Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The First Voyage Round The World by MageDokument405 SeitenThe First Voyage Round The World by MageGift Marieneth LopezNoch keine Bewertungen
- Sales Forecast Template DownloadDokument9 SeitenSales Forecast Template DownloadAshokNoch keine Bewertungen
- First - Second and Third Class Levers in The Body - Movement Analysis in Sport - Eduqas - Gcse Physical Education Revision - Eduqas - BBC BitesizeDokument2 SeitenFirst - Second and Third Class Levers in The Body - Movement Analysis in Sport - Eduqas - Gcse Physical Education Revision - Eduqas - BBC BitesizeyoyoyoNoch keine Bewertungen
- Report DR JuazerDokument16 SeitenReport DR Juazersharonlly toumasNoch keine Bewertungen
- Survivor's Guilt by Nancy ShermanDokument4 SeitenSurvivor's Guilt by Nancy ShermanGinnie Faustino-GalganaNoch keine Bewertungen
- On Animal Language in The Medieval Classification of Signs PDFDokument24 SeitenOn Animal Language in The Medieval Classification of Signs PDFDearNoodlesNoch keine Bewertungen
- GCP Vol 2 PDF (2022 Edition)Dokument548 SeitenGCP Vol 2 PDF (2022 Edition)Sergio AlvaradoNoch keine Bewertungen
- Soundarya Lahari Yantras Part 6Dokument6 SeitenSoundarya Lahari Yantras Part 6Sushanth Harsha100% (1)
- Generalized Class of Sakaguchi Functions in Conic Region: Saritha. G. P, Fuad. S. Al Sarari, S. LathaDokument5 SeitenGeneralized Class of Sakaguchi Functions in Conic Region: Saritha. G. P, Fuad. S. Al Sarari, S. LathaerpublicationNoch keine Bewertungen
- Jpedal ManualDokument20 SeitenJpedal ManualDamián DávilaNoch keine Bewertungen
- Gujarat Urja Vikas Nigam LTD., Vadodara: Request For ProposalDokument18 SeitenGujarat Urja Vikas Nigam LTD., Vadodara: Request For ProposalABCDNoch keine Bewertungen
- Boarding House Preferences by Middle Up Class Students in SurabayaDokument8 SeitenBoarding House Preferences by Middle Up Class Students in Surabayaeditor ijeratNoch keine Bewertungen
- Marketing Micro and Macro EnvironmentDokument8 SeitenMarketing Micro and Macro EnvironmentSumit Acharya100% (1)
- Classification of Books Using Python and FlaskDokument5 SeitenClassification of Books Using Python and FlaskIJRASETPublicationsNoch keine Bewertungen
- Tyler Nugent ResumeDokument3 SeitenTyler Nugent Resumeapi-315563616Noch keine Bewertungen
- Introduction To HDLDokument28 SeitenIntroduction To HDLBack UpNoch keine Bewertungen
- Aero Ebook - Choosing The Design of Your Aircraft - Chris Heintz PDFDokument6 SeitenAero Ebook - Choosing The Design of Your Aircraft - Chris Heintz PDFGana tp100% (1)
- (Isaac Asimov) How Did We Find Out About AntarcticDokument24 Seiten(Isaac Asimov) How Did We Find Out About AntarcticDrBabu PSNoch keine Bewertungen
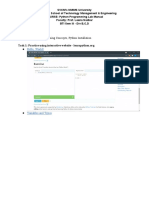
- Week - 2 Lab - 1 - Part I Lab Aim: Basic Programming Concepts, Python InstallationDokument13 SeitenWeek - 2 Lab - 1 - Part I Lab Aim: Basic Programming Concepts, Python InstallationSahil Shah100% (1)
- A Teachers' Journey: Phenomenological Study On The Puritive Behavioral Standards of Students With Broken FamilyDokument11 SeitenA Teachers' Journey: Phenomenological Study On The Puritive Behavioral Standards of Students With Broken FamilyNova Ariston100% (2)
- Benefits and Limitations of BEPDokument2 SeitenBenefits and Limitations of BEPAnishaAppuNoch keine Bewertungen
- Xtype Power Train DTC SummariesDokument53 SeitenXtype Power Train DTC Summariescardude45750Noch keine Bewertungen
- Women Are Better Managers Than MenDokument5 SeitenWomen Are Better Managers Than MenCorazon ValdezNoch keine Bewertungen
- Sap New GL: Document Splitting - Configuration: ChooseDokument3 SeitenSap New GL: Document Splitting - Configuration: ChooseChandra Sekhar PNoch keine Bewertungen
- Science and Technology in Ancient India by NeneDokument274 SeitenScience and Technology in Ancient India by NeneAshok Nene100% (1)
- IOT Questions and Answers - SolutionDokument8 SeitenIOT Questions and Answers - SolutionOmar CheikhrouhouNoch keine Bewertungen
- Existentialism in LiteratureDokument2 SeitenExistentialism in LiteratureGirlhappy Romy100% (1)
- International Freight 01Dokument5 SeitenInternational Freight 01mature.ones1043Noch keine Bewertungen
- Dynalift Sed0804679lDokument1 SeiteDynalift Sed0804679lzaryab khanNoch keine Bewertungen
- Enrico Fermi Pioneer of The at Ted GottfriedDokument156 SeitenEnrico Fermi Pioneer of The at Ted GottfriedRobert Pérez MartinezNoch keine Bewertungen