Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1091)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Brinell Hardness Standard.Dokument32 SeitenBrinell Hardness Standard.Basker VenkataramanNoch keine Bewertungen
- Ebookdjj5113 Mechanics of Machines WatermarkDokument272 SeitenEbookdjj5113 Mechanics of Machines WatermarkXCarlZNoch keine Bewertungen
- Sep 02Dokument19 SeitenSep 02c_nghia100% (1)
- Chemguide Atom, MoleculeDokument28 SeitenChemguide Atom, MoleculeSabina SabaNoch keine Bewertungen
- The Analytic Hierarchy ProcessDokument3 SeitenThe Analytic Hierarchy ProcessFlorentina AndreNoch keine Bewertungen
- Polidoro FlappingDokument187 SeitenPolidoro FlappingHua Hidari YangNoch keine Bewertungen
- Solving Cubic Equations Roots Trough Cardano TartagliaDokument2 SeitenSolving Cubic Equations Roots Trough Cardano TartagliaClóvis Guerim VieiraNoch keine Bewertungen
- MTH302 Solved MCQs Alotof Solved MCQsof MTH302 InonefDokument26 SeitenMTH302 Solved MCQs Alotof Solved MCQsof MTH302 InonefiftiniaziNoch keine Bewertungen
- Array QuestionsDokument4 SeitenArray QuestionsmazlinaNoch keine Bewertungen
- Urdaneta City UniversityDokument2 SeitenUrdaneta City UniversityTheodore VilaNoch keine Bewertungen
- Measuring Units Worksheet: Name: - DateDokument2 SeitenMeasuring Units Worksheet: Name: - DateSumedha AgarwalNoch keine Bewertungen
- MMW Chapter 3Dokument82 SeitenMMW Chapter 3Marjorie MalvedaNoch keine Bewertungen
- JddumpsDokument58 SeitenJddumpsDeepa SureshNoch keine Bewertungen
- Impact of Cash Conversion Cycle On Firm's ProfitabilityDokument3 SeitenImpact of Cash Conversion Cycle On Firm's ProfitabilityAnonymous 7eO9enzNoch keine Bewertungen
- Sotoudeh Zahra 201108 PHDDokument110 SeitenSotoudeh Zahra 201108 PHDnoneofyourbusineesNoch keine Bewertungen
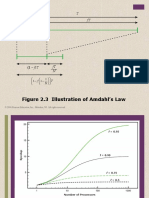
- Figure 2.3 Illustration of Amdahl's Law: © 2016 Pearson Education, Inc., Hoboken, NJ. All Rights ReservedDokument10 SeitenFigure 2.3 Illustration of Amdahl's Law: © 2016 Pearson Education, Inc., Hoboken, NJ. All Rights ReservedAhmed AyazNoch keine Bewertungen
- St501-Ln1kv 04fs EnglishDokument12 SeitenSt501-Ln1kv 04fs Englishsanthoshs241s0% (1)
- Geometry Class 6 Final ExamDokument4 SeitenGeometry Class 6 Final ExamTanzimNoch keine Bewertungen
- Pebl 2 ManualDokument306 SeitenPebl 2 ManualEstebanGiraNoch keine Bewertungen
- Applications of Linear AlgebraDokument4 SeitenApplications of Linear AlgebraTehmoor AmjadNoch keine Bewertungen
- Edexcel GCSE Maths Higher Paper 2 June 2022 Mark SchemeDokument26 SeitenEdexcel GCSE Maths Higher Paper 2 June 2022 Mark SchemeZia Saad ANSARINoch keine Bewertungen
- Course Notes MGT338 - Class 5Dokument3 SeitenCourse Notes MGT338 - Class 5Luciene20Noch keine Bewertungen
- MethodsDokument77 SeitenMethodsZahirah ZairulNoch keine Bewertungen
- Adelia Salsabila-Assign-5 2Dokument10 SeitenAdelia Salsabila-Assign-5 2Adelia SalsabilaNoch keine Bewertungen
- MA2401 Lecture NotesDokument270 SeitenMA2401 Lecture NotesJojo LomoNoch keine Bewertungen
- Mechanics of Tooth Movement: or SmithDokument14 SeitenMechanics of Tooth Movement: or SmithRamesh SakthyNoch keine Bewertungen
- Naac Lesson Plan Subject-WsnDokument6 SeitenNaac Lesson Plan Subject-WsnAditya Kumar TikkireddiNoch keine Bewertungen
- Taylor Introms11GE PPT 01Dokument27 SeitenTaylor Introms11GE PPT 01hddankerNoch keine Bewertungen
- Module 1: Computer Fundamentals 1.1 Introduction To Number System and CodesDokument45 SeitenModule 1: Computer Fundamentals 1.1 Introduction To Number System and CodesBachiNoch keine Bewertungen
- General Mathematics: Simple and Compound InterestDokument19 SeitenGeneral Mathematics: Simple and Compound InterestLynette LicsiNoch keine Bewertungen