Das könnte Ihnen auch gefallen
- Social Discount Rate in CBA PDFDokument192 SeitenSocial Discount Rate in CBA PDFMarijan JakovljevicNoch keine Bewertungen
- Assessing Costs and Benefits of Urban Transport InnovationsDokument44 SeitenAssessing Costs and Benefits of Urban Transport InnovationsMarijan JakovljevicNoch keine Bewertungen
- Handbook - Costos Externos PDFDokument336 SeitenHandbook - Costos Externos PDFJULIETH PAOLA ZÁRATE CARRILLONoch keine Bewertungen
- Durbin Watson TablesDokument11 SeitenDurbin Watson TablesgotiiiNoch keine Bewertungen
- Autocad ShortcutsDokument13 SeitenAutocad ShortcutsKriscel CaraanNoch keine Bewertungen
- Crime in Road Freight TransportDokument142 SeitenCrime in Road Freight TransportMarijan JakovljevicNoch keine Bewertungen
- Variable TransformationsDokument15 SeitenVariable TransformationsJuan Alonso Leon-AbarcaNoch keine Bewertungen
- Autocad ShortcutsDokument13 SeitenAutocad ShortcutsKriscel CaraanNoch keine Bewertungen
- Handbook of TRANSPORT MODELLING Button and HensherDokument346 SeitenHandbook of TRANSPORT MODELLING Button and HensherMarijan Jakovljevic100% (6)
- Impact of Side Friction On Speed-Flow RelationshipsDokument27 SeitenImpact of Side Friction On Speed-Flow RelationshipsMarijan Jakovljevic75% (4)
- 127FT L 015 FrictionDokument4 Seiten127FT L 015 FrictionMarijan JakovljevicNoch keine Bewertungen
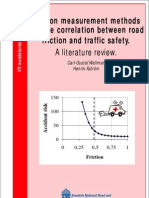
- Friktionsmatningar Och Sambandet Mellan Vagfriktion Och TrafiksakerhetDokument47 SeitenFriktionsmatningar Och Sambandet Mellan Vagfriktion Och TrafiksakerhetMarijan JakovljevicNoch keine Bewertungen
- HAL ArticleRaous 29sept06Dokument10 SeitenHAL ArticleRaous 29sept06Marijan JakovljevicNoch keine Bewertungen
- NHCRP Report 600A Human Factors Guidelines For Road Systems - 2008Dokument146 SeitenNHCRP Report 600A Human Factors Guidelines For Road Systems - 2008Welly Pradipta bin MaryulisNoch keine Bewertungen
- Variable Speed LimitDokument15 SeitenVariable Speed LimitMarijan JakovljevicNoch keine Bewertungen
- Variable Speed Limit To Improve SafetyDokument8 SeitenVariable Speed Limit To Improve SafetyMarijan JakovljevicNoch keine Bewertungen
- Molna Masa Goriva:: Rješenje Seminarskog ZadatkaDokument4 SeitenMolna Masa Goriva:: Rješenje Seminarskog ZadatkaMarijan JakovljevicNoch keine Bewertungen
- Traffic Flow FundamentalsDokument239 SeitenTraffic Flow FundamentalsMarijan Jakovljevic100% (1)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5784)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (890)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (72)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- CA Foundation Syllabus and Revision PlanDokument10 SeitenCA Foundation Syllabus and Revision PlanStudy HelpNoch keine Bewertungen
- Calculate Discount and Percentage DiscountDokument12 SeitenCalculate Discount and Percentage DiscountMaria KimNoch keine Bewertungen
- c3 DDokument6 Seitenc3 DMiracleNoch keine Bewertungen
- Chapter 2 - Part 1 - Measures of Central Tendency - Practice ProblemsDokument8 SeitenChapter 2 - Part 1 - Measures of Central Tendency - Practice ProblemsTejas Joshi0% (3)
- 105-s29 Control of Flexural Cracking in Reinforced ConcreteDokument7 Seiten105-s29 Control of Flexural Cracking in Reinforced ConcreteThomas Crowe100% (1)
