Das könnte Ihnen auch gefallen
- CBR KalkulusDokument20 SeitenCBR KalkulusYon setiawanNoch keine Bewertungen
- Analyzing Functions: Lab 3: 1 Numerical Experimentation: Plotting CurvesDokument7 SeitenAnalyzing Functions: Lab 3: 1 Numerical Experimentation: Plotting CurvesjuntujuntuNoch keine Bewertungen
- An Introduction to Linear Algebra and TensorsVon EverandAn Introduction to Linear Algebra and TensorsBewertung: 1 von 5 Sternen1/5 (1)
- Math (2nd Quarter) : Word Problems Involving Quadratic EquationDokument9 SeitenMath (2nd Quarter) : Word Problems Involving Quadratic EquationHannah LabordoNoch keine Bewertungen
- Derivatives: A Physics 100 TutorialDokument18 SeitenDerivatives: A Physics 100 TutorialPervela BruhaspathiNoch keine Bewertungen
- pr1 Soln PDFDokument6 Seitenpr1 Soln PDFRahulNoch keine Bewertungen
- Businessmathematicsho 150207020800 Conversion Gate01Dokument182 SeitenBusinessmathematicsho 150207020800 Conversion Gate010302038Noch keine Bewertungen
- Vector Calculus: Notes For Math1c, Spring Term 2011Dokument15 SeitenVector Calculus: Notes For Math1c, Spring Term 2011Shweta SridharNoch keine Bewertungen
- SolutionsDokument5 SeitenSolutionsShironn ĐâyyNoch keine Bewertungen
- InterpolationDokument24 SeitenInterpolationsubha_aeroNoch keine Bewertungen
- Patterns in Sys EqDokument6 SeitenPatterns in Sys EqCharlie HoangNoch keine Bewertungen
- Ald Assignment 5 AMAN AGGARWAL (2018327) : Divide and ConquerDokument12 SeitenAld Assignment 5 AMAN AGGARWAL (2018327) : Divide and ConquerRitvik GuptaNoch keine Bewertungen
- Chap GapDokument29 SeitenChap GapAlyssa VuNoch keine Bewertungen
- 03a1 MIT18 - 409F09 - Scribe21Dokument8 Seiten03a1 MIT18 - 409F09 - Scribe21Omar Leon IñiguezNoch keine Bewertungen
- Polynomial Functions of Higher DegreeDokument10 SeitenPolynomial Functions of Higher DegreedoocsNoch keine Bewertungen
- EuclideanSpace University of ArizonaDokument6 SeitenEuclideanSpace University of ArizonaSawon KhanNoch keine Bewertungen
- Least Squares Solution and Pseudo-Inverse: Bghiggins/Ucdavis/Ech256/Jan - 2012Dokument12 SeitenLeast Squares Solution and Pseudo-Inverse: Bghiggins/Ucdavis/Ech256/Jan - 2012Anonymous J1scGXwkKDNoch keine Bewertungen
- Business Mathematics HODokument182 SeitenBusiness Mathematics HOBrendaNoch keine Bewertungen
- Gauss Elimination MethodDokument15 SeitenGauss Elimination MethodAditya AgrawalNoch keine Bewertungen
- ('Christos Papadimitriou', 'Final', ' (Solution) ') Fall 2009Dokument7 Seiten('Christos Papadimitriou', 'Final', ' (Solution) ') Fall 2009John SmithNoch keine Bewertungen
- XX Open Cup Grand Prix of Warsaw Editorial: Mateusz Radecki (Radewoosh) Marek Sokolowski (Mnbvmar) September 15, 2019Dokument9 SeitenXX Open Cup Grand Prix of Warsaw Editorial: Mateusz Radecki (Radewoosh) Marek Sokolowski (Mnbvmar) September 15, 2019Roberto FrancoNoch keine Bewertungen
- Imc2000 2Dokument4 SeitenImc2000 2Arief CahyadiNoch keine Bewertungen
- Derivatives and Integrals - 2Dokument16 SeitenDerivatives and Integrals - 2Siva Kumar ArumughamNoch keine Bewertungen
- QR Factorization Chapter4Dokument12 SeitenQR Factorization Chapter4Sakıp Mehmet Küçük0% (1)
- Linear Alg Notes 2018Dokument30 SeitenLinear Alg Notes 2018Jose Luis GiriNoch keine Bewertungen
- Quadratic FunctionDokument25 SeitenQuadratic FunctionCherry Grace Sagde EuldanNoch keine Bewertungen
- Mathematical Problem SolutionsDokument8 SeitenMathematical Problem Solutionsrafael859Noch keine Bewertungen
- DDA Line Drawing AlgorithmDokument2 SeitenDDA Line Drawing AlgorithmshubhamNoch keine Bewertungen
- 2000 2 PDFDokument4 Seiten2000 2 PDFMuhammad Al KahfiNoch keine Bewertungen
- The Method of Frobenius PDFDokument25 SeitenThe Method of Frobenius PDFanon_928952887Noch keine Bewertungen
- WongDokument9 SeitenWongYamid YelaNoch keine Bewertungen
- Basic Control System With Matlab ExamplesDokument19 SeitenBasic Control System With Matlab ExamplesMostafa8425Noch keine Bewertungen
- Module 5Dokument41 SeitenModule 5cbgopinathNoch keine Bewertungen
- Big OhDokument10 SeitenBig OhFrancesHsiehNoch keine Bewertungen
- CHAP4 Transform and ConquerDokument38 SeitenCHAP4 Transform and ConquerDo DragonNoch keine Bewertungen
- Quadratic Function and Factoring Quadractic EquationDokument14 SeitenQuadratic Function and Factoring Quadractic EquationYvan OmayanNoch keine Bewertungen
- Defining Linear TransformationsDokument9 SeitenDefining Linear TransformationsAshvin GraceNoch keine Bewertungen
- Math1414 Polynomial FunctionsDokument10 SeitenMath1414 Polynomial FunctionsRichel BannisterNoch keine Bewertungen
- Chapter 2 The DerivativeDokument15 SeitenChapter 2 The DerivativeDurah AfiqahNoch keine Bewertungen
- N. P. StricklandDokument16 SeitenN. P. StricklandFranklinn Franklin FfranklinNoch keine Bewertungen
- Bernoulli Numbers and The Euler-Maclaurin Summation FormulaDokument10 SeitenBernoulli Numbers and The Euler-Maclaurin Summation FormulaApel_Apