Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Feasibility Study Example 50Dokument9 SeitenFeasibility Study Example 50Utibe EdemNoch keine Bewertungen
- Feasibility Study Example 17Dokument6 SeitenFeasibility Study Example 17Utibe EdemNoch keine Bewertungen
- Feasibility Study Example 20Dokument16 SeitenFeasibility Study Example 20yassine Ben Kara AhmedNoch keine Bewertungen
- Feasibility Study Example 21Dokument16 SeitenFeasibility Study Example 21Abanob AdelNoch keine Bewertungen
- 5-Generral Syllabus Fifth YearDokument1 Seite5-Generral Syllabus Fifth Yearalnahary1Noch keine Bewertungen
- Feasibility Study Example 18Dokument5 SeitenFeasibility Study Example 18Utibe EdemNoch keine Bewertungen
- Presentation Title: My Name Contact Information or Project DescriptionDokument2 SeitenPresentation Title: My Name Contact Information or Project Descriptionalnahary1Noch keine Bewertungen
- Click To Edit Master Subtitle StyleDokument4 SeitenClick To Edit Master Subtitle Stylealnahary1Noch keine Bewertungen
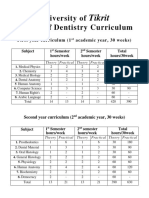
- Tikrit: University of College of Dentistry CurriculumDokument3 SeitenTikrit: University of College of Dentistry Curriculumalnahary1Noch keine Bewertungen
- Presentation TitleDokument2 SeitenPresentation Titlealnahary1Noch keine Bewertungen
- Presentation Title: My Name Contact Information or Project DescriptionDokument2 SeitenPresentation Title: My Name Contact Information or Project Descriptionalnahary1Noch keine Bewertungen
- Journal of Applied Econometrics PDFDokument2 SeitenJournal of Applied Econometrics PDFalnahary1Noch keine Bewertungen
- Click To Edit Master Subtitle StyleDokument4 SeitenClick To Edit Master Subtitle Stylealnahary1Noch keine Bewertungen
- Presentation Title: Your Company InformationDokument2 SeitenPresentation Title: Your Company Informationalnahary1Noch keine Bewertungen
- Journal of Applied Econometrics Volume 1 Issue 2 1986 (Doi 10.1002-Jae.3950010201) - MastheadDokument1 SeiteJournal of Applied Econometrics Volume 1 Issue 2 1986 (Doi 10.1002-Jae.3950010201) - Mastheadalnahary1Noch keine Bewertungen
- Presentation Title: Your Company InformationDokument2 SeitenPresentation Title: Your Company Informationalnahary1Noch keine Bewertungen
- Presentation TitleDokument2 SeitenPresentation Titlealnahary1Noch keine Bewertungen
- ACG3341 Gaukel 2013fallDokument9 SeitenACG3341 Gaukel 2013fallalnahary1Noch keine Bewertungen
- Presentation Title: My Name My Position, Contact Information or Project DescriptionDokument2 SeitenPresentation Title: My Name My Position, Contact Information or Project Descriptionalnahary1Noch keine Bewertungen
- 3025 Contract Powerpoint TemplateDokument5 Seiten3025 Contract Powerpoint Templatealnahary1Noch keine Bewertungen
- Journal of Applied Econometrics Volume 1 Issue 2 1986 (Doi 10.1002-Jae.3950010202) G. Ridder - An Event History Approach To The Evaluation of Training, Recruitment and Employment ProgrammesDokument18 SeitenJournal of Applied Econometrics Volume 1 Issue 2 1986 (Doi 10.1002-Jae.3950010202) G. Ridder - An Event History Approach To The Evaluation of Training, Recruitment and Employment Programmesalnahary1Noch keine Bewertungen
- Arab LeagueDokument7 SeitenArab Leaguealnahary1Noch keine Bewertungen
- Journal of Applied Econometrics Volume 1 Issue 2 1986 (Doi 10.1002-Jae.3950010207) - Calendar of EventsDokument2 SeitenJournal of Applied Econometrics Volume 1 Issue 2 1986 (Doi 10.1002-Jae.3950010207) - Calendar of Eventsalnahary1Noch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (120)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Proservo NMS53x Series: Operating ManualDokument116 SeitenProservo NMS53x Series: Operating Manualjohnf2328Noch keine Bewertungen
