Das könnte Ihnen auch gefallen
- Technical Appendix of The Book Capital in The Twenty-First Century Appendix To Chapter 10. Inequality of Capital Ownership Addendum: Response To FTDokument10 SeitenTechnical Appendix of The Book Capital in The Twenty-First Century Appendix To Chapter 10. Inequality of Capital Ownership Addendum: Response To FTapi-244773802Noch keine Bewertungen
- On The Mechanics of Economic Development : University of Chicago, Chicago, 1L 60637, USADokument40 SeitenOn The Mechanics of Economic Development : University of Chicago, Chicago, 1L 60637, USAfabricio nazarettoNoch keine Bewertungen
- Review Article Piketty RevDokument18 SeitenReview Article Piketty RevCreomar BaptistaNoch keine Bewertungen
- Lucasmechanicseconomicgrowth: Related PapersDokument41 SeitenLucasmechanicseconomicgrowth: Related PapersjojokawayNoch keine Bewertungen
- Pike Tty NyuDokument18 SeitenPike Tty NyuTNoch keine Bewertungen
- Inequality in The Long RunDokument14 SeitenInequality in The Long RunKartik AvanaNoch keine Bewertungen
- On The Mechanics of Economic Development - Robert LucasDokument40 SeitenOn The Mechanics of Economic Development - Robert LucasMalandragem dá um tempoNoch keine Bewertungen
- Being Charged by An Elephant: A Story of Globalization and InequalityDokument5 SeitenBeing Charged by An Elephant: A Story of Globalization and InequalityDan August GalliguezNoch keine Bewertungen
- Scienza e Pace - No2 - 2017 - Della - Posta - ItDokument32 SeitenScienza e Pace - No2 - 2017 - Della - Posta - ItSamia RazzaqNoch keine Bewertungen
- US Wealth PDFDokument89 SeitenUS Wealth PDFTangthietgiapNoch keine Bewertungen
- Wealth and Income Inequality in The LongDokument34 SeitenWealth and Income Inequality in The LongThiago KrauseNoch keine Bewertungen
- Work 654Dokument47 SeitenWork 654NebilahNoch keine Bewertungen
- Political Economy of Budget DeficitsDokument57 SeitenPolitical Economy of Budget DeficitsStéphane Villagómez CharbonneauNoch keine Bewertungen
- My Story Begins With Franco Modigliani. in 1985 He WasDokument6 SeitenMy Story Begins With Franco Modigliani. in 1985 He Wasapi-26172897Noch keine Bewertungen
- Daron Acemoglu - Can't We All Be More Like Scandinavians - Asymmetric Growth and Institutions in An Interdependent World (2012)Dokument49 SeitenDaron Acemoglu - Can't We All Be More Like Scandinavians - Asymmetric Growth and Institutions in An Interdependent World (2012)Naos2015Noch keine Bewertungen
- Growth, Top Incomes, and Social WelfareDokument6 SeitenGrowth, Top Incomes, and Social WelfareLauraNoch keine Bewertungen
- Zuc Man Book 2015Dokument978 SeitenZuc Man Book 2015Juan ToapantaNoch keine Bewertungen
- Summary of Capital in the Twenty-First Century: by Thomas Piketty | Includes AnalysisVon EverandSummary of Capital in the Twenty-First Century: by Thomas Piketty | Includes AnalysisNoch keine Bewertungen
- Summary of Capital in the Twenty-First Century: by Thomas Piketty | Includes AnalysisVon EverandSummary of Capital in the Twenty-First Century: by Thomas Piketty | Includes AnalysisNoch keine Bewertungen
- The Myth of Capitalism: Monopolies and the Death of CompetitionVon EverandThe Myth of Capitalism: Monopolies and the Death of CompetitionBewertung: 4 von 5 Sternen4/5 (11)
- Austerity and Anarchy: Budget Cuts and Social Unrest in Europe, 1919-2008Dokument41 SeitenAusterity and Anarchy: Budget Cuts and Social Unrest in Europe, 1919-2008Niccolò BaldiniNoch keine Bewertungen
- Austerity and Anarchy: Budget Cuts and Social Unrest in Europe, 1919-2008Dokument41 SeitenAusterity and Anarchy: Budget Cuts and Social Unrest in Europe, 1919-2008richardck61Noch keine Bewertungen
- Press Discourse of UK InequalityDokument38 SeitenPress Discourse of UK InequalitymamaNoch keine Bewertungen
- Price Indexes, Inequality, and The Measurement of World PovertyDokument61 SeitenPrice Indexes, Inequality, and The Measurement of World PovertyAlejandra Sánchez ArenasNoch keine Bewertungen
- 0218 Transcript Euro Under AttackDokument19 Seiten0218 Transcript Euro Under Attackanafranchi5544Noch keine Bewertungen
- Rodrickbthe Real Exchange Rate and Economic Growth PDFDokument46 SeitenRodrickbthe Real Exchange Rate and Economic Growth PDFPatricia GarciaNoch keine Bewertungen
- How To Build The Economy of The FutureDokument18 SeitenHow To Build The Economy of The FutureHamilton ReporterNoch keine Bewertungen
- Discussion Paper Series: Austerity and Anarchy: Budget Cuts and Social Unrest in EUROPE, 1919-2009Dokument30 SeitenDiscussion Paper Series: Austerity and Anarchy: Budget Cuts and Social Unrest in EUROPE, 1919-2009aasdad6657Noch keine Bewertungen
- Alesina, Alberto Et Al. (2010) - Fiscal Adjustments Lessons From Recent HistoryDokument18 SeitenAlesina, Alberto Et Al. (2010) - Fiscal Adjustments Lessons From Recent HistoryAnita SchneiderNoch keine Bewertungen
- On The Paper of Professor Winters: Partha S. DasguptaDokument70 SeitenOn The Paper of Professor Winters: Partha S. DasguptaThe VaticanNoch keine Bewertungen
- Absolute Return Oct 2015Dokument9 SeitenAbsolute Return Oct 2015CanadianValue0% (1)
- How Do Business and Financial Cycles Interact JIEDokument13 SeitenHow Do Business and Financial Cycles Interact JIEhclitlNoch keine Bewertungen
- Pritchett 1997 Divergence PDFDokument38 SeitenPritchett 1997 Divergence PDFMauro Jurado SalcedoNoch keine Bewertungen
- Development Economics: by Debraj Ray, New York UniversityDokument31 SeitenDevelopment Economics: by Debraj Ray, New York Universitynyadav_200% (2)
- ResearchDokument18 SeitenResearchsundar kaveetaNoch keine Bewertungen
- The Real Exchange Rate and Economic Growth, Theory and Evidence by Dani RodrikDokument37 SeitenThe Real Exchange Rate and Economic Growth, Theory and Evidence by Dani RodrikPeterrockersoneNoch keine Bewertungen
- Pike Tty Zuc Man 2015Dokument71 SeitenPike Tty Zuc Man 2015Juan ToapantaNoch keine Bewertungen
- Inequality and Evolution: The Biological Determinants of Capitalism, Socialism and Income InequalityVon EverandInequality and Evolution: The Biological Determinants of Capitalism, Socialism and Income InequalityNoch keine Bewertungen
- LIMITATIONS OF GDPDokument8 SeitenLIMITATIONS OF GDPjohn nashNoch keine Bewertungen
- Piketty2018 PDFDokument174 SeitenPiketty2018 PDFDanielleNoch keine Bewertungen
- WSJ 10-21-04 Why Do Americans Work More Than EuropeansDokument3 SeitenWSJ 10-21-04 Why Do Americans Work More Than Europeansrotor113Noch keine Bewertungen
- A Quarterly Magazine of The IMFDokument7 SeitenA Quarterly Magazine of The IMFArqamNoch keine Bewertungen
