Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- Fees Structure For Government Sponsored (KUCCPS) Students: University of Eastern Africa, BaratonDokument3 SeitenFees Structure For Government Sponsored (KUCCPS) Students: University of Eastern Africa, BaratonGiddy LerionkaNoch keine Bewertungen
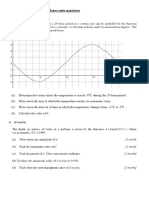
- Sine and Cosine Exam QuestionsDokument8 SeitenSine and Cosine Exam QuestionsGamer Shabs100% (1)
- Real-Time Mining - Project - OverviewDokument47 SeitenReal-Time Mining - Project - OverviewMário de FreitasNoch keine Bewertungen
- Dyno Blasters Handbook v4Dokument32 SeitenDyno Blasters Handbook v4Manuel MolinaNoch keine Bewertungen
- IMC Mining Integrated Pit Dump and HaulageDokument10 SeitenIMC Mining Integrated Pit Dump and HaulageMário de FreitasNoch keine Bewertungen
- V Ships Appln FormDokument6 SeitenV Ships Appln Formkaushikbasu2010Noch keine Bewertungen
- Life of Business Optimisation System (LOBOS) : How Is LOBOS Different?Dokument7 SeitenLife of Business Optimisation System (LOBOS) : How Is LOBOS Different?Mário de FreitasNoch keine Bewertungen
- Dollar Driven Mine PLDokument9 SeitenDollar Driven Mine PLColleen CallahanNoch keine Bewertungen
- How Mining Companies Improve Share PriceDokument17 SeitenHow Mining Companies Improve Share PriceEric APNoch keine Bewertungen
- Typical Project Workflow: A Guide To Mine Plan OptimisationDokument54 SeitenTypical Project Workflow: A Guide To Mine Plan OptimisationMário de FreitasNoch keine Bewertungen
- SOF IEO Sample Paper Class 4Dokument2 SeitenSOF IEO Sample Paper Class 4Rajesh RNoch keine Bewertungen
- 2016 - D - Good Sampling Practice (MNT)Dokument14 Seiten2016 - D - Good Sampling Practice (MNT)Mário de Freitas100% (1)
- Maybe e 2010Dokument15 SeitenMaybe e 2010Mário de FreitasNoch keine Bewertungen
- Ubc 2017 November Pettingell MichaelDokument102 SeitenUbc 2017 November Pettingell MichaelMário de FreitasNoch keine Bewertungen
- Connecting People and Places Through Operational ExcellenceDokument13 SeitenConnecting People and Places Through Operational ExcellenceMário de FreitasNoch keine Bewertungen
- Automation in Construction: Elnaz Siami-Irdemoosa, Saeid R. Dindarloo, Mostafa SharifzadehDokument10 SeitenAutomation in Construction: Elnaz Siami-Irdemoosa, Saeid R. Dindarloo, Mostafa SharifzadehMário de FreitasNoch keine Bewertungen
- 2 - Problemas y Oportunidades PM - A. Ovalle - AMECDokument19 Seiten2 - Problemas y Oportunidades PM - A. Ovalle - AMECMário de FreitasNoch keine Bewertungen
- IJMME4 1 Paper3Dokument25 SeitenIJMME4 1 Paper3Mário de FreitasNoch keine Bewertungen
- 9-2 - Solving The Multi-Resource Constrained Project Scheduling Problem Using Ant Colony OptimizationDokument13 Seiten9-2 - Solving The Multi-Resource Constrained Project Scheduling Problem Using Ant Colony OptimizationMohamed MansourNoch keine Bewertungen
- A Comprehensive Literature Review Reflecting FifteDokument12 SeitenA Comprehensive Literature Review Reflecting FifteMário de FreitasNoch keine Bewertungen
- DESP-C A Discrete-Event Simulation Packa PDFDokument28 SeitenDESP-C A Discrete-Event Simulation Packa PDFMário de FreitasNoch keine Bewertungen
- MatthewGalatiDissertation09 PDFDokument162 SeitenMatthewGalatiDissertation09 PDFMário de FreitasNoch keine Bewertungen
- Critical Manufacturing: Simulators ComparisonDokument30 SeitenCritical Manufacturing: Simulators ComparisonMário de FreitasNoch keine Bewertungen
- Benndorf 2015Dokument24 SeitenBenndorf 2015Mário de FreitasNoch keine Bewertungen
- Pseudoflow New Life For Lerchs-GrossmannDokument8 SeitenPseudoflow New Life For Lerchs-GrossmannEfrain MosqueyraNoch keine Bewertungen
- Designing Blast Patterns Using Empirical FormulasDokument44 SeitenDesigning Blast Patterns Using Empirical FormulasMário de FreitasNoch keine Bewertungen
