : How It WorksJohn Patrick MuzanyiNoch keine Bewertungen
- Importanceof CarbohydratesDokument3 SeitenImportanceof CarbohydratescraigNoch keine Bewertungen
- Enterovirus 71 Outbreaks, Taiwan: Occurrence and RecognitionDokument3 SeitenEnterovirus 71 Outbreaks, Taiwan: Occurrence and RecognitionAdhi SyukriNoch keine Bewertungen