Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Windows Programming in Assembly LanguageDokument796 SeitenWindows Programming in Assembly LanguagehangshabNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- A Scheduling Based in MILP For Non-Continuous Serial Production. Data and ResultsDokument8 SeitenA Scheduling Based in MILP For Non-Continuous Serial Production. Data and ResultshjmesaNoch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Outdoors Inc., Page 124 BH&MDokument5 SeitenOutdoors Inc., Page 124 BH&MhjmesaNoch keine Bewertungen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- h03 Essential MathDokument13 Seitenh03 Essential Mathakyadav123Noch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- NetLogo User ManualDokument460 SeitenNetLogo User ManualCharlie BrownNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Manual de Disco Duro West DigitalDokument5 SeitenManual de Disco Duro West DigitalJimmy GomezNoch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Full Text 01Dokument46 SeitenFull Text 01hjmesaNoch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Prolog DigitalDokument204 SeitenProlog DigitalhjmesaNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Smart Restaurant Food Menu System: Kshitiz Rathore, Monica Chhabi, Prakash Raghuwanshi, Prof. J.S.MorbaleDokument2 SeitenSmart Restaurant Food Menu System: Kshitiz Rathore, Monica Chhabi, Prakash Raghuwanshi, Prof. J.S.MorbaleSabariNoch keine Bewertungen
- Capacitor-Based Backup Power Supply For PLC ModulesDokument27 SeitenCapacitor-Based Backup Power Supply For PLC ModulesMikel IglesiasNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- PowerLogic P5 IEC61850 Logical Node List For ED1Dokument138 SeitenPowerLogic P5 IEC61850 Logical Node List For ED1Mahmoud ChihebNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- WindSonic GPA Manual 1405-PS-0019 Issue 16Dokument30 SeitenWindSonic GPA Manual 1405-PS-0019 Issue 16Wee WeeNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Chuyển đổi báo cáoDokument12 SeitenChuyển đổi báo cáo21OT112- Huỳnh Gia KiệtNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- MultiPad 7.0 Prime Duo PMP5770Dokument16 SeitenMultiPad 7.0 Prime Duo PMP5770Oldman TestNoch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Verilog Lab 201101 PDFDokument28 SeitenVerilog Lab 201101 PDFNuthan kumarNoch keine Bewertungen
- Quadrature-Mirror Filter BankDokument63 SeitenQuadrature-Mirror Filter BankffggNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- MadVR - Crash ReportDokument10 SeitenMadVR - Crash ReportJose MezaNoch keine Bewertungen
- Electronic Communications PDFDokument366 SeitenElectronic Communications PDFcongquy nguyen100% (1)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- ALtec-Lansing ADA880 User GuideDokument8 SeitenALtec-Lansing ADA880 User GuideMark ZickefooseNoch keine Bewertungen
- File PDFDokument10 SeitenFile PDFIntan RamadhaniNoch keine Bewertungen
- Meter-Bus Transceiver: FeaturesDokument15 SeitenMeter-Bus Transceiver: FeaturesdbmNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Samuel Afoakwa PDFDokument113 SeitenSamuel Afoakwa PDFDiego LombardoNoch keine Bewertungen
- 04-Ceragon-IP-10G Radio Configuration PDFDokument16 Seiten04-Ceragon-IP-10G Radio Configuration PDFnsn_paras_shahNoch keine Bewertungen
- Sangfor HCI White Paper 2016 JuneDokument71 SeitenSangfor HCI White Paper 2016 JuneiwakbiruNoch keine Bewertungen
- Zenith H2735DT33Dokument81 SeitenZenith H2735DT33Jose Francisco Reyes Gomez100% (1)
- Design and Simulation of PFC Based CUK CDokument6 SeitenDesign and Simulation of PFC Based CUK CSameer AnandNoch keine Bewertungen
- ECA Course FileDokument154 SeitenECA Course FilebinduscribdNoch keine Bewertungen
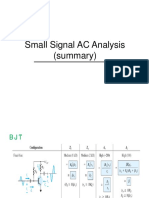
- Small AC SignalDokument32 SeitenSmall AC SignalFaye Alarva TabilismaNoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- 1.protection of Busbar Distribution From Over LoadDokument4 Seiten1.protection of Busbar Distribution From Over LoadPooja BanNoch keine Bewertungen
- PLC Q&aDokument9 SeitenPLC Q&aRendyAlf80% (5)
- Electric FenceDokument11 SeitenElectric Fencejavier_valdivia_4250% (2)
- How To Take Good Care of Your Laptop ComputerDokument5 SeitenHow To Take Good Care of Your Laptop Computerc jNoch keine Bewertungen
- Let's Start Learning The PLC Programming: Vlada MarkovicDokument4 SeitenLet's Start Learning The PLC Programming: Vlada MarkovicManuel Henríquez SantanaNoch keine Bewertungen
- Basic Electronics notes-CAPACITORSDokument17 SeitenBasic Electronics notes-CAPACITORSEphraem RobinNoch keine Bewertungen
- Re - 1989-10Dokument100 SeitenRe - 1989-10Anonymous kdqf49qbNoch keine Bewertungen
- 469B8670BCE2679 - A7726 ManualDokument22 Seiten469B8670BCE2679 - A7726 ManualCory100% (3)
- STB9NK60Z, STP9NK60Z, STP9NK60ZFPDokument19 SeitenSTB9NK60Z, STP9NK60Z, STP9NK60ZFPyokonakagimaNoch keine Bewertungen
- Daniel Gruss Slides Training PDFDokument249 SeitenDaniel Gruss Slides Training PDFMircea PetrescuNoch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)