Das könnte Ihnen auch gefallen
- Mitochondrial DNA Protocol - 2016Dokument233 SeitenMitochondrial DNA Protocol - 2016Sivapong Vsmu100% (1)
- DNA Sequencing Methods Guide Evolution and MedicineDokument17 SeitenDNA Sequencing Methods Guide Evolution and MedicinechacharancharanNoch keine Bewertungen
- The Biology of Cancer: Second EditionDokument47 SeitenThe Biology of Cancer: Second EditionxbNoch keine Bewertungen
- Sequencing TechnologiesDokument25 SeitenSequencing TechnologiesOhhh OkayNoch keine Bewertungen
- Crop Sci 1 Lecture Manual OverviewDokument86 SeitenCrop Sci 1 Lecture Manual OverviewAnalYn Litawan Bucasan100% (1)
- Vanders Human Physiology The Mechanisms of Body Function 15th Edition Widmaier Test BankDokument29 SeitenVanders Human Physiology The Mechanisms of Body Function 15th Edition Widmaier Test BankDavidWardrcobi100% (15)
- CVDokument4 SeitenCVapi-465680652Noch keine Bewertungen
- Protein Blotting Book MILLIPOREDokument56 SeitenProtein Blotting Book MILLIPORELuca LK100% (1)
- Immunology Cornell NotesDokument165 SeitenImmunology Cornell NotesKaylee NesbitNoch keine Bewertungen
- Advances in Zinc Finger Nuclease and Its ApplicationsDokument13 SeitenAdvances in Zinc Finger Nuclease and Its ApplicationsFreddy Rodrigo Navarro GajardoNoch keine Bewertungen
- Gene transfer using retro and adeno virusesDokument17 SeitenGene transfer using retro and adeno virusesVyshali PingleNoch keine Bewertungen
- ACMG Practice ExamDokument156 SeitenACMG Practice ExamSara WoffordNoch keine Bewertungen
- Bioinformatics in The Pharmaceutical IndustryDokument18 SeitenBioinformatics in The Pharmaceutical IndustryboyaccentNoch keine Bewertungen
- M.SC - BioinformaticsDokument43 SeitenM.SC - BioinformaticskrishnanandNoch keine Bewertungen
- Natural Innate and Adaptive Immunity To Cancer: FurtherDokument39 SeitenNatural Innate and Adaptive Immunity To Cancer: FurtherSajjad Hossain ShuvoNoch keine Bewertungen
- What Are The Functions of ProteinsDokument12 SeitenWhat Are The Functions of ProteinsQue TenederoNoch keine Bewertungen
- FASTADokument33 SeitenFASTAAnton MelcherNoch keine Bewertungen
- BPMT Ist Year 080610Dokument22 SeitenBPMT Ist Year 080610sonu8700Noch keine Bewertungen
- Deep Learning for Chest Radiographs: Computer-Aided ClassificationVon EverandDeep Learning for Chest Radiographs: Computer-Aided ClassificationNoch keine Bewertungen
- Immunology in Haematology (Part 2)Dokument55 SeitenImmunology in Haematology (Part 2)kiedd_04100% (4)
- 8 ImmunogeneticsDokument39 Seiten8 ImmunogeneticsSherif EdrisNoch keine Bewertungen
- COT TRF Science G8 - Food ChainDokument8 SeitenCOT TRF Science G8 - Food ChainRAMIR BECOYNoch keine Bewertungen
- Original RT-PCR ReportDokument1 SeiteOriginal RT-PCR ReportVishva IyerNoch keine Bewertungen
- Antigen Capture and PresentationDokument37 SeitenAntigen Capture and PresentationTutde SedanaNoch keine Bewertungen
- MSC Bioinformatics SyllabusDokument42 SeitenMSC Bioinformatics SyllabusSatyendra GuptaNoch keine Bewertungen
- Gazzaniga The Ethical - Brain.the - Science.of - Our.moral - DilemmasDokument229 SeitenGazzaniga The Ethical - Brain.the - Science.of - Our.moral - Dilemmaskid_latigo100% (9)
