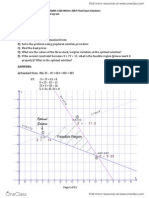
Das könnte Ihnen auch gefallen
- Introduction To Optimization: (Ii) Constrained and Unconstrained OptimizationDokument16 SeitenIntroduction To Optimization: (Ii) Constrained and Unconstrained Optimizationdurgasharma123Noch keine Bewertungen
- Assignment 1Dokument4 SeitenAssignment 1Ashish KushwahaNoch keine Bewertungen
- Extreme Point Method For Linear Programming PDFDokument10 SeitenExtreme Point Method For Linear Programming PDFHassan NathaniNoch keine Bewertungen
- 6 OneD Unconstrained OptDokument29 Seiten6 OneD Unconstrained OptLolie SaidNoch keine Bewertungen
- Lecture 3.b - Dynamic Programming PDFDokument46 SeitenLecture 3.b - Dynamic Programming PDFRagnarokNoch keine Bewertungen
- 1 Introduction To Optimum Design PDFDokument15 Seiten1 Introduction To Optimum Design PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- Optimization With Multiple Objectives: Eva K. Lee, Ph.D. Eva - Lee@isye - Gatech.eduDokument17 SeitenOptimization With Multiple Objectives: Eva K. Lee, Ph.D. Eva - Lee@isye - Gatech.eduBarathNoch keine Bewertungen
- Chapter 8 Process OptimisationDokument26 SeitenChapter 8 Process OptimisationBatul KhuzemaNoch keine Bewertungen
- Applications Linear ProgrammingDokument36 SeitenApplications Linear ProgrammingShashwat RanjanNoch keine Bewertungen
- The Method of Lagrange MultipliersDokument4 SeitenThe Method of Lagrange MultipliersSon HoangNoch keine Bewertungen
- Pyrolysis of Waste Tyres Into Fuels: Group MembersDokument18 SeitenPyrolysis of Waste Tyres Into Fuels: Group Membersmuhammad ibrahimNoch keine Bewertungen
- W2 L2 Air Pollution Concentration ModelsDokument40 SeitenW2 L2 Air Pollution Concentration ModelsMc JaeNoch keine Bewertungen
- Ee/Econ 458 Integer Programming: J. MccalleyDokument33 SeitenEe/Econ 458 Integer Programming: J. Mccalleykaren dejoNoch keine Bewertungen
- Business Location Decisions: Dr. Everette S. Gardner, JRDokument19 SeitenBusiness Location Decisions: Dr. Everette S. Gardner, JRRikudou SenninNoch keine Bewertungen
- Sensitivity Analysis and Duality of LP ProblemsDokument29 SeitenSensitivity Analysis and Duality of LP ProblemsHồng DiễmNoch keine Bewertungen
- Tutorials + SolutionsDokument21 SeitenTutorials + SolutionsAshwin SeeruttunNoch keine Bewertungen
- Lecture 3.a - Exact Methods PDFDokument50 SeitenLecture 3.a - Exact Methods PDFRagnarokNoch keine Bewertungen
- Chemical Process Optimization HW 2: FXX X XXDokument1 SeiteChemical Process Optimization HW 2: FXX X XXAugusto De La Cruz CamayoNoch keine Bewertungen
- CHE3164 Assignment 1 2016 - Rev 2Dokument3 SeitenCHE3164 Assignment 1 2016 - Rev 2Mashroof AhmedNoch keine Bewertungen
- Solving Multiobjective Models With GAMSDokument19 SeitenSolving Multiobjective Models With GAMSoida_adNoch keine Bewertungen
- Lecture 1Dokument5 SeitenLecture 1Anonymous njZRxRNoch keine Bewertungen
- 3330 Winter 2007 Final Exam With SolutionsDokument11 Seiten3330 Winter 2007 Final Exam With SolutionsmaxzNoch keine Bewertungen
- Heuristic Design of Reaction/Separation ProcessesDokument8 SeitenHeuristic Design of Reaction/Separation ProcessesAndrea VittoNoch keine Bewertungen
- Lecture 5 - Local Search GRASPDokument52 SeitenLecture 5 - Local Search GRASPRagnarokNoch keine Bewertungen
- 5 - Facility Location DecisionDokument54 Seiten5 - Facility Location DecisionRaghav MohtaNoch keine Bewertungen
- CDB 4313 Heat Integration - Case Studies Week 3Dokument15 SeitenCDB 4313 Heat Integration - Case Studies Week 3harvin raoNoch keine Bewertungen
- Air Pollution 3Dokument28 SeitenAir Pollution 3api-3824811100% (1)
- Lecture 4.a - Greedy AlgorithmsDokument45 SeitenLecture 4.a - Greedy AlgorithmsRagnarokNoch keine Bewertungen
- Hazard Identification - Jan 2019Dokument28 SeitenHazard Identification - Jan 2019Abdul Remy100% (1)
- Ugpa3033 Process Optimization and Simulation Tutorial 4Dokument1 SeiteUgpa3033 Process Optimization and Simulation Tutorial 4Tko Kai OnnNoch keine Bewertungen
- Chapter 4Dokument35 SeitenChapter 4Leon TanNoch keine Bewertungen
- CH 4-1 To 4-4 Risk Metrics PDFDokument31 SeitenCH 4-1 To 4-4 Risk Metrics PDFSoniaNoch keine Bewertungen
- Chapter 18 Metabolic PathwaysDokument133 SeitenChapter 18 Metabolic PathwaysM3hdi87Noch keine Bewertungen
- Lect 4multicomponemts DistillationDokument47 SeitenLect 4multicomponemts DistillationNihad S ZainNoch keine Bewertungen
- Multi Obj Unit 5Dokument39 SeitenMulti Obj Unit 5Kunal AgarwalNoch keine Bewertungen
- Unit Outline and Introduction To Design: © HB Vuthaluru 2006Dokument41 SeitenUnit Outline and Introduction To Design: © HB Vuthaluru 2006Adrian John Soe MyintNoch keine Bewertungen
- Specialization PSE - Aug2011Dokument14 SeitenSpecialization PSE - Aug2011Kenneth TeoNoch keine Bewertungen
- Air Pollution (Guy Hutton)Dokument35 SeitenAir Pollution (Guy Hutton)Silvano RamirezNoch keine Bewertungen
- Linear Programming Simplex in Matrix Form and The Fundamental InsightDokument151 SeitenLinear Programming Simplex in Matrix Form and The Fundamental InsightMichael TateNoch keine Bewertungen
- Basic Distillation: Process Modeling Using Aspen Plus (Radfrac Models)Dokument21 SeitenBasic Distillation: Process Modeling Using Aspen Plus (Radfrac Models)ashraf-84Noch keine Bewertungen
- Group Assignment Q1Dokument2 SeitenGroup Assignment Q1Muhdhadi SajariNoch keine Bewertungen
- FYDP 2 Students Briefing PDFDokument15 SeitenFYDP 2 Students Briefing PDFCai ZiminNoch keine Bewertungen
- CE 3105 Multicomponent Distillation TutorialDokument2 SeitenCE 3105 Multicomponent Distillation TutorialkmafeNoch keine Bewertungen
- Heat Integration: Automated Design of Heat Exchanger NetworksDokument23 SeitenHeat Integration: Automated Design of Heat Exchanger NetworksTheepa SubramaniamNoch keine Bewertungen
- Air Quality ModelDokument30 SeitenAir Quality ModelPanosMitsopoulosNoch keine Bewertungen
- Plant Layout: Che 4253 - Design I Che 4253 - Design IDokument10 SeitenPlant Layout: Che 4253 - Design I Che 4253 - Design Ivb_pol@yahooNoch keine Bewertungen
- Chemical Process Optimization HW 3: Stream Data For HW3Dokument1 SeiteChemical Process Optimization HW 3: Stream Data For HW3Augusto De La Cruz CamayoNoch keine Bewertungen
- KKT ConditionsDokument15 SeitenKKT ConditionsAdao AntunesNoch keine Bewertungen
- L30 - Integer Linear Programming - Branch and Bound AlgorithmDokument16 SeitenL30 - Integer Linear Programming - Branch and Bound AlgorithmAryaman Mandhana0% (1)
- Notes5 Simple ReactorsDokument40 SeitenNotes5 Simple ReactorsstorkjjNoch keine Bewertungen
- Smit Ds Chapter 2Dokument29 SeitenSmit Ds Chapter 2alinoriNoch keine Bewertungen
- Optimization Using Calculus: Optimization of Functions of Multiple Variables Subject To Equality ConstraintsDokument19 SeitenOptimization Using Calculus: Optimization of Functions of Multiple Variables Subject To Equality Constraintsprasaad08Noch keine Bewertungen
- Air Pollution Measurement Modelling and Mitigation Third EditionDokument17 SeitenAir Pollution Measurement Modelling and Mitigation Third EditionРаденко МарјановићNoch keine Bewertungen
- Lecture 4.b - Metaheuristics - Basic ConceptsDokument42 SeitenLecture 4.b - Metaheuristics - Basic ConceptsRagnarokNoch keine Bewertungen
- Thermodynamics and Simulation of Mass Transfer Equipment 2Dokument8 SeitenThermodynamics and Simulation of Mass Transfer Equipment 2David DualNoch keine Bewertungen
- Recycle. Process EngineeringDokument20 SeitenRecycle. Process EngineeringDarel WilliamsNoch keine Bewertungen
- Heat Ingeration of Distillation ColumnsDokument36 SeitenHeat Ingeration of Distillation ColumnsNorzaifee NizamudinNoch keine Bewertungen
- 05 Pinch MFDokument41 Seiten05 Pinch MFrajat100% (1)
- 7 Numerical Methods For Unconstrained Optimization PDFDokument25 Seiten7 Numerical Methods For Unconstrained Optimization PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- Chemical Engineering Plant Cost Index, 1950 To 2015Dokument1 SeiteChemical Engineering Plant Cost Index, 1950 To 2015Bianchi Benavides0% (1)
