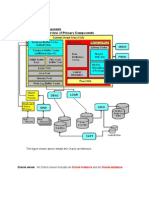
Das könnte Ihnen auch gefallen
- DB2 HadrDokument63 SeitenDB2 HadrsagmakNoch keine Bewertungen
- DB2 9 System Administration for z/OS: Certification Study Guide: Exam 737Von EverandDB2 9 System Administration for z/OS: Certification Study Guide: Exam 737Bewertung: 3 von 5 Sternen3/5 (2)
- Architecture of DB2 LUWDokument11 SeitenArchitecture of DB2 LUWShankar Reddy100% (1)
- DB2 BLU Shadow Tables With SAP V1 PDFDokument28 SeitenDB2 BLU Shadow Tables With SAP V1 PDFJi-yong JungNoch keine Bewertungen
- DM Perf Tuning2 PDFDokument19 SeitenDM Perf Tuning2 PDFomnibuyerNoch keine Bewertungen
- PDB Restoration DocumentDokument35 SeitenPDB Restoration DocumentVinod KumarNoch keine Bewertungen
- HADR Db2haicu PDFDokument58 SeitenHADR Db2haicu PDFAsif PanjwaniNoch keine Bewertungen
- DB 2 AuditDokument16 SeitenDB 2 Auditprakash_6849Noch keine Bewertungen
- Dba 101Dokument35 SeitenDba 101akash raj81100% (1)
- DB2 MigrationDokument17 SeitenDB2 MigrationWarsi AAkelNoch keine Bewertungen
- Oracle DBA CommandsDokument41 SeitenOracle DBA CommandsBuddi100% (1)
- Performance TuningDokument5 SeitenPerformance Tuningapi-3716519100% (1)
- Data Bases in SQL ServerDokument2 SeitenData Bases in SQL ServermekavinashNoch keine Bewertungen
- DB2 Architecture OverviewDokument15 SeitenDB2 Architecture OverviewBinay MishraNoch keine Bewertungen
- Grid Infrastructure Installation Guide PDFDokument198 SeitenGrid Infrastructure Installation Guide PDFjmsalgadosNoch keine Bewertungen
- Reorg, DMS, HWM, Log Space ConsumptionDokument56 SeitenReorg, DMS, HWM, Log Space ConsumptionSreejit MenonNoch keine Bewertungen
- 70 462Dokument3 Seiten70 462Aleksandar CosicNoch keine Bewertungen
- Oracle DBA TasksDokument2 SeitenOracle DBA TasksPratik GandhiNoch keine Bewertungen
- Oracle ArchitectureDokument102 SeitenOracle ArchitecturemanavalanmichaleNoch keine Bewertungen
- DB2 Instance CreationDokument4 SeitenDB2 Instance CreationLeela PrasadNoch keine Bewertungen
- Dbms NewDokument156 SeitenDbms NewrajaNoch keine Bewertungen
- Db2 Luw Useful CommandsDokument2 SeitenDb2 Luw Useful Commandsdb2dbasaurabhNoch keine Bewertungen
- OEM12c PatchingDokument16 SeitenOEM12c PatchingPankaj GuptaNoch keine Bewertungen
- SQL Server Memory: Understanding Usage, Monitoring and OptimizationDokument13 SeitenSQL Server Memory: Understanding Usage, Monitoring and OptimizationmaheshNoch keine Bewertungen
- How To Influence The DB2 Query Optimizer Using Optimization ProfilesDokument52 SeitenHow To Influence The DB2 Query Optimizer Using Optimization ProfilesJames L. ChamberlainNoch keine Bewertungen
- RESTORE DATABASE - IBM DB2 9.7 For Linux, UNIX, and WindowsDokument13 SeitenRESTORE DATABASE - IBM DB2 9.7 For Linux, UNIX, and Windowsolippo19Noch keine Bewertungen
- Table Space & Buffer PoolsDokument16 SeitenTable Space & Buffer Poolsnaua2010Noch keine Bewertungen
- Automating Oracle Database Startup and Shutdown On Linux SOPDokument3 SeitenAutomating Oracle Database Startup and Shutdown On Linux SOPFrancesHsiehNoch keine Bewertungen
- Data Guard BrokerDokument393 SeitenData Guard BrokerAB100% (1)
- Quick Oracle 9i Performance Tuning Tips & ScriptsDokument7 SeitenQuick Oracle 9i Performance Tuning Tips & ScriptsEder CoutoNoch keine Bewertungen