- Relative Factor Abundance and Trade: Peter DebaereDokument22 SeitenRelative Factor Abundance and Trade: Peter DebaereGonzalo Rafael MedinaNoch keine Bewertungen
- Inequality NotesDokument5 SeitenInequality NotesShivangi YadavNoch keine Bewertungen
- Economic Crises Impact on Long-Run Wealth InequalityDokument30 SeitenEconomic Crises Impact on Long-Run Wealth InequalityBouchra El MourabitNoch keine Bewertungen
- Emerging Markets Lose Their Punch as Growth Model StallsDokument3 SeitenEmerging Markets Lose Their Punch as Growth Model Stallspnbchari6471Noch keine Bewertungen
- BCG2021 1Dokument61 SeitenBCG2021 1ab theproNoch keine Bewertungen
- Economics After the Crisis Book Review: Rejecting Market Fundamentalism IdeologyDokument12 SeitenEconomics After the Crisis Book Review: Rejecting Market Fundamentalism IdeologyDimitris RoutosNoch keine Bewertungen
- Piketty's Inequality Story in 6 ChartsDokument4 SeitenPiketty's Inequality Story in 6 Chartsasdf_22Noch keine Bewertungen
- Public Capital and Growth: Serkan Arslanalp, Fabian Bornhorst, Sanjeev Gupta, and Elsa SzeDokument35 SeitenPublic Capital and Growth: Serkan Arslanalp, Fabian Bornhorst, Sanjeev Gupta, and Elsa Szeakita_1610Noch keine Bewertungen
- Mauldin March 29Dokument18 SeitenMauldin March 29richardck61Noch keine Bewertungen
- Catching Up, Forging Ahead, and Falling Behind (Abramovitz)Dokument3 SeitenCatching Up, Forging Ahead, and Falling Behind (Abramovitz)AB-0% (1)
- Piketty and Saez (2003) Income Inequality in The US - Reading SummaryDokument4 SeitenPiketty and Saez (2003) Income Inequality in The US - Reading SummaryHuiqing TeoNoch keine Bewertungen
- Chapter 1 - Monitoring Macroeconomic Performance PDFDokument29 SeitenChapter 1 - Monitoring Macroeconomic Performance PDFshivam jangidNoch keine Bewertungen
- Chris Bowen m2Dokument9 SeitenChris Bowen m2Political AlertNoch keine Bewertungen
- Trade, Growth and Poverty ReductionDokument12 SeitenTrade, Growth and Poverty Reductionmanu2308Noch keine Bewertungen
- Answers AllChapsDokument163 SeitenAnswers AllChapsAnonymous L7XrxpeI1zNoch keine Bewertungen
- The Effect of Income Inequality and Economic Growth and Health in Italy CHP 1 & 2Dokument6 SeitenThe Effect of Income Inequality and Economic Growth and Health in Italy CHP 1 & 2Hina MubarakNoch keine Bewertungen
- A History of The Global Economy The WhyDokument16 SeitenA History of The Global Economy The WhyМенеджмент КПИNoch keine Bewertungen
- Adcock Special RapporteurDokument24 SeitenAdcock Special RapporteurRodrigo LlanesNoch keine Bewertungen
- Merry Pluralismo Jurídico GlobalDokument17 SeitenMerry Pluralismo Jurídico GlobalRodrigo LlanesNoch keine Bewertungen
- Snyder ColonialismDokument43 SeitenSnyder ColonialismRodrigo LlanesNoch keine Bewertungen
- Zapf EthnicityPerformanceDokument16 SeitenZapf EthnicityPerformanceRodrigo LlanesNoch keine Bewertungen
- Dirlik PostcolonialAuraDokument29 SeitenDirlik PostcolonialAuraRodrigo LlanesNoch keine Bewertungen
- Lipset American StudentDokument46 SeitenLipset American StudentRodrigo LlanesNoch keine Bewertungen
- American Association For The Advancement of ScienceDokument2 SeitenAmerican Association For The Advancement of ScienceRodrigo LlanesNoch keine Bewertungen
