Das könnte Ihnen auch gefallen
- 6th Central Pay Commission Salary CalculatorDokument15 Seiten6th Central Pay Commission Salary Calculatorrakhonde100% (436)
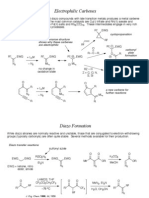
- Carbenoids 2Dokument15 SeitenCarbenoids 2costea0028Noch keine Bewertungen
- Acronyms On Organic ChemistryDokument5 SeitenAcronyms On Organic ChemistryBruno NoschangNoch keine Bewertungen
- Foundations of Human Behavior: Session 2Dokument34 SeitenFoundations of Human Behavior: Session 2costea0028Noch keine Bewertungen
- CodeDokument6 SeitenCodecostea0028Noch keine Bewertungen
- Carbenoids 2Dokument15 SeitenCarbenoids 2costea0028Noch keine Bewertungen
- GBMDokument1 SeiteGBMcostea0028Noch keine Bewertungen
- New Text DocumentDokument1 SeiteNew Text Documentcostea0028Noch keine Bewertungen
- Diplodocus BabyDokument2 SeitenDiplodocus Babycostea0028Noch keine Bewertungen
- Read MeDokument1 SeiteRead Mecostea0028Noch keine Bewertungen
- CodeDokument6 SeitenCodecostea0028Noch keine Bewertungen
- New Text DocumentDokument1 SeiteNew Text Documentcostea0028Noch keine Bewertungen
- Domain Specific Keyword ExtractionDokument6 SeitenDomain Specific Keyword Extractioncostea0028Noch keine Bewertungen
- Transactions Journals PDFDokument9 SeitenTransactions Journals PDFEdo Liu Nurfuji DayantakaNoch keine Bewertungen
- Advances and Challenges in Log - Adam Oliner, Archana GanapathiDokument7 SeitenAdvances and Challenges in Log - Adam Oliner, Archana Ganapathicostea0028Noch keine Bewertungen
- TIGBook Chpt12Dokument8 SeitenTIGBook Chpt12costea0028Noch keine Bewertungen
- New Text DocumentDokument1 SeiteNew Text Documentcostea0028Noch keine Bewertungen
- Origami TheoryDokument29 SeitenOrigami TheoryAleksandar NikolicNoch keine Bewertungen
- Effective PresentationsDokument53 SeitenEffective Presentationssociologist_43Noch keine Bewertungen
- Mozart 40Dokument13 SeitenMozart 40costea0028Noch keine Bewertungen
- Ibr 2007Dokument488 SeitenIbr 2007costea0028Noch keine Bewertungen
- HP 50g Graphing Calculator Advanced User's Reference Manual PDFDokument693 SeitenHP 50g Graphing Calculator Advanced User's Reference Manual PDFChristian D. OrbeNoch keine Bewertungen
- DocumentDokument1 SeiteDocumentcostea0028Noch keine Bewertungen
- ShareDokument1 SeiteSharecostea0028Noch keine Bewertungen
- Pages 9-66 From Complete Idler Roller CatalogDokument59 SeitenPages 9-66 From Complete Idler Roller CatalogjashmithNoch keine Bewertungen
- Getting Started With MediaFire PDFDokument6 SeitenGetting Started With MediaFire PDFDiego Alejandro Alonso LopezNoch keine Bewertungen
- Belt Conveyor 2Dokument27 SeitenBelt Conveyor 2muruganNoch keine Bewertungen
- FBMDokument16 SeitenFBMcostea0028Noch keine Bewertungen
- Imp DatesDokument1 SeiteImp Datescostea0028Noch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- BOA Emulator Software Installation Guide 175xDokument8 SeitenBOA Emulator Software Installation Guide 175xbrunomarmeNoch keine Bewertungen
- Workstation 8-9-10, Player 4 - 5 - 6 and Fusion 4 - 5 - 6 Mac OS X Unlocker - Multi-Booting and Virtualisation - InsanelyMac ForumDokument7 SeitenWorkstation 8-9-10, Player 4 - 5 - 6 and Fusion 4 - 5 - 6 Mac OS X Unlocker - Multi-Booting and Virtualisation - InsanelyMac ForumorangotaNoch keine Bewertungen