- Quick Guide To MySQL WorkbenchDokument4 SeitenQuick Guide To MySQL WorkbenchTubagus BondanNoch keine Bewertungen
- GG Flat File v3Dokument37 SeitenGG Flat File v3Hasan BilalNoch keine Bewertungen
- Oracle Startup and Shutdown PhasesDokument9 SeitenOracle Startup and Shutdown PhasesPILLINAGARAJUNoch keine Bewertungen
- Oracle 11g Active Data Guard Setup Using RMANDokument12 SeitenOracle 11g Active Data Guard Setup Using RMANThota Mahesh DbaNoch keine Bewertungen
- Dublin Tech - DB2 Cheat SheetDokument4 SeitenDublin Tech - DB2 Cheat SheetTanveer AhmedNoch keine Bewertungen
- How To Make Resume As Fresher Oracle DBA Myths-Mysteries-MemorableDokument7 SeitenHow To Make Resume As Fresher Oracle DBA Myths-Mysteries-Memorablesriraam6Noch keine Bewertungen
- Performance Tuning in Oracle 10g: Introduction to MetricsDokument135 SeitenPerformance Tuning in Oracle 10g: Introduction to Metricsbsrksg123Noch keine Bewertungen
- Oracle FullDokument105 SeitenOracle Fullapi-3759101100% (1)
- HADRDokument46 SeitenHADRRajesh VanapalliNoch keine Bewertungen
- DB2 Classroom 1.0 - WelcomeDokument30 SeitenDB2 Classroom 1.0 - WelcomepduraesNoch keine Bewertungen
- Lsscsi Output and Multipath Configuration on Two ServersDokument15 SeitenLsscsi Output and Multipath Configuration on Two ServersBiplab ParidaNoch keine Bewertungen
- Ingres Install 9Dokument155 SeitenIngres Install 9ramuyadav1Noch keine Bewertungen
- SPMDokument17 SeitenSPMmanojk.mauryaNoch keine Bewertungen
- DB2 9.8 LUW Full Online Backups ExperimentsDokument26 SeitenDB2 9.8 LUW Full Online Backups Experimentsraul_oliveira_83Noch keine Bewertungen
- WLSTDokument55 SeitenWLSTashish10mca9394Noch keine Bewertungen
- DB2 Administration Hands-On-Labs 20130415Dokument92 SeitenDB2 Administration Hands-On-Labs 20130415jimmy_sam001Noch keine Bewertungen
- Install Oracle 11g R2 with ASM on Oracle Linux 7Dokument22 SeitenInstall Oracle 11g R2 with ASM on Oracle Linux 7kamakom78Noch keine Bewertungen
- Oracle 11g RAC and Grid Infrastructure Administration Accelerated Release 2 - D77642GC30 - 1080544 - USDokument7 SeitenOracle 11g RAC and Grid Infrastructure Administration Accelerated Release 2 - D77642GC30 - 1080544 - USJinendraabhiNoch keine Bewertungen
- CenturyLink Technologies Oracle Database upgrade to 12CDokument18 SeitenCenturyLink Technologies Oracle Database upgrade to 12CGoruganti Vinay VinnuNoch keine Bewertungen
- Administering Oracle Database Classic Cloud Service PDFDokument425 SeitenAdministering Oracle Database Classic Cloud Service PDFGanesh KaralkarNoch keine Bewertungen
- BASH Programming GuideDokument20 SeitenBASH Programming GuideDenis MkwatiNoch keine Bewertungen
- Oracle Architecture Diagram and NotesDokument9 SeitenOracle Architecture Diagram and Notesanil_shenoyNoch keine Bewertungen
- Dataguard - MyunderstandingDokument3 SeitenDataguard - Myunderstandingabdulgani11Noch keine Bewertungen
- Deutsche Bank MISDokument7 SeitenDeutsche Bank MISAshish KalraNoch keine Bewertungen
- Everyday Oracle DBA - Chapter 1 - Making It WorkDokument46 SeitenEveryday Oracle DBA - Chapter 1 - Making It Workhoangtran1307Noch keine Bewertungen
- SOP DC-DR Database DRILLDokument4 SeitenSOP DC-DR Database DRILLocp001Noch keine Bewertungen