- Surface Area of A Rectangular PrismDokument10 SeitenSurface Area of A Rectangular PrismEstelita P. AgustinNoch keine Bewertungen
- Exp 11 Forward InterpolationDokument3 SeitenExp 11 Forward InterpolationHasibur100% (1)
- SQL Queries - Best PracticesDokument3 SeitenSQL Queries - Best PracticesvishnuselvaNoch keine Bewertungen
- Elastic-Plastic Incremental Analysis Using ETABSDokument12 SeitenElastic-Plastic Incremental Analysis Using ETABSAwrd A AwrdNoch keine Bewertungen
- Sample Paper 5: Class - XII Exam 2021-22 (TERM - II) Applied MathematicsDokument4 SeitenSample Paper 5: Class - XII Exam 2021-22 (TERM - II) Applied MathematicsLakshmanan MeyyappanNoch keine Bewertungen
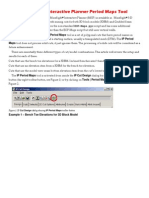
- MSIP Period Maps Tool 200901Dokument8 SeitenMSIP Period Maps Tool 200901Kenny CasillaNoch keine Bewertungen
- Architectual StructuresDokument300 SeitenArchitectual StructuresAleksxander GovaNoch keine Bewertungen
- The Rhind PapyrusDokument5 SeitenThe Rhind PapyrusVictor QuezadaNoch keine Bewertungen
- Basic Concepts: of Medical InstrumentationDokument37 SeitenBasic Concepts: of Medical InstrumentationIrahlevrikAkhelNoch keine Bewertungen
- Cost Accounting and Control AnswersDokument9 SeitenCost Accounting and Control AnswersshaylieeeNoch keine Bewertungen
- Mind Control As A Guide For The MindDokument12 SeitenMind Control As A Guide For The MindPrince ShahfanNoch keine Bewertungen
- IITJEE 2014-Physics-School Handout-Magnetism and MatterDokument10 SeitenIITJEE 2014-Physics-School Handout-Magnetism and MatterDikshant GuptaNoch keine Bewertungen
- Seismic Analysis of Multi-Story RC BuildingsDokument15 SeitenSeismic Analysis of Multi-Story RC BuildingsPrakash Channappagoudar100% (1)
- Latitude and Longitude BasicDokument14 SeitenLatitude and Longitude Basicapi-235000986100% (3)
- Mechanics of EquilibriumDokument6 SeitenMechanics of EquilibriumSherwin LimboNoch keine Bewertungen
- Lodes Robot Simulator in MATLABDokument7 SeitenLodes Robot Simulator in MATLABPhạm Ngọc HòaNoch keine Bewertungen
- Deep Learning in Trading PDFDokument10 SeitenDeep Learning in Trading PDFRicardo Velasco GuachallaNoch keine Bewertungen
- Analysis of Eddy Current Brakes using Maxwell 3D Transient SimulationDokument36 SeitenAnalysis of Eddy Current Brakes using Maxwell 3D Transient SimulationPramoth Dhayalan100% (1)
- CATIA Full Book 2 Print - 2Dokument147 SeitenCATIA Full Book 2 Print - 2Sum Sumne SumanthNoch keine Bewertungen
- C:G M S C: 6401 S:S 2023 Level:Ade (2) Assignment No 1Dokument10 SeitenC:G M S C: 6401 S:S 2023 Level:Ade (2) Assignment No 1israrNoch keine Bewertungen
- Math 6 - Contextualized Lesson PlanDokument4 SeitenMath 6 - Contextualized Lesson Planlk venturaNoch keine Bewertungen
- Problem 1 SolutionDokument24 SeitenProblem 1 Solutionnitte5768Noch keine Bewertungen
- Week 5 of Tests and TestingDokument7 SeitenWeek 5 of Tests and Testingvannamargaux14Noch keine Bewertungen
- Aerospace Engineering Sample Report PDFDokument4 SeitenAerospace Engineering Sample Report PDFDuncan LeeNoch keine Bewertungen
- Fundamental Aspects of Fire BehaviorDokument10 SeitenFundamental Aspects of Fire BehaviorBasil OguakaNoch keine Bewertungen