- Neolithic RevolutionDokument40 SeitenNeolithic RevolutionJoselito DemeterioNoch keine Bewertungen
- Molecular Epidemiology: Principles and PracticesVon EverandMolecular Epidemiology: Principles and PracticesPaul A. SchulteNoch keine Bewertungen
- Patient Registry Data for Research: A Basic Practical GuideVon EverandPatient Registry Data for Research: A Basic Practical GuideNoch keine Bewertungen
- Broad Specificity Profiling of Talens Results in Engineered Nucleases With Improved Dna-Cleavage SpecificityDokument9 SeitenBroad Specificity Profiling of Talens Results in Engineered Nucleases With Improved Dna-Cleavage SpecificityChu Thi Hien ThuNoch keine Bewertungen
- Molecular Carcinogenesis Endometrium PDFDokument7 SeitenMolecular Carcinogenesis Endometrium PDFMelati HasnailNoch keine Bewertungen
- BHS training course in laboratory hematology cytogeneticsDokument35 SeitenBHS training course in laboratory hematology cytogeneticsBai GraceNoch keine Bewertungen
- Structural Biology in Immunology: Structure/Function of Novel Molecules of Immunologic ImportanceVon EverandStructural Biology in Immunology: Structure/Function of Novel Molecules of Immunologic ImportanceChaim PuttermanNoch keine Bewertungen
- Accidental Dosimetry Methods for Dose AssessmentDokument42 SeitenAccidental Dosimetry Methods for Dose AssessmentmosaiyebNoch keine Bewertungen
- Cancer BiomarkersDokument7 SeitenCancer Biomarkersmaheen_aslam6596Noch keine Bewertungen
- Immunogenetics: A Molecular and Clinical Overview: A Molecular Approach to ImmunogeneticsVon EverandImmunogenetics: A Molecular and Clinical Overview: A Molecular Approach to ImmunogeneticsMuneeb U. RehmanNoch keine Bewertungen
- Next Generation SequencingDokument7 SeitenNext Generation SequencingAvani KaushalNoch keine Bewertungen
- Genetics A Conceptual ApproachDokument11 SeitenGenetics A Conceptual ApproachAffan HassanNoch keine Bewertungen
- Gene Sequencing: Darshan Maheshbhai Patel 1 Sem M. Pharm Dept. of Pharmacology Anand Pharmacy College Guide: Anjali PatelDokument47 SeitenGene Sequencing: Darshan Maheshbhai Patel 1 Sem M. Pharm Dept. of Pharmacology Anand Pharmacy College Guide: Anjali PatelPatel DarshanNoch keine Bewertungen
- Exploring Database and Analyzing Protein SequenceDokument70 SeitenExploring Database and Analyzing Protein SequenceRiajNoch keine Bewertungen
- (Jean Langhorne (Editor) ) Immunology and ImmunopatDokument239 Seiten(Jean Langhorne (Editor) ) Immunology and Immunopatclaudia lilianaNoch keine Bewertungen
- Monoclonal Antibodies Against Bacteria: Volume IIIVon EverandMonoclonal Antibodies Against Bacteria: Volume IIIAlberto J. L. MacarioNoch keine Bewertungen
- Internationalinformationpack 2011Dokument20 SeitenInternationalinformationpack 2011manzurqadirNoch keine Bewertungen
- BiologyDokument9 SeitenBiologyRichieNoch keine Bewertungen
- Cloning in BiologyDokument4 SeitenCloning in Biologysarayoo100% (1)
- Introduction To BioinformaticsDokument15 SeitenIntroduction To BioinformaticsJayankNoch keine Bewertungen
- Namita JaggiDokument4 SeitenNamita JaggiIJAMNoch keine Bewertungen