- Chandran Hochbaum PDFDokument19 SeitenChandran Hochbaum PDFMário de FreitasNoch keine Bewertungen
- Whittle SkinAnalysis PDFDokument4 SeitenWhittle SkinAnalysis PDFMário de FreitasNoch keine Bewertungen
- Beyond Pit OptimisationDokument4 SeitenBeyond Pit OptimisationKarlos Muñoz Alucema100% (2)
- Practical Advice Where It's Crucially Need, at THE FACEDokument6 SeitenPractical Advice Where It's Crucially Need, at THE FACEtekttektNoch keine Bewertungen
- GEOVIA WP PCBC Mine Sequence Optimization110914 A4 LRDokument8 SeitenGEOVIA WP PCBC Mine Sequence Optimization110914 A4 LRanon_747293279Noch keine Bewertungen
- Optimisation of Overburden Blasts at Glencore Ulan Surface Coal ODokument15 SeitenOptimisation of Overburden Blasts at Glencore Ulan Surface Coal OMário de FreitasNoch keine Bewertungen
- Blast PatternsDokument10 SeitenBlast Patternsrajasekar21Noch keine Bewertungen
- DrainHoles - InspectionDokument14 SeitenDrainHoles - Inspectionohm3011Noch keine Bewertungen
- 01 Lab ManualDokument5 Seiten01 Lab ManualM Waqar ZahidNoch keine Bewertungen
- Chapter 5Dokument11 SeitenChapter 5XDXDXDNoch keine Bewertungen
- UMC Florida Annual Conference Filed ComplaintDokument36 SeitenUMC Florida Annual Conference Filed ComplaintCasey Feindt100% (1)
- CV. Anderson Hario Pangestiaji (English Version)Dokument5 SeitenCV. Anderson Hario Pangestiaji (English Version)Anderson PangestiajiNoch keine Bewertungen
- Business Law & TaxationDokument3 SeitenBusiness Law & TaxationD J Ben UzeeNoch keine Bewertungen
- Television: Operating InstructionsDokument40 SeitenTelevision: Operating InstructionsNitin AgrawalNoch keine Bewertungen
- Bron 2017Dokument73 SeitenBron 2017Anggia BungaNoch keine Bewertungen
- Fundamental of Computer MCQ: 1. A. 2. A. 3. A. 4. A. 5. A. 6. ADokument17 SeitenFundamental of Computer MCQ: 1. A. 2. A. 3. A. 4. A. 5. A. 6. AacercNoch keine Bewertungen
- Nozzle F Factor CalculationsDokument5 SeitenNozzle F Factor CalculationsSivateja NallamothuNoch keine Bewertungen
- Explosive Loading of Engineering Structures PDFDokument2 SeitenExplosive Loading of Engineering Structures PDFBillNoch keine Bewertungen
- UEME 1143 - Dynamics: AssignmentDokument4 SeitenUEME 1143 - Dynamics: Assignmentshikai towNoch keine Bewertungen
- A Study On Consumer Buying Behaviour Towards ColgateDokument15 SeitenA Study On Consumer Buying Behaviour Towards Colgatebbhaya427Noch keine Bewertungen
- Canberra As A Planned CityDokument12 SeitenCanberra As A Planned Citybrumbies15100% (1)
- CM - Scope of ServicesDokument3 SeitenCM - Scope of ServicesMelvin MagbanuaNoch keine Bewertungen
- Product 243: Technical Data SheetDokument3 SeitenProduct 243: Technical Data SheetRuiNoch keine Bewertungen
- ms360c Manual PDFDokument130 Seitenms360c Manual PDFEdgardoCadaganNoch keine Bewertungen
- Self-Learning Home Task (SLHT) : Describe The Impact ofDokument9 SeitenSelf-Learning Home Task (SLHT) : Describe The Impact ofJeffrey FloresNoch keine Bewertungen
- Dxgbvi Abdor Rahim OsmanmrDokument1 SeiteDxgbvi Abdor Rahim OsmanmrSakhipur TravelsNoch keine Bewertungen
- As 91435Dokument3 SeitenAs 91435api-271057641Noch keine Bewertungen
- MT8820C LTE Measurement GuideDokument136 SeitenMT8820C LTE Measurement GuideMuthannaNoch keine Bewertungen
- Adjective: the girl is beautifulDokument15 SeitenAdjective: the girl is beautifulIn'am TraboulsiNoch keine Bewertungen
- Applying Graph Theory to Map ColoringDokument25 SeitenApplying Graph Theory to Map ColoringAnonymous BOreSFNoch keine Bewertungen
- Sustainability 15 06202Dokument28 SeitenSustainability 15 06202Somesh AgrawalNoch keine Bewertungen
- Gild PitchDokument19 SeitenGild PitchtejabharathNoch keine Bewertungen
- Test Engleza 8Dokument6 SeitenTest Engleza 8Adriana SanduNoch keine Bewertungen