- Compiler DesignDokument47 SeitenCompiler DesignLearn UpNoch keine Bewertungen
- SAP FI/CO (Finance and Controlling) Notes Version: SAP 6.0 ECC ECC: Enterprise Central ComponentDokument203 SeitenSAP FI/CO (Finance and Controlling) Notes Version: SAP 6.0 ECC ECC: Enterprise Central ComponentCarlos GrossiNoch keine Bewertungen
- Man Inst Mru 5 r9Dokument148 SeitenMan Inst Mru 5 r9Miguel Martinez100% (1)
- Panel LCD m185xw01 - v8Dokument27 SeitenPanel LCD m185xw01 - v8Antonio ChavezNoch keine Bewertungen
- UniproUGENE UserManual PDFDokument304 SeitenUniproUGENE UserManual PDFvotanhung288Noch keine Bewertungen
- Quadratic PDF UploadDokument11 SeitenQuadratic PDF UploadNilansh RajputNoch keine Bewertungen
- Manual Druck DPI 145Dokument150 SeitenManual Druck DPI 145Tarcio CarvalhoNoch keine Bewertungen
- Riello 40 FsDokument7 SeitenRiello 40 FsNebojsaNoch keine Bewertungen
- Cloud Computing Book (2017-Regulation) PDF-1-89 Unit - I & IIDokument89 SeitenCloud Computing Book (2017-Regulation) PDF-1-89 Unit - I & IIVishnu Kumar KumarNoch keine Bewertungen
- Vicon Blade 3 ReferenceDokument192 SeitenVicon Blade 3 ReferencekoxaNoch keine Bewertungen
- How Robots and AI Are Creating The 21stDokument3 SeitenHow Robots and AI Are Creating The 21stHung DoNoch keine Bewertungen
- Development of Value Stream Mapping From L'Oreal's Artwork Process PDFDokument25 SeitenDevelopment of Value Stream Mapping From L'Oreal's Artwork Process PDFReuben AzavedoNoch keine Bewertungen
- Logistics & SCM SyllabusDokument1 SeiteLogistics & SCM SyllabusVignesh KhannaNoch keine Bewertungen
- 3.1 Faster - R-CNN - Towards - Real-Time - Object - Detection - With - Region - Proposal - NetworksDokument13 Seiten3.1 Faster - R-CNN - Towards - Real-Time - Object - Detection - With - Region - Proposal - NetworksAmrutasagar KavarthapuNoch keine Bewertungen
- Makerere University Entry Cutoff Points 2018-19Dokument58 SeitenMakerere University Entry Cutoff Points 2018-19kiryamwibo yenusu94% (16)
- 1853192227Dokument1 Seite1853192227Iulia MândruNoch keine Bewertungen
- CyberSecurityProjectProposal Semi FinalDokument15 SeitenCyberSecurityProjectProposal Semi FinalKevin kurt IntongNoch keine Bewertungen
- Ame Relay LabDokument6 SeitenAme Relay LabasegunloluNoch keine Bewertungen
- What Is A Digital Strategy?: What Is It About, and How Can It Be Laid Out?Dokument24 SeitenWhat Is A Digital Strategy?: What Is It About, and How Can It Be Laid Out?api-290841500Noch keine Bewertungen
- The Evolution of Project ManagementDokument5 SeitenThe Evolution of Project Managementcrib85Noch keine Bewertungen
- MN 04020003 eDokument204 SeitenMN 04020003 eLuis ReisNoch keine Bewertungen
- D StarDokument32 SeitenD Starshikha jainNoch keine Bewertungen
- BRSM Form 009 Qms MDD - TJDokument15 SeitenBRSM Form 009 Qms MDD - TJAnonymous q8lh3fldWMNoch keine Bewertungen
- Tugas Lk7 Dan 10 Garuda PancasilaDokument5 SeitenTugas Lk7 Dan 10 Garuda PancasilaarifuddinNoch keine Bewertungen
- HNS New OS 2021 AdamaDokument184 SeitenHNS New OS 2021 AdamabayushNoch keine Bewertungen
- Arthur Portas - November 2023Dokument6 SeitenArthur Portas - November 2023aminatjenius71Noch keine Bewertungen
- Why Is Research A Cyclical Process?Dokument17 SeitenWhy Is Research A Cyclical Process?Rodrick RamosNoch keine Bewertungen
- IQVIA Consumer Health Conference June 23Dokument84 SeitenIQVIA Consumer Health Conference June 23alina.rxa.tdrNoch keine Bewertungen
- Virtualizing SQL Server With Vmware Doing It Right Michael Corey PDFDokument42 SeitenVirtualizing SQL Server With Vmware Doing It Right Michael Corey PDFJuan Carlos FernandezNoch keine Bewertungen