- Function Trend Control V 7Dokument58 SeitenFunction Trend Control V 7Muhamed AlmaNoch keine Bewertungen
- Bubble SortDokument29 SeitenBubble SortBhavneet KaurNoch keine Bewertungen
- PsDokument4 SeitenPsNihat GöçmezNoch keine Bewertungen
- Data Analytics TechniquesDokument10 SeitenData Analytics Techniqueskumar3544Noch keine Bewertungen
- IT207-NQ2012-Stwbk-Database Development (Basic) (1) .pdf11 - 05 - 2013 - 03 - 07 - 16 PDFDokument45 SeitenIT207-NQ2012-Stwbk-Database Development (Basic) (1) .pdf11 - 05 - 2013 - 03 - 07 - 16 PDFSUBHABRATA MITRANoch keine Bewertungen
- InstruccionesDokument23 SeitenInstruccionesSolo Yamaha SrxNoch keine Bewertungen
- Project Name Business Requirements Document (BRD) TemplateDokument24 SeitenProject Name Business Requirements Document (BRD) TemplatePankaj KumarNoch keine Bewertungen
- 2.6.1.2 Lab - Securing The Router For Administrative Access - UnlockedDokument44 Seiten2.6.1.2 Lab - Securing The Router For Administrative Access - UnlockedAlonso Chi CitukNoch keine Bewertungen
- Multimedia System DesignDokument95 SeitenMultimedia System DesignRishi Aeri100% (1)
- CVE-2012-1889: Security Update AnalysisDokument27 SeitenCVE-2012-1889: Security Update AnalysisHigh-Tech BridgeNoch keine Bewertungen
- What Are Update AnomaliesDokument44 SeitenWhat Are Update AnomaliesAlex LeeNoch keine Bewertungen
- C and Data Structures Q and ADokument267 SeitenC and Data Structures Q and AAnandaKrishna SridharNoch keine Bewertungen
- 24 Online User GuideDokument161 Seiten24 Online User GuideGiscard SibefoNoch keine Bewertungen
- CS504 Mcqs Big FileDokument129 SeitenCS504 Mcqs Big FileAmjad AliNoch keine Bewertungen
- Summertime Saga Log ExpDokument6 SeitenSummertime Saga Log Expbaha58600% (1)
- Technical ReportDokument17 SeitenTechnical ReportAsif Ekram100% (2)
- Bu CyrusDokument2 SeitenBu CyrusJhon Charlie Alvarez RodriguezNoch keine Bewertungen
- Connecting SAP Through Microsoft Direct AccessDokument4 SeitenConnecting SAP Through Microsoft Direct AccessKalyanaNoch keine Bewertungen
- Assignment 1 Network SecurityDokument5 SeitenAssignment 1 Network SecuritySaeed AhmedNoch keine Bewertungen
- Debugger FundamentalsDokument49 SeitenDebugger FundamentalscbrigatiNoch keine Bewertungen
- ISM v3 Module 1 - Elearning - SRGDokument18 SeitenISM v3 Module 1 - Elearning - SRGVikasSharmaNoch keine Bewertungen
- YadeDokument618 SeitenYadeAFrancisco198Noch keine Bewertungen
- Implementing HP 3par Storeserv 7000 and Proliant Dl380 Gen8 With Microsoft Exchange 2010Dokument37 SeitenImplementing HP 3par Storeserv 7000 and Proliant Dl380 Gen8 With Microsoft Exchange 2010Edgar Orlando Bermúdez AljuriNoch keine Bewertungen
- S7-200 Smart PLC Catalog 2016Dokument32 SeitenS7-200 Smart PLC Catalog 2016Jorge_Andril_5370Noch keine Bewertungen
- Class Element El1, El2, El3: Selector Example SelectsDokument1 SeiteClass Element El1, El2, El3: Selector Example SelectsElvis KadicNoch keine Bewertungen
- CS6212 PDS Lab Manual CSE 2013 RegulationsDokument52 SeitenCS6212 PDS Lab Manual CSE 2013 RegulationsheyramzzNoch keine Bewertungen
- Cache MemoryDokument10 SeitenCache MemoryasrNoch keine Bewertungen
- Orthorect AerialDokument12 SeitenOrthorect AerialMohamedAlaminNoch keine Bewertungen