- 02.-Sequence Analysis PDFDokument14 Seiten02.-Sequence Analysis PDFAlexander Martínez PasekNoch keine Bewertungen
- Biotechnology NotesDokument21 SeitenBiotechnology NotesRommel BauzaNoch keine Bewertungen
- The Postgenomic Condition: Ethics, Justice, and Knowledge after the GenomeVon EverandThe Postgenomic Condition: Ethics, Justice, and Knowledge after the GenomeNoch keine Bewertungen
- Books To Follow For CSIR NET ExamDokument3 SeitenBooks To Follow For CSIR NET ExamAbhishek SinghNoch keine Bewertungen
- LN Molecular Biolog Applied Genetics FINALDokument529 SeitenLN Molecular Biolog Applied Genetics FINALarivasudeva100% (1)
- Bio Edit Software ReviewDokument3 SeitenBio Edit Software ReviewNathalia Clavijo50% (2)
- Developing a Healthcare Research Proposal: An Interactive Student GuideVon EverandDeveloping a Healthcare Research Proposal: An Interactive Student GuideNoch keine Bewertungen
- A Theranostic and Precision Medicine Approach for Female-Specific CancersVon EverandA Theranostic and Precision Medicine Approach for Female-Specific CancersRama Rao MallaNoch keine Bewertungen
- Medical Science Educator PDFDokument120 SeitenMedical Science Educator PDFSadeq Ahmed Alsharafi100% (2)
- Immunodeficiency BriefingDokument4 SeitenImmunodeficiency BriefingAldiyanzah Lukman100% (1)
- Mutiplexpcr Primer DesignDokument11 SeitenMutiplexpcr Primer DesignAnn Irene DomnicNoch keine Bewertungen
- Forensic Medical Findings in Fatal and Non-Fatal Intimate Partner Strangulation Assaults - Hawley - 2012 PDFDokument20 SeitenForensic Medical Findings in Fatal and Non-Fatal Intimate Partner Strangulation Assaults - Hawley - 2012 PDFBoţu AlexandruNoch keine Bewertungen
- Hla B 27 SopDokument12 SeitenHla B 27 SopRajeev PareekNoch keine Bewertungen
- Developing Costimulatory Molecules for Immunotherapy of DiseasesVon EverandDeveloping Costimulatory Molecules for Immunotherapy of DiseasesNoch keine Bewertungen
- Research 1 FinalsDokument81 SeitenResearch 1 FinalsKaiken DukeNoch keine Bewertungen
- 4-Year Cell Biology and Genetics Degree ProgrammeDokument5 Seiten4-Year Cell Biology and Genetics Degree ProgrammeEmmNoch keine Bewertungen
- Geographic Distribution Pattern of Congenital - 2012Dokument10 SeitenGeographic Distribution Pattern of Congenital - 2012Fhadla NisaaNoch keine Bewertungen
- A Mathematical Model For HAVDokument10 SeitenA Mathematical Model For HAVFhadla NisaaNoch keine Bewertungen
- Glasgow Outcome ScaleDokument1 SeiteGlasgow Outcome ScaleAbdur RasyidNoch keine Bewertungen
- Theories of PerceptionDokument31 SeitenTheories of PerceptionLumbini Neha ParnasNoch keine Bewertungen
- Bahan Studi Asosiasi Genetik 3Dokument16 SeitenBahan Studi Asosiasi Genetik 3Fhadla NisaaNoch keine Bewertungen
- Enviromental Chemical Exposure and Human EpigeneticsDokument27 SeitenEnviromental Chemical Exposure and Human EpigeneticsFhadla NisaaNoch keine Bewertungen
- E-Portfolio Injection Study GuideDokument7 SeitenE-Portfolio Injection Study Guideapi-366034042Noch keine Bewertungen
- Pecutan Akhir Science 2021Dokument29 SeitenPecutan Akhir Science 2021Azween SabtuNoch keine Bewertungen
