Das könnte Ihnen auch gefallen
- SHA572 Course ProjectDokument4 SeitenSHA572 Course ProjectswaggerNoch keine Bewertungen
- Process Effectiveness Assessment Report (PEAR) Form For Weatherford Aerospace.Dokument1 SeiteProcess Effectiveness Assessment Report (PEAR) Form For Weatherford Aerospace.granburyjohnstevens100% (1)
- Effect Sizes in Qualitative Research A ProlegomenonDokument18 SeitenEffect Sizes in Qualitative Research A ProlegomenonGladistoneSLSilvaNoch keine Bewertungen
- Exploratory Factor AnalysisDokument12 SeitenExploratory Factor AnalysisAtiqah IsmailNoch keine Bewertungen
- Research Problem, Hypotheses and VariablesDokument11 SeitenResearch Problem, Hypotheses and VariablesGILTON MADEME88% (33)
- MmpiDokument19 SeitenMmpianeela khanNoch keine Bewertungen
- Effect Size Estimates: Current Use, Calculations, and InterpretationDokument19 SeitenEffect Size Estimates: Current Use, Calculations, and InterpretationsofianiddaNoch keine Bewertungen
- Kelley y Preacher, 2012Dokument16 SeitenKelley y Preacher, 2012DiegoNoch keine Bewertungen
- Single Case Time Series With Bayesian Analysis A Practitioner S GuideDokument13 SeitenSingle Case Time Series With Bayesian Analysis A Practitioner S GuideCai PengpengNoch keine Bewertungen
- TESOL Research GuidelinesDokument17 SeitenTESOL Research GuidelinesGábor SzekeresNoch keine Bewertungen
- Quantitative Research GuidelinesDokument3 SeitenQuantitative Research GuidelinesOana CarciuNoch keine Bewertungen
- What Is Statistical Significance A Measure Of?Dokument3 SeitenWhat Is Statistical Significance A Measure Of?Ritz adrian BalasollaNoch keine Bewertungen
- The Effect of Error Correction On Learners' Ability To Write AccuratelyDokument18 SeitenThe Effect of Error Correction On Learners' Ability To Write AccuratelyWiqoyil IslamaNoch keine Bewertungen
- Carson Becker Henderson 1998Dokument13 SeitenCarson Becker Henderson 1998Nguyen Hoang Minh QuocNoch keine Bewertungen
- 2010 November 01 Agung Santoso With Cover Page v2Dokument18 Seiten2010 November 01 Agung Santoso With Cover Page v2muhammad ismailNoch keine Bewertungen
- MODEL Critical Appraisal Assignment 2Dokument16 SeitenMODEL Critical Appraisal Assignment 2alukoNoch keine Bewertungen
- Educational and Psychological Measurement: Expectancies For Success As A Multidimensional Construct Among Employed AdultsDokument10 SeitenEducational and Psychological Measurement: Expectancies For Success As A Multidimensional Construct Among Employed AdultsileanasinzianaNoch keine Bewertungen
- Sample Size Estimation: Original Author: Jonathan Berkowitz PHD Perc Reviewer: Timothy Lynch MDDokument21 SeitenSample Size Estimation: Original Author: Jonathan Berkowitz PHD Perc Reviewer: Timothy Lynch MDAnonymous CzP3M78KNNoch keine Bewertungen
- Lakens2013-Calculating and Reporting Effect Sizes To Facilitate Cumulative Science PDFDokument12 SeitenLakens2013-Calculating and Reporting Effect Sizes To Facilitate Cumulative Science PDFDanielNoch keine Bewertungen
- Determining Appropriate Sample Size in Survey ResearchDokument8 SeitenDetermining Appropriate Sample Size in Survey ResearchshkadryNoch keine Bewertungen
- Shaw Et Al-2015-Human Resource Management JournalDokument13 SeitenShaw Et Al-2015-Human Resource Management Journalshy_cryNoch keine Bewertungen
- Jackson Et Al. 2009. Reporting Practices in Confirmatory Factor Analysis An Overview and Some RecommendationsDokument18 SeitenJackson Et Al. 2009. Reporting Practices in Confirmatory Factor Analysis An Overview and Some RecommendationslengocthangNoch keine Bewertungen
- Effect Size and AssociationDokument36 SeitenEffect Size and AssociationHanifa Insani KamalNoch keine Bewertungen
- Journal Homepage: - : IntroductionDokument5 SeitenJournal Homepage: - : IntroductionIJAR JOURNALNoch keine Bewertungen
- Chapter 2Dokument18 SeitenChapter 2Kimberly Campasas AutidaNoch keine Bewertungen
- Chapter 3 Thesis Statistical Treatment of DataDokument6 SeitenChapter 3 Thesis Statistical Treatment of Datadnnpkqzw100% (2)
- 2003 Evaluating SngleCase Data Compare 7 Stat Methods Parker PDFDokument23 Seiten2003 Evaluating SngleCase Data Compare 7 Stat Methods Parker PDFAdina CarterNoch keine Bewertungen
- Scale Development ThesisDokument7 SeitenScale Development Thesiskarennelsoncolumbia100% (2)
- 10 1 1 562 7214 PDFDokument18 Seiten10 1 1 562 7214 PDFNoel Cuthbert MushiNoch keine Bewertungen
- Sample Size in Factor Analysis: Why Size Matters: January 2006Dokument7 SeitenSample Size in Factor Analysis: Why Size Matters: January 2006Rodrigo vazquez moralesNoch keine Bewertungen
- Martinez 2011 PDFDokument4 SeitenMartinez 2011 PDFMohammedElGoharyNoch keine Bewertungen
- Vroom TX and Work Criteria Meta AnalyDokument12 SeitenVroom TX and Work Criteria Meta AnalyjfparraacNoch keine Bewertungen
- 3150 2010 November 01 Agung Santoso-with-cover-page-V2Dokument18 Seiten3150 2010 November 01 Agung Santoso-with-cover-page-V2fauzi djNoch keine Bewertungen
- Solomon Et Al-2018-Psychology in The SchoolsDokument14 SeitenSolomon Et Al-2018-Psychology in The SchoolsPaul AsturbiarisNoch keine Bewertungen
- WorkenvironmentscaleDokument13 SeitenWorkenvironmentscaleRoberto Carlos Davila MoranNoch keine Bewertungen
- How Meta-Analysis Increases Statistical Power (Cohn 2003)Dokument11 SeitenHow Meta-Analysis Increases Statistical Power (Cohn 2003)Bextiyar BayramlıNoch keine Bewertungen
- A Rasch Analysis On Collapsing Categories in Item - S Response Scales of Survey Questionnaire Maybe It - S Not One Size Fits All PDFDokument29 SeitenA Rasch Analysis On Collapsing Categories in Item - S Response Scales of Survey Questionnaire Maybe It - S Not One Size Fits All PDFNancy NgNoch keine Bewertungen
- A Beginner's Guide To Factor Analysis: Focusing On Exploratory Factor AnalysisDokument16 SeitenA Beginner's Guide To Factor Analysis: Focusing On Exploratory Factor AnalysisMumTagguRmgNoch keine Bewertungen
- Chapter 22 - Meta-Analysis PDFDokument19 SeitenChapter 22 - Meta-Analysis PDFKaustuva HotaNoch keine Bewertungen
- Research Quality & ContentDokument7 SeitenResearch Quality & Contentjohnalis22Noch keine Bewertungen
- A G M - A: Uideline To ETA NalysisDokument39 SeitenA G M - A: Uideline To ETA NalysisAsmi MohamedNoch keine Bewertungen
- Understanding Meta-Analysis A Review of The Methodological LiteratureDokument16 SeitenUnderstanding Meta-Analysis A Review of The Methodological LiteratureMir'za Adan100% (2)
- Meta Analysis Versus Literature ReviewDokument6 SeitenMeta Analysis Versus Literature Reviewtgkeqsbnd100% (1)
- Getting Started With Meta AnalysisDokument10 SeitenGetting Started With Meta Analysiswatermeloncat123Noch keine Bewertungen
- Imd121 Assignment 1Dokument5 SeitenImd121 Assignment 1NUR IZZAH ISKANDARNoch keine Bewertungen
- The Session Rating Scale Preliminary Psychometric Properties of Workling AllianceDokument10 SeitenThe Session Rating Scale Preliminary Psychometric Properties of Workling Allianceapi-254209971Noch keine Bewertungen
- MacCallum Et Al 1999 Sample Size in FADokument16 SeitenMacCallum Et Al 1999 Sample Size in FAdrdjettelNoch keine Bewertungen
- Propensity Scores: A Practical Introduction Using RDokument21 SeitenPropensity Scores: A Practical Introduction Using RMunirul UlaNoch keine Bewertungen
- Quantitative: How To Detect Effects: Statistical Power and Evidence-Based Practice in Occupational Therapy ResearchDokument8 SeitenQuantitative: How To Detect Effects: Statistical Power and Evidence-Based Practice in Occupational Therapy ResearchkhadijehkhNoch keine Bewertungen
- Educational Research (1992-2002) : An Introduction To Meta-Analysis With Articles From The Journal ofDokument11 SeitenEducational Research (1992-2002) : An Introduction To Meta-Analysis With Articles From The Journal ofBruna DelazeriNoch keine Bewertungen
- Research InformationDokument17 SeitenResearch Informationzh6563833Noch keine Bewertungen
- The Research Prospectus Is A Brief Overview of The Key Components of A Research StudyDokument6 SeitenThe Research Prospectus Is A Brief Overview of The Key Components of A Research StudyLucciana BolañosNoch keine Bewertungen
- Higgins (2016) - Meta-AnalysisDokument23 SeitenHiggins (2016) - Meta-AnalysisNorsakinah AhmadNoch keine Bewertungen
- Ideando La Evaluación ParticipanteDokument23 SeitenIdeando La Evaluación ParticipanteJonathan Tzec MaestroNoch keine Bewertungen
- The Influence of Likert Scale Format On Response Result, Validity, and Reliability of Scale - Using Scales Measuring Economic Shopping OrientationDokument15 SeitenThe Influence of Likert Scale Format On Response Result, Validity, and Reliability of Scale - Using Scales Measuring Economic Shopping OrientationlengocthangNoch keine Bewertungen
- Thesis On Scale DevelopmentDokument6 SeitenThesis On Scale Developmentbsfp46eh100% (1)
- 1999 - Evaluating The Use of EFA in Psychological ResearchDokument28 Seiten1999 - Evaluating The Use of EFA in Psychological ResearchDavid ChávezNoch keine Bewertungen
- A Review of Scale Development Practices in The Study of OrganizationsDokument23 SeitenA Review of Scale Development Practices in The Study of OrganizationsLuana FerreiraNoch keine Bewertungen
- Qualitative Research:: Intelligence for College StudentsVon EverandQualitative Research:: Intelligence for College StudentsBewertung: 4 von 5 Sternen4/5 (1)
- Manual for Job-Communication Satisfaction-Importance (Jcsi) QuestionnaireVon EverandManual for Job-Communication Satisfaction-Importance (Jcsi) QuestionnaireNoch keine Bewertungen
- Statistical Method from the Viewpoint of Quality ControlVon EverandStatistical Method from the Viewpoint of Quality ControlBewertung: 4.5 von 5 Sternen4.5/5 (5)
- Biostatistics Explored Through R Software: An OverviewVon EverandBiostatistics Explored Through R Software: An OverviewBewertung: 3.5 von 5 Sternen3.5/5 (2)
- The Total Antioxidant Content of More Than 3100 Foods, BeverageDokument11 SeitenThe Total Antioxidant Content of More Than 3100 Foods, BeverageZachary LeeNoch keine Bewertungen
- Discourse AnalysisDokument7 SeitenDiscourse AnalysisSimona Coroi0% (2)
- United KingdomDokument7 SeitenUnited KingdomSimona CoroiNoch keine Bewertungen
- Report Information From Proquest: April 18 2013 18:29Dokument4 SeitenReport Information From Proquest: April 18 2013 18:29Simona CoroiNoch keine Bewertungen
- Logic and Purpose Significance TestingDokument12 SeitenLogic and Purpose Significance TestingSimona CoroiNoch keine Bewertungen
- Report Information From Proquest: April 18 2013 17:43Dokument4 SeitenReport Information From Proquest: April 18 2013 17:43Simona CoroiNoch keine Bewertungen
- Job Commitment and Organizational CommitmentDokument16 SeitenJob Commitment and Organizational CommitmentFarayhoon50% (2)
- Job Commitment and Organizational CommitmentDokument16 SeitenJob Commitment and Organizational CommitmentFarayhoon50% (2)
- Job Commitment and Organizational CommitmentDokument16 SeitenJob Commitment and Organizational CommitmentFarayhoon50% (2)
- Psychoanalytic Aesthetics The British SchoolDokument30 SeitenPsychoanalytic Aesthetics The British SchoolSimona CoroiNoch keine Bewertungen
- Goodness of MeasurementDokument6 SeitenGoodness of MeasurementVishal Sharma100% (2)
- (A) Does The Mean Preference For Outdoor Lifestyle Exceed 3?Dokument12 Seiten(A) Does The Mean Preference For Outdoor Lifestyle Exceed 3?Anu DeppNoch keine Bewertungen
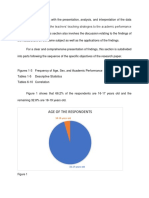
- Age of The Respondents: 18-19 Years OldDokument9 SeitenAge of The Respondents: 18-19 Years OldMicaela BacolodNoch keine Bewertungen
- 10 THDokument1 Seite10 THimmortalleader12Noch keine Bewertungen
- SSC CGL BooksDokument3 SeitenSSC CGL Booksankitconnected1360% (2)
- BAB 23 Mixed-Methods ResearchDokument15 SeitenBAB 23 Mixed-Methods ResearchRosa Artha100% (1)
- National Youth Leadership Network Webinar With Autism NOW July 3, 2012Dokument16 SeitenNational Youth Leadership Network Webinar With Autism NOW July 3, 2012The Autism NOW CenterNoch keine Bewertungen
- BALAJI - Module - 6 7 AOV, CHIDokument8 SeitenBALAJI - Module - 6 7 AOV, CHIAshutosh YadavNoch keine Bewertungen
- Module Report: Overview of Most Recent UseDokument2 SeitenModule Report: Overview of Most Recent Usezach felixNoch keine Bewertungen
- Lab Assignment #2 HamidDokument7 SeitenLab Assignment #2 HamidPohuyistNoch keine Bewertungen
- IMS' Ultimate Guide To B-School Applications 2022Dokument2 SeitenIMS' Ultimate Guide To B-School Applications 2022Om ChaturvediNoch keine Bewertungen
- High School Transcript TemplateDokument2 SeitenHigh School Transcript TemplateRK R0% (1)
- ExcerptDokument3 SeitenExcerptCharmaine HoongNoch keine Bewertungen
- FSS 204 Lecture 7Dokument2 SeitenFSS 204 Lecture 7Abioye DanielNoch keine Bewertungen
- ALLAMA IQBAL OPEN UNIVERSITY, ISLAMABAD (Department of Home & Health Sciences)Dokument4 SeitenALLAMA IQBAL OPEN UNIVERSITY, ISLAMABAD (Department of Home & Health Sciences)Anonymous EIjnKecu0JNoch keine Bewertungen
- JOM FISIP Vol. 4 No. 2 Oktober 2017Dokument12 SeitenJOM FISIP Vol. 4 No. 2 Oktober 2017Teknik Industri UBakrieNoch keine Bewertungen
- Learning Task # 5-7Dokument4 SeitenLearning Task # 5-7kyla marie bardillon tarayaNoch keine Bewertungen
- A1INSE6220 Winter17sol PDFDokument5 SeitenA1INSE6220 Winter17sol PDFpicalaNoch keine Bewertungen
- Unit - 5 - Review - 1Dokument103 SeitenUnit - 5 - Review - 1Aryan JasaniNoch keine Bewertungen
- Kolmogorov StatisticDokument3 SeitenKolmogorov StatisticGabriella Angelica Jemima HasianNoch keine Bewertungen
- Admission Year, 2019-20 Post Graduate StudentsDokument6 SeitenAdmission Year, 2019-20 Post Graduate StudentsShiwali SinghNoch keine Bewertungen
- Presentasi Skema Kompetensi Pengelolaan Produksi-VGDokument204 SeitenPresentasi Skema Kompetensi Pengelolaan Produksi-VGAna MaulanaNoch keine Bewertungen
- Data CollectionDokument29 SeitenData CollectionAnkit KumarNoch keine Bewertungen
- Unit 2 PPTDokument10 SeitenUnit 2 PPTSusantoPaulNoch keine Bewertungen
- E Projective Tech Topic Assignment Aug.21Dokument2 SeitenE Projective Tech Topic Assignment Aug.21syndellNoch keine Bewertungen
- Rural Marketing ResearchDokument25 SeitenRural Marketing ResearchDeven SolankiNoch keine Bewertungen
- Introduction To BiostatisticsDokument19 SeitenIntroduction To BiostatisticsMuhammad ShahidNoch keine Bewertungen