Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Client-Side Web Scripting Lecture NotesDokument1 SeiteClient-Side Web Scripting Lecture Notesdanielle leigh100% (1)
- Introduction I Eee 1471Dokument16 SeitenIntroduction I Eee 1471Ljupco TrajkovskiNoch keine Bewertungen
- PPS - Practical - Assignment - 1 To 5 PDFDokument10 SeitenPPS - Practical - Assignment - 1 To 5 PDFAthul Rajan100% (2)
- Tibco BW Faqs: What Is Aeschema?Dokument3 SeitenTibco BW Faqs: What Is Aeschema?Suresh VudayagiriNoch keine Bewertungen
- IMSDokument1 SeiteIMSkarthikspeedNoch keine Bewertungen
- Welcome Fast Recaptcha: Captchas Factories Finance Settings Tools Referrals HelpDokument2 SeitenWelcome Fast Recaptcha: Captchas Factories Finance Settings Tools Referrals HelpGabriel PuliattiNoch keine Bewertungen
- Ui Design Brief Template-3Dokument9 SeitenUi Design Brief Template-3api-287829607Noch keine Bewertungen
- Iqip Users GuideDokument580 SeitenIqip Users GuideFirstp LastlNoch keine Bewertungen
- Microsoft Azure Infographic 2014 PDFDokument1 SeiteMicrosoft Azure Infographic 2014 PDFkiranNoch keine Bewertungen
- Virtual MouseDokument59 SeitenVirtual MouseSajjad IdreesNoch keine Bewertungen
- Apache Solr PresentationDokument37 SeitenApache Solr PresentationNaman MukundNoch keine Bewertungen
- Esp32 Datasheet enDokument43 SeitenEsp32 Datasheet enRenato HernandezNoch keine Bewertungen
- Airline Reservation SystemDokument66 SeitenAirline Reservation SystemcharmivoraNoch keine Bewertungen
- Plant Simulation: Simulation and Optimization of Production Systems and ProcessesDokument2 SeitenPlant Simulation: Simulation and Optimization of Production Systems and ProcessesMateo QuispeNoch keine Bewertungen
- Classification Essay PDFDokument3 SeitenClassification Essay PDFAlvin MalquistoNoch keine Bewertungen
- Normalization in DBMSDokument17 SeitenNormalization in DBMShemacrcNoch keine Bewertungen
- Hi GuidelinesDokument232 SeitenHi GuidelinesLuis Humberto Martinez PalmethNoch keine Bewertungen
- Hemant Kumar Jain PDFDokument2 SeitenHemant Kumar Jain PDFRahulNoch keine Bewertungen
- Ict Trial 2013 Kerian Perak Answer 1Dokument7 SeitenIct Trial 2013 Kerian Perak Answer 1lielynsmkkmNoch keine Bewertungen
- Index 1. Two. Three. April. MayDokument18 SeitenIndex 1. Two. Three. April. MayMabu DbaNoch keine Bewertungen
- Bus ARbitrationDokument20 SeitenBus ARbitrationsubasrijayagopiNoch keine Bewertungen
- PIC24FJ128GADokument230 SeitenPIC24FJ128GAjosrocNoch keine Bewertungen
- Interview Habana Labs Targets AI ProcessorsDokument10 SeitenInterview Habana Labs Targets AI ProcessorsMark ChenNoch keine Bewertungen
- Enable SSO in SAP System Using Kerberos AuthenticationDokument10 SeitenEnable SSO in SAP System Using Kerberos AuthenticationPILLINAGARAJUNoch keine Bewertungen
- JDEDokument376 SeitenJDEphani87Noch keine Bewertungen
- Cp3 3 Constructor DestructorDokument36 SeitenCp3 3 Constructor DestructoragNoch keine Bewertungen
- Computer Concept and Web Technology: Cse 3Rd Semester Jkie BilaspurDokument98 SeitenComputer Concept and Web Technology: Cse 3Rd Semester Jkie Bilaspurmd.zainul haqueNoch keine Bewertungen
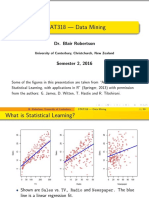
- STAT318 - Data Mining: Dr. Blair RobertsonDokument39 SeitenSTAT318 - Data Mining: Dr. Blair RobertsonCesilyNoch keine Bewertungen
- Turing Machine Assignment Questions on Languages, ProblemsDokument3 SeitenTuring Machine Assignment Questions on Languages, Problemscompiler&automataNoch keine Bewertungen
- Writing Games with PygameDokument25 SeitenWriting Games with PygameAline OliveiraNoch keine Bewertungen