- 4.1 - Cell Cycle Part 1Dokument5 Seiten4.1 - Cell Cycle Part 1Deomar Joseph ParadoNoch keine Bewertungen
- The "Five Families" College Essay ExampleDokument1 SeiteThe "Five Families" College Essay ExampleKishor RaiNoch keine Bewertungen
- Since 1938 We Are Upholding The Spirit That Founded Our University and Encourage Each Other To ExploreDokument71 SeitenSince 1938 We Are Upholding The Spirit That Founded Our University and Encourage Each Other To ExploreShohel RanaNoch keine Bewertungen
- Mengenali Konflik Dalam Negosiasi Oleh: Zumaeroh: PendahuluanDokument47 SeitenMengenali Konflik Dalam Negosiasi Oleh: Zumaeroh: PendahuluanrahmatNoch keine Bewertungen
- Ewh Ix PDFDokument80 SeitenEwh Ix PDFOR Premium FreeNoch keine Bewertungen
- Effects of Sleep Deprivation among Students in Saint Francis of Assisi CollegeDokument50 SeitenEffects of Sleep Deprivation among Students in Saint Francis of Assisi College• Cielo •Noch keine Bewertungen
- JCM 08 00217 v3Dokument23 SeitenJCM 08 00217 v3Sumit BediNoch keine Bewertungen
- Human Contact May Reduce Stress in Shelter DogsDokument5 SeitenHuman Contact May Reduce Stress in Shelter DogsFlorina AnichitoaeNoch keine Bewertungen
- Self Concept Inventory Hand OutDokument2 SeitenSelf Concept Inventory Hand OutHarold LowryNoch keine Bewertungen
- Determination of Lethal Dose Ld50of Venom of Four Different Poisonous Snakes Found in PakistanDokument4 SeitenDetermination of Lethal Dose Ld50of Venom of Four Different Poisonous Snakes Found in PakistanSutirtho MukherjiNoch keine Bewertungen
- Protected Area Expansion Strategy For CapeNature 2010 29 SeptemberDokument70 SeitenProtected Area Expansion Strategy For CapeNature 2010 29 SeptembertableviewNoch keine Bewertungen
- Flowering PlantsDokument43 SeitenFlowering Plantskingbanakon100% (1)
- Ficha Técnica SpotcheckDokument5 SeitenFicha Técnica SpotcheckJuan PazNoch keine Bewertungen
- 02 Anatomy and Histology PLE 2019 RatioDokument69 Seiten02 Anatomy and Histology PLE 2019 RatioPatricia VillegasNoch keine Bewertungen
- 01 MDCAT SOS Regular Session (5th June-2023) With LR..Dokument5 Seiten01 MDCAT SOS Regular Session (5th June-2023) With LR..bakhtawarsrkNoch keine Bewertungen
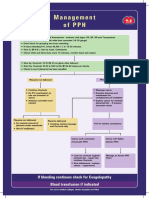
- Management of PPHDokument1 SeiteManagement of PPH098 U.KARTHIK SARAVANA KANTHNoch keine Bewertungen
- Cu EnzymesDokument8 SeitenCu EnzymesVINEESHA VKNoch keine Bewertungen
- Candida Tropicalis - ACMGDokument12 SeitenCandida Tropicalis - ACMGSergio Iván López LallanaNoch keine Bewertungen
- CH8009 Fermentation Engineering AUQPDokument2 SeitenCH8009 Fermentation Engineering AUQPSaravanan SundaramNoch keine Bewertungen
- 2nd Periodic Test (Science)Dokument1 Seite2nd Periodic Test (Science)mosarbas0950% (2)
- Characterization of Polydimethylsiloxane (PDMS) PropertiesDokument13 SeitenCharacterization of Polydimethylsiloxane (PDMS) PropertiesEsteban ArayaNoch keine Bewertungen
- Comparison of the Fully Automated Urinalysis Analyzers UX-2000 and Cobas 6500Dokument10 SeitenComparison of the Fully Automated Urinalysis Analyzers UX-2000 and Cobas 6500Sethulakshmi PharmacistNoch keine Bewertungen