Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- SCW PQSDokument67 SeitenSCW PQStabathadennis100% (1)
- Automotive Transmissions1Dokument0 SeitenAutomotive Transmissions1jin11004Noch keine Bewertungen
- Steganography Technique Based On DCT CoefficientsDokument5 SeitenSteganography Technique Based On DCT Coefficientsjin11004Noch keine Bewertungen
- Paper (4) 35 41Dokument7 SeitenPaper (4) 35 41jin11004Noch keine Bewertungen
- Converting DCT Coefficients To H.264/AVC: Mitsubishi Electric Research Laboratories, Inc., 2004Dokument11 SeitenConverting DCT Coefficients To H.264/AVC: Mitsubishi Electric Research Laboratories, Inc., 2004jin11004Noch keine Bewertungen
- Dct-Domain Blind Measurement of Blocking Artifacts in Dct-Coded ImagesDokument4 SeitenDct-Domain Blind Measurement of Blocking Artifacts in Dct-Coded Imagesjin11004Noch keine Bewertungen
- Beamer Technical Vienna Presentation v0425Dokument47 SeitenBeamer Technical Vienna Presentation v0425jin11004Noch keine Bewertungen
- Detecting Doctored PEG Images Via DCT Coefficient AnalysisDokument13 SeitenDetecting Doctored PEG Images Via DCT Coefficient Analysisjin11004Noch keine Bewertungen
- 010 Frank Sealing Systems 700BR01Dokument28 Seiten010 Frank Sealing Systems 700BR01Handy Han QuanNoch keine Bewertungen
- 3M Work Gloves BrochureDokument4 Seiten3M Work Gloves BrochureherminNoch keine Bewertungen
- Rehau Awadukt Thermo: Ground-Air Heat Exchanger System For Controlled VentilationDokument36 SeitenRehau Awadukt Thermo: Ground-Air Heat Exchanger System For Controlled VentilationLeon_68Noch keine Bewertungen
- Theory of ConstructivismDokument10 SeitenTheory of ConstructivismBulan Ialah KamarulNoch keine Bewertungen
- Powershell Simple and Effective Strategies To Execute Powershell Programming - Daniel JonesDokument53 SeitenPowershell Simple and Effective Strategies To Execute Powershell Programming - Daniel JonesdemisitoNoch keine Bewertungen
- JournalDokument13 SeitenJournalAnonymous 1uwOEpe5w8Noch keine Bewertungen
- Administration Guide Open Bee Doc Office Manager (En)Dokument31 SeitenAdministration Guide Open Bee Doc Office Manager (En)peka76100% (1)
- Century Lookbook CatalogueDokument162 SeitenCentury Lookbook Cataloguefwd2datta50% (2)
- Family LetterDokument2 SeitenFamily Letterapi-404033609Noch keine Bewertungen
- SAP LandscapeDokument4 SeitenSAP LandscapeSiddharth PriyabrataNoch keine Bewertungen
- GPS Ter Clock Appendix E: Network Settings of GPS Using PC Windows As TELNET ClientDokument9 SeitenGPS Ter Clock Appendix E: Network Settings of GPS Using PC Windows As TELNET ClientveerabossNoch keine Bewertungen
- Project PDFDokument13 SeitenProject PDFapi-697727439Noch keine Bewertungen
- Global Trends 2030 Preview: Interactive Le MenuDokument5 SeitenGlobal Trends 2030 Preview: Interactive Le MenuOffice of the Director of National Intelligence100% (1)
- Mercruiser GearcasecomponentsDokument42 SeitenMercruiser GearcasecomponentswguenonNoch keine Bewertungen
- Amces 2020Dokument1 SeiteAmces 2020Karthik GootyNoch keine Bewertungen
- Report On The Heritage City ProjectDokument23 SeitenReport On The Heritage City ProjectL'express Maurice100% (2)
- Factors Affecting Grade 12 Students To Use Internet During Class HourDokument39 SeitenFactors Affecting Grade 12 Students To Use Internet During Class HourJerric Brandon FalconiNoch keine Bewertungen
- How Many Sensors Should I Use in A Temperature Mapping StudyDokument10 SeitenHow Many Sensors Should I Use in A Temperature Mapping StudyyogiyogaNoch keine Bewertungen
- GD200A Manual EnglishDokument269 SeitenGD200A Manual Englishtran dieuNoch keine Bewertungen
- Summary Key ParameterDokument18 SeitenSummary Key ParameterAndry JatmikoNoch keine Bewertungen
- ID Green Tourism PDFDokument15 SeitenID Green Tourism PDFRanti RustikaNoch keine Bewertungen
- VC02 Brass Ball Valve Full Port Full BoreDokument2 SeitenVC02 Brass Ball Valve Full Port Full Boremahadeva1Noch keine Bewertungen
- Mahesh Chand CVDokument4 SeitenMahesh Chand CVMahesh NiralaNoch keine Bewertungen
- March Aprilwnissue2016Dokument100 SeitenMarch Aprilwnissue2016Upender BhatiNoch keine Bewertungen
- FPFH Standar InstallationDokument13 SeitenFPFH Standar InstallationYulius IrawanNoch keine Bewertungen
- SAP-Document Splitting: GL Account DR CR Profit Center Vendor Pur. 1 Pur. 2 TaxDokument16 SeitenSAP-Document Splitting: GL Account DR CR Profit Center Vendor Pur. 1 Pur. 2 Taxharshad jain100% (1)
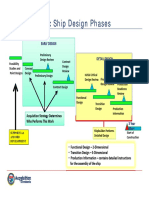
- Basic Ship Design PhasesDokument1 SeiteBasic Ship Design PhasesJhon GreigNoch keine Bewertungen
- Datasheet - HK f7313 39760Dokument7 SeitenDatasheet - HK f7313 39760niko67Noch keine Bewertungen
- U441d - Brake - Rear (Air)Dokument6 SeitenU441d - Brake - Rear (Air)bennieNoch keine Bewertungen