Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- OMM807100043 - 3 (PID Controller Manual)Dokument98 SeitenOMM807100043 - 3 (PID Controller Manual)cengiz kutukcu100% (3)
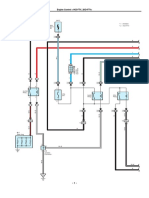
- Diagrama Hilux 1KD-2KD PDFDokument11 SeitenDiagrama Hilux 1KD-2KD PDFJeni100% (1)
- Portland Cement: Standard Specification ForDokument9 SeitenPortland Cement: Standard Specification ForHishmat Ezz AlarabNoch keine Bewertungen
- Reclaimer PDFDokument8 SeitenReclaimer PDFSiti NurhidayatiNoch keine Bewertungen
- Cleartrip Flight Domestic E-TicketDokument1 SeiteCleartrip Flight Domestic E-TicketSherjil OzairNoch keine Bewertungen
- 5154130662669586953-Advisor Application FormDokument1 Seite5154130662669586953-Advisor Application FormSherjil OzairNoch keine Bewertungen
- Identification Requirements: All You Need To Know About Money Laundering Regulations and How This Affects YouDokument2 SeitenIdentification Requirements: All You Need To Know About Money Laundering Regulations and How This Affects YouSherjil OzairNoch keine Bewertungen
- Iron-Rich Green VegetablesDokument1 SeiteIron-Rich Green VegetablesSherjil OzairNoch keine Bewertungen
- Reflections On Rilke and Jojo Rabbit by Harriet - Poetry FoundationDokument1 SeiteReflections On Rilke and Jojo Rabbit by Harriet - Poetry FoundationSherjil OzairNoch keine Bewertungen
- Representations of Space and Time in The Maximization of Information Flow in The Perception-Action LoopDokument47 SeitenRepresentations of Space and Time in The Maximization of Information Flow in The Perception-Action LoopSherjil OzairNoch keine Bewertungen
- Approved Secure English Language Test Centres: Provider Country Name of Test Centre Address City Exam Test Centre NumberDokument6 SeitenApproved Secure English Language Test Centres: Provider Country Name of Test Centre Address City Exam Test Centre NumberSherjil OzairNoch keine Bewertungen
- Unifying Count-Based Exploration and Intrinsic Motivation: ON Tezuma S EvengeDokument26 SeitenUnifying Count-Based Exploration and Intrinsic Motivation: ON Tezuma S EvengeSherjil OzairNoch keine Bewertungen
- Random Synaptic Feedback Weights Support Error Backpropagation For Deep LearningDokument10 SeitenRandom Synaptic Feedback Weights Support Error Backpropagation For Deep LearningSherjil OzairNoch keine Bewertungen
- A13 IFT2125 Intra1 enDokument7 SeitenA13 IFT2125 Intra1 enSherjil OzairNoch keine Bewertungen
- Inqlusive Newsrooms LGBTQIA Media Reference Guide English 2023 E1Dokument98 SeitenInqlusive Newsrooms LGBTQIA Media Reference Guide English 2023 E1Disability Rights AllianceNoch keine Bewertungen
- SCHEMA - Amsung 214TDokument76 SeitenSCHEMA - Amsung 214TmihaiNoch keine Bewertungen
- Tournament Rules and MechanicsDokument2 SeitenTournament Rules and MechanicsMarkAllenPascualNoch keine Bewertungen
- PERSONAL DEVELOPMENT (What Is Personal Development?)Dokument37 SeitenPERSONAL DEVELOPMENT (What Is Personal Development?)Ronafe Roncal GibaNoch keine Bewertungen
- Lecture No. 11Dokument15 SeitenLecture No. 11Sayeda JabbinNoch keine Bewertungen
- New Cisco Certification Path (From Feb2020) PDFDokument1 SeiteNew Cisco Certification Path (From Feb2020) PDFkingNoch keine Bewertungen
- 103-Article Text-514-1-10-20190329Dokument11 Seiten103-Article Text-514-1-10-20190329Elok KurniaNoch keine Bewertungen
- 1013CCJ - T3 2019 - Assessment 2 - CompleteDokument5 Seiten1013CCJ - T3 2019 - Assessment 2 - CompleteGeorgie FriedrichsNoch keine Bewertungen
- Diffrent Types of MapDokument3 SeitenDiffrent Types of MapIan GamitNoch keine Bewertungen
- Feb-May SBI StatementDokument2 SeitenFeb-May SBI StatementAshutosh PandeyNoch keine Bewertungen
- Detailed Lesson Plan (Lit)Dokument19 SeitenDetailed Lesson Plan (Lit)Shan QueentalNoch keine Bewertungen
- Bus105 Pcoq 2 100%Dokument9 SeitenBus105 Pcoq 2 100%Gish KK.GNoch keine Bewertungen
- RESUME1Dokument2 SeitenRESUME1sagar09100% (5)
- Form 1 1 MicroscopeDokument46 SeitenForm 1 1 MicroscopeHarshil PatelNoch keine Bewertungen
- " Suratgarh Super Thermal Power Station": Submitted ToDokument58 Seiten" Suratgarh Super Thermal Power Station": Submitted ToSahuManishNoch keine Bewertungen
- SUNGLAO - TM PortfolioDokument60 SeitenSUNGLAO - TM PortfolioGIZELLE SUNGLAONoch keine Bewertungen
- Bulk Separator - V-1201 Method StatementDokument2 SeitenBulk Separator - V-1201 Method StatementRoshin99Noch keine Bewertungen
- American J of Comm Psychol - 2023 - Palmer - Looted Artifacts and Museums Perpetuation of Imperialism and RacismDokument9 SeitenAmerican J of Comm Psychol - 2023 - Palmer - Looted Artifacts and Museums Perpetuation of Imperialism and RacismeyeohneeduhNoch keine Bewertungen
- Mericon™ Quant GMO HandbookDokument44 SeitenMericon™ Quant GMO HandbookAnisoara HolbanNoch keine Bewertungen
- General Introduction: 1.1 What Is Manufacturing (MFG) ?Dokument19 SeitenGeneral Introduction: 1.1 What Is Manufacturing (MFG) ?Mohammed AbushammalaNoch keine Bewertungen
- EceDokument75 SeitenEcevignesh16vlsiNoch keine Bewertungen
- Sample TRM All Series 2020v1 - ShortseDokument40 SeitenSample TRM All Series 2020v1 - ShortseSuhail AhmadNoch keine Bewertungen
- Program Need Analysis Questionnaire For DKA ProgramDokument6 SeitenProgram Need Analysis Questionnaire For DKA ProgramAzman Bin TalibNoch keine Bewertungen
- Mortars in Norway From The Middle Ages To The 20th Century: Con-Servation StrategyDokument8 SeitenMortars in Norway From The Middle Ages To The 20th Century: Con-Servation StrategyUriel PerezNoch keine Bewertungen
- Module 1 Dynamics of Rigid BodiesDokument11 SeitenModule 1 Dynamics of Rigid BodiesBilly Joel DasmariñasNoch keine Bewertungen
- Module 0-Course Orientation: Objectives OutlineDokument2 SeitenModule 0-Course Orientation: Objectives OutlineEmmanuel CausonNoch keine Bewertungen