- MATLAB and Its Application - Final 2009 - 1 - 14 - PDFDokument2 SeitenMATLAB and Its Application - Final 2009 - 1 - 14 - PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 6 Linear Algebraic Equations PDFDokument68 Seiten6 Linear Algebraic Equations PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 2 Array and Matrix Operations PDFDokument39 Seiten2 Array and Matrix Operations PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- Exam 1 PDFDokument1 SeiteExam 1 PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 14 Advanced Techniques in Problem Solving PDFDokument58 Seiten14 Advanced Techniques in Problem Solving PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 13 Problem Solving With MATLAB PDFDokument64 Seiten13 Problem Solving With MATLAB PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- Exam1 (Solution) PDFDokument6 SeitenExam1 (Solution) PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 11 Basic Principles and CalculationsDokument64 Seiten11 Basic Principles and CalculationsJue RasepNoch keine Bewertungen
- 12 Regression and Correlation of Data PDFDokument123 Seiten12 Regression and Correlation of Data PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 13 Problem Solving With MATLAB PDFDokument64 Seiten13 Problem Solving With MATLAB PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- Mid (Solution) PDFDokument6 SeitenMid (Solution) PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 8 Probability, Statistics and Interpolation PDFDokument86 Seiten8 Probability, Statistics and Interpolation PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 10 Simulink PDFDokument32 Seiten10 Simulink PDFAugusto De La Cruz Camayo100% (1)
- 4 Array and Matrix Operations PDFDokument65 Seiten4 Array and Matrix Operations PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 1 An Overview of MATLAB PDFDokument54 Seiten1 An Overview of MATLAB PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 5 Functions and Files PDFDokument35 Seiten5 Functions and Files PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 7 Linear Algebraic Equations PDFDokument69 Seiten7 Linear Algebraic Equations PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 6 Programming With MATLAB PDFDokument66 Seiten6 Programming With MATLAB PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 3 Commands-Based MATLAB Plotting PDFDokument27 Seiten3 Commands-Based MATLAB Plotting PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 6 Numerical Methods For Constrained Optimization PDFDokument137 Seiten6 Numerical Methods For Constrained Optimization PDFAugusto De La Cruz Camayo100% (1)
- 0 Engineering Programming Using MATLAB PDFDokument26 Seiten0 Engineering Programming Using MATLAB PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 4 Linear Programming PDFDokument202 Seiten4 Linear Programming PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 8 Mixed-Integer Linear Programming PDFDokument70 Seiten8 Mixed-Integer Linear Programming PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 7 Optimum Design With MATLAB PDFDokument13 Seiten7 Optimum Design With MATLAB PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 11 Synthesis of Heat Exchanger Networks PDFDokument54 Seiten11 Synthesis of Heat Exchanger Networks PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 9 Process Synthesis PDFDokument33 Seiten9 Process Synthesis PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 2 Optimum Design Problem Formulation PDFDokument49 Seiten2 Optimum Design Problem Formulation PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- 1 Introduction To Optimum Design PDFDokument15 Seiten1 Introduction To Optimum Design PDFAugusto De La Cruz CamayoNoch keine Bewertungen
- TH 122ISMEConference2003Dokument10 SeitenTH 122ISMEConference2003Krishna SinghNoch keine Bewertungen