- Tactics For Monitoring Tuning AIX 5L 6.1 Apr28-09 V1.0Dokument34 SeitenTactics For Monitoring Tuning AIX 5L 6.1 Apr28-09 V1.0danilaixNoch keine Bewertungen
- IBM IoMemory VSL 3.2.14 User Guide For Linux 2016-11-14Dokument78 SeitenIBM IoMemory VSL 3.2.14 User Guide For Linux 2016-11-14danilaixNoch keine Bewertungen
- POWER5Dokument72 SeitenPOWER5danilaixNoch keine Bewertungen
- Cluster DefineDokument5 SeitenCluster DefinedanilaixNoch keine Bewertungen
- LasCon Storage - TSM Database and LogDokument12 SeitenLasCon Storage - TSM Database and LogdanilaixNoch keine Bewertungen
- Aix 7 - Release NotesDokument26 SeitenAix 7 - Release NotesdanilaixNoch keine Bewertungen
- TSM Dedup Best Practices - V2.0Dokument50 SeitenTSM Dedup Best Practices - V2.0danilaixNoch keine Bewertungen
- Linux AIX ComparisonDokument5 SeitenLinux AIX ComparisondanilaixNoch keine Bewertungen
- Section 2: The Technology: "Any Sufficiently Advanced Technology Will Have The Appearance of Magic." Arthur C. ClarkeDokument90 SeitenSection 2: The Technology: "Any Sufficiently Advanced Technology Will Have The Appearance of Magic." Arthur C. ClarkedanilaixNoch keine Bewertungen
- Systems Power Software Availability CLMGR Tech GuideDokument16 SeitenSystems Power Software Availability CLMGR Tech GuidedanilaixNoch keine Bewertungen
- Linux Kernel InternalsDokument56 SeitenLinux Kernel InternalsdanilaixNoch keine Bewertungen
- Vio ServerDokument10 SeitenVio ServerdanilaixNoch keine Bewertungen
- Test Flash Disk Performance with ndisk64Dokument3 SeitenTest Flash Disk Performance with ndisk64danilaixNoch keine Bewertungen
- Why - File-Size - of - Sar - V - Is Different With - Lsof - WC - L - (AIX World)Dokument5 SeitenWhy - File-Size - of - Sar - V - Is Different With - Lsof - WC - L - (AIX World)danilaixNoch keine Bewertungen
- Active FTP Vs Passive FTPDokument4 SeitenActive FTP Vs Passive FTPdanilaixNoch keine Bewertungen
- Advanced Techniques For Using The UNIX Find CommandDokument5 SeitenAdvanced Techniques For Using The UNIX Find CommanddanilaixNoch keine Bewertungen
- Linux System Administration Tasks and ServicesDokument15 SeitenLinux System Administration Tasks and ServicesdanilaixNoch keine Bewertungen
- Documents Cisco Multicast-RouterDokument2 SeitenDocuments Cisco Multicast-RouterdanilaixNoch keine Bewertungen
- 01AL740 121 042.readmeDokument13 Seiten01AL740 121 042.readmedanilaixNoch keine Bewertungen
- 5301 Base RelnotesDokument54 Seiten5301 Base RelnotesdanilaixNoch keine Bewertungen
- DSMC CommandsDokument3 SeitenDSMC CommandsdanilaixNoch keine Bewertungen
- AIX PowerHA (HACMP) CommandsDokument3 SeitenAIX PowerHA (HACMP) CommandsdanilaixNoch keine Bewertungen
- Power6 Virtual IoDokument60 SeitenPower6 Virtual IodanilaixNoch keine Bewertungen
- VIOS Service Life July 2013Dokument1 SeiteVIOS Service Life July 2013danilaixNoch keine Bewertungen
- Avamar-4.1-Technical-Addendum. Avamar Commandspdf PDFDokument537 SeitenAvamar-4.1-Technical-Addendum. Avamar Commandspdf PDFdanilaix50% (2)
- Brocade ZoningDokument70 SeitenBrocade ZoningBhanu Chandra Thotapally100% (1)
- Power HaDokument726 SeitenPower HadanilaixNoch keine Bewertungen
- PowerVM Migration From Physical To Virtual StorageDokument194 SeitenPowerVM Migration From Physical To Virtual StoragedanilaixNoch keine Bewertungen
- Networking 1 TutorialDokument12 SeitenNetworking 1 TutorialSocaciu VioricaNoch keine Bewertungen
- SIEMENS KNX ETS5-For-Beginners - en PDFDokument4 SeitenSIEMENS KNX ETS5-For-Beginners - en PDFbbas6825Noch keine Bewertungen
- An Event Driven Arduino 1.6.xDokument39 SeitenAn Event Driven Arduino 1.6.xFlavio Andrade100% (1)
- Net Analysis ManualDokument109 SeitenNet Analysis ManualbdrgboiseNoch keine Bewertungen
- Vendor Bal ConfermationDokument8 SeitenVendor Bal ConfermationSri KanthNoch keine Bewertungen
- SP3D ModelFormats Global enDokument7 SeitenSP3D ModelFormats Global enJesús Alberto Díaz CostaNoch keine Bewertungen
- Proposal On Online Examination For BE EntranceDokument21 SeitenProposal On Online Examination For BE Entrancesubhash22110360% (5)
- (WWW - Entrance-Exam - Net) - DOEACC B Level-Network Management & Information Security Sample Paper 1Dokument2 Seiten(WWW - Entrance-Exam - Net) - DOEACC B Level-Network Management & Information Security Sample Paper 1DEBLEENA VIJAYNoch keine Bewertungen
- CN ProgramsDokument14 SeitenCN ProgramsPrakash ReddyNoch keine Bewertungen
- Adv. Dbms MCQDokument47 SeitenAdv. Dbms MCQnirali75% (12)
- AlliedWare PlusTM HOWTODokument42 SeitenAlliedWare PlusTM HOWTOliveNoch keine Bewertungen
- Do 009467 PS 4Dokument482 SeitenDo 009467 PS 4gayamartNoch keine Bewertungen
- TCP - Part I: Relates To Lab 5. First Module On TCP Which Covers Packet Format, DataDokument31 SeitenTCP - Part I: Relates To Lab 5. First Module On TCP Which Covers Packet Format, DataSalman JawedNoch keine Bewertungen
- Cookie CadgerDokument53 SeitenCookie Cadgerchuff6675Noch keine Bewertungen
- Acronis Backup Initial Seeding GuideDokument12 SeitenAcronis Backup Initial Seeding GuideHector SanchezNoch keine Bewertungen
- SampleFINAL KEY 205 TaylorDokument9 SeitenSampleFINAL KEY 205 Tayloraskar_cbaNoch keine Bewertungen
- Change Logitech Mouse Lamp ColourfulDokument12 SeitenChange Logitech Mouse Lamp ColourfulQruisedNoch keine Bewertungen
- Copy Ios Flash To TFTP ServerDokument7 SeitenCopy Ios Flash To TFTP Serverateeqshahid035Noch keine Bewertungen
- Csit127 SeminarDokument12 SeitenCsit127 SeminarZahra HossainiNoch keine Bewertungen
- Xilinx XC 3000Dokument21 SeitenXilinx XC 3000shabbir470100% (1)
- Jmeter Elements PDFDokument108 SeitenJmeter Elements PDFMayank Mishra100% (1)
- Advanced Automotive Antennas: Test Validation ExamDokument12 SeitenAdvanced Automotive Antennas: Test Validation Examcodrin eneaNoch keine Bewertungen
- Ade M2 PDFDokument37 SeitenAde M2 PDFSushmaNoch keine Bewertungen
- Pymodbus PDFDokument267 SeitenPymodbus PDFjijil1Noch keine Bewertungen
- Swift ShaderDokument5 SeitenSwift ShaderLane FosterNoch keine Bewertungen
- APCS BookDokument543 SeitenAPCS BookEdmundo Coup0% (1)
- SAP Business One For HANA On The AWS Cloud PDFDokument35 SeitenSAP Business One For HANA On The AWS Cloud PDFMiguelNoch keine Bewertungen
- Unit 1Dokument22 SeitenUnit 1Cookie SarwarNoch keine Bewertungen
- Omap l138Dokument287 SeitenOmap l138Pritesh MandaviaNoch keine Bewertungen
- Divide and Conquer Algorithm Design MethodDokument3 SeitenDivide and Conquer Algorithm Design MethodEbmesem100% (1)