- Lutz AnthropologyWarDokument14 SeitenLutz AnthropologyWarRodrigo LlanesNoch keine Bewertungen
- Blacker ConflictDokument31 SeitenBlacker ConflictRodrigo LlanesNoch keine Bewertungen
- Capital Is BackDokument51 SeitenCapital Is BackLucio D'AmeliaNoch keine Bewertungen
- Eduard Fuchs Collector Historian Analyzed Reception Art WorksDokument33 SeitenEduard Fuchs Collector Historian Analyzed Reception Art WorksRodrigo LlanesNoch keine Bewertungen
- NTEGRITY and DISRESPECT Principlesof A Conception of Morality Basedon The Theoryof RecognitionDokument16 SeitenNTEGRITY and DISRESPECT Principlesof A Conception of Morality Basedon The Theoryof RecognitionJuan Camilo Pulgarín100% (1)
- Eduard Fuchs Collector Historian Analyzed Reception Art WorksDokument33 SeitenEduard Fuchs Collector Historian Analyzed Reception Art WorksRodrigo LlanesNoch keine Bewertungen
- Post OrientalismDokument301 SeitenPost Orientalismmengkymagubat100% (5)
- Bentley EthnicityPracticeDokument33 SeitenBentley EthnicityPracticeRodrigo LlanesNoch keine Bewertungen
- Powdermaker LeadershipDokument24 SeitenPowdermaker LeadershipRodrigo LlanesNoch keine Bewertungen
- Taussig TerrorUsualBenjaminDokument19 SeitenTaussig TerrorUsualBenjaminRodrigo LlanesNoch keine Bewertungen
- Jew Khazar.1092Dokument33 SeitenJew Khazar.1092siegeNoch keine Bewertungen
- Povinelli CunningRecognitionDokument8 SeitenPovinelli CunningRecognitionRodrigo LlanesNoch keine Bewertungen
- Aguirre AppliedAnthropologyMexicoDokument11 SeitenAguirre AppliedAnthropologyMexicoRodrigo LlanesNoch keine Bewertungen
- Humanity & Society 2012 Brucato 76 84Dokument10 SeitenHumanity & Society 2012 Brucato 76 84Leopoldo ArtilesNoch keine Bewertungen
- Aguirre AppliedAnthropologyMexicoDokument11 SeitenAguirre AppliedAnthropologyMexicoRodrigo LlanesNoch keine Bewertungen
- America, China Vie for Africa's OilDokument14 SeitenAmerica, China Vie for Africa's OilRodrigo LlanesNoch keine Bewertungen
- Powdermaker MoviesDokument9 SeitenPowdermaker MoviesRodrigo LlanesNoch keine Bewertungen
- Mead Intercultural JapaneseStudiesDokument3 SeitenMead Intercultural JapaneseStudiesRodrigo LlanesNoch keine Bewertungen
- Froomkin DeathPrivacyDokument84 SeitenFroomkin DeathPrivacyRodrigo LlanesNoch keine Bewertungen
- Povinelli AustralianAboriginesDokument35 SeitenPovinelli AustralianAboriginesRodrigo LlanesNoch keine Bewertungen
- WikiLeaks PROTECT-IP BenklerDokument11 SeitenWikiLeaks PROTECT-IP Benklermary engNoch keine Bewertungen
- Aguirre AppliedAnthropologyMexicoDokument11 SeitenAguirre AppliedAnthropologyMexicoRodrigo LlanesNoch keine Bewertungen
- Demystifying Mutual Funds - 30june2017Dokument22 SeitenDemystifying Mutual Funds - 30june2017Naveen RaajNoch keine Bewertungen
- Value Research 1Dokument4.781 SeitenValue Research 1akshNoch keine Bewertungen
- ACK138389790080523Dokument1 SeiteACK138389790080523Vishal GoyalNoch keine Bewertungen
- Vault Career Guide To Private Wealth Management (2007)Dokument248 SeitenVault Career Guide To Private Wealth Management (2007)Christopher KingNoch keine Bewertungen
- Chapter 13 A-C PDFDokument13 SeitenChapter 13 A-C PDFKim Arvin DalisayNoch keine Bewertungen
- Financial Management FundamentalsDokument27 SeitenFinancial Management Fundamentalsharsh gawliNoch keine Bewertungen
- Why philosophers disagree on basic income and social justiceDokument19 SeitenWhy philosophers disagree on basic income and social justicerabarber1900Noch keine Bewertungen
- Early Civilizations and the Development of Social ClassesDokument8 SeitenEarly Civilizations and the Development of Social ClassesKiefer GoebNoch keine Bewertungen
- 146 - 1100 Words You Need To Know Weeks 1-8Dokument34 Seiten146 - 1100 Words You Need To Know Weeks 1-8Elene DzotsenidzeNoch keine Bewertungen
- Edu 726 Economics Methods (Noun)Dokument103 SeitenEdu 726 Economics Methods (Noun)Osifo OsarumwenseNoch keine Bewertungen
- Rockefeller File, TheDokument150 SeitenRockefeller File, TheElFinDelFinNoch keine Bewertungen
- Income Statement Analysis of Vitarich CorporationDokument11 SeitenIncome Statement Analysis of Vitarich CorporationLynnie Jane JauculanNoch keine Bewertungen
- Objectives of Foreign Direct InvestmentDokument6 SeitenObjectives of Foreign Direct InvestmentSwati KatariaNoch keine Bewertungen
- Agriculture Cooperatives Articles of CooperationDokument8 SeitenAgriculture Cooperatives Articles of CooperationBebean Aninang100% (1)
- Income Statement PreparationDokument11 SeitenIncome Statement PreparationIbi Ifti100% (1)
- 06 Chapter 1Dokument52 Seiten06 Chapter 1yezdiarwNoch keine Bewertungen
- Full Report Ubs Ag Consolidated 2q23Dokument98 SeitenFull Report Ubs Ag Consolidated 2q23Dinheirama.comNoch keine Bewertungen
- Financial Statement AssignmentDokument16 SeitenFinancial Statement Assignmentapi-275910271Noch keine Bewertungen
- MDP 39015031297875 1693762758Dokument413 SeitenMDP 39015031297875 1693762758kapilNoch keine Bewertungen
- 1 Merged PDFDokument296 Seiten1 Merged PDFJosé Luis Cervantes CortésNoch keine Bewertungen
- 6) Classical TheoriesDokument19 Seiten6) Classical TheoriesSagar ShahNoch keine Bewertungen
- The Ingenuity GapDokument53 SeitenThe Ingenuity GapThao Nguyen ThuNoch keine Bewertungen
- Learning Activity Sheet Business Finance Introduction To Financial Management Quarter 1 - Week 1Dokument16 SeitenLearning Activity Sheet Business Finance Introduction To Financial Management Quarter 1 - Week 1Dhee SulvitechNoch keine Bewertungen
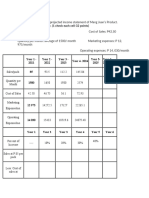
- Projected income statement for Mang Juan's ProductDokument2 SeitenProjected income statement for Mang Juan's ProductFrancis BordonNoch keine Bewertungen
- City & Society Volume 24 Issue 2 2012 (Doi 10.1111/j.1548-744x.2012.01071.x) ASEF BAYAT - Politics in The City-Inside-Out PDFDokument19 SeitenCity & Society Volume 24 Issue 2 2012 (Doi 10.1111/j.1548-744x.2012.01071.x) ASEF BAYAT - Politics in The City-Inside-Out PDFMahmoudAhmedNoch keine Bewertungen
- The Wealth-Tax Act, 1957Dokument16 SeitenThe Wealth-Tax Act, 1957abhishek_ruiaNoch keine Bewertungen
- Of Wealth and Death Materialism Mortality SalienceDokument5 SeitenOf Wealth and Death Materialism Mortality SalienceRahmatNoch keine Bewertungen
- Template Persiapan Nikah @ridwanpapuyDokument22 SeitenTemplate Persiapan Nikah @ridwanpapuyAmelia widya PutriNoch keine Bewertungen
- The Richest Man in BabylonDokument3 SeitenThe Richest Man in BabylonHyamber Dennis IorpuuNoch keine Bewertungen
- Bond CalculatorDokument14 SeitenBond CalculatorWaseem ButtNoch keine Bewertungen