- Projected Gradient Methods For Linearly Constrained Problems - Calamai, Moré (1987)Dokument24 SeitenProjected Gradient Methods For Linearly Constrained Problems - Calamai, Moré (1987)Emerson ButynNoch keine Bewertungen
- IterMethBook 2nded PDFDokument567 SeitenIterMethBook 2nded PDF甘逸凱Noch keine Bewertungen
- Kelley IterativeMethodsforLinearandNonlinearEqsDokument172 SeitenKelley IterativeMethodsforLinearandNonlinearEqsRaul Gonzalez100% (1)
- Rodi+Mackie 2001Dokument14 SeitenRodi+Mackie 2001RandiRusdianaNoch keine Bewertungen
- Time-Integration Methods For Finite Element Discretisations of The Second-Order Maxwell EquationDokument16 SeitenTime-Integration Methods For Finite Element Discretisations of The Second-Order Maxwell EquationEisten Daniel Neto BombaNoch keine Bewertungen
- Gradient Based OptimizationDokument3 SeitenGradient Based OptimizationLuis100% (1)
- Figueiredo Et Al. - 2007 - Gradient Projection For Sparse Reconstruction Application To Compressed Sensing and Other Inverse Problems-AnnotatedDokument12 SeitenFigueiredo Et Al. - 2007 - Gradient Projection For Sparse Reconstruction Application To Compressed Sensing and Other Inverse Problems-Annotatedyjang88Noch keine Bewertungen
- ChannelFlow Readme PDFDokument16 SeitenChannelFlow Readme PDFAshish Kotwal100% (1)
- Ansys Manual1Dokument245 SeitenAnsys Manual1anand_cadenggNoch keine Bewertungen
- Ansys Electric Field AnalysisDokument93 SeitenAnsys Electric Field AnalysisUmesh Vishwakarma100% (1)
- Vasp UserguideDokument156 SeitenVasp UserguideputsoNoch keine Bewertungen
- Gradient Based OptimizationDokument24 SeitenGradient Based OptimizationMarc RomaníNoch keine Bewertungen
- Multithreaded Architectures: (Applied Parallel Programming)Dokument29 SeitenMultithreaded Architectures: (Applied Parallel Programming)YAAKOV SOLOMONNoch keine Bewertungen
- Application of Numerical Simulation at The Tunnel Site: AbstractDokument47 SeitenApplication of Numerical Simulation at The Tunnel Site: AbstractDidaBouchNoch keine Bewertungen
- ANSYS Mechanical APDL Basic Analysis GuideDokument364 SeitenANSYS Mechanical APDL Basic Analysis GuideRodolfoNoch keine Bewertungen
- STRUCTURAL - Chapter 2 - Structural Static Analysis (UP19980818)Dokument36 SeitenSTRUCTURAL - Chapter 2 - Structural Static Analysis (UP19980818)Rory Cristian Cordero RojoNoch keine Bewertungen
- Am 585 HW 4Dokument21 SeitenAm 585 HW 4Jennifer HansonNoch keine Bewertungen
- OpenFOAM Matrix SolutionDokument77 SeitenOpenFOAM Matrix SolutionAaditya RuikarNoch keine Bewertungen
- Gauss Newton and Full Newton Methods in Frequency Space Seismic Waveform InversionDokument22 SeitenGauss Newton and Full Newton Methods in Frequency Space Seismic Waveform InversionMárcioBarbozaNoch keine Bewertungen
- Numerical Analysis 2000. Vol.3Dokument526 SeitenNumerical Analysis 2000. Vol.3api-3851953100% (2)
- Marc Error CodesDokument10 SeitenMarc Error CodesbalajimeieNoch keine Bewertungen
- Global Convergence of A Modified Fletcher-Reeves Conjugate Gradient Method With Armijo-Type Line Search - Zhang, Zhou (2006)Dokument12 SeitenGlobal Convergence of A Modified Fletcher-Reeves Conjugate Gradient Method With Armijo-Type Line Search - Zhang, Zhou (2006)Emerson ButynNoch keine Bewertungen
- Mo 2010Dokument9 SeitenMo 2010ranim najibNoch keine Bewertungen
- FsolveDokument11 SeitenFsolveKeivan RSNoch keine Bewertungen
- Conjugate Gradient MethodDokument8 SeitenConjugate Gradient MethodDavid HumeNoch keine Bewertungen
- Constraints PDFDokument13 SeitenConstraints PDFabhayNoch keine Bewertungen
- CH 2 Iterative Methods PDFDokument65 SeitenCH 2 Iterative Methods PDFAshok SapkotaNoch keine Bewertungen
- Methods of Conjugate Gradients For Solving Linear SystemsDokument28 SeitenMethods of Conjugate Gradients For Solving Linear SystemsMars_CrazyNoch keine Bewertungen
- Lecture 04 - Conjugate Gradient MethodsDokument9 SeitenLecture 04 - Conjugate Gradient MethodsFanta CamaraNoch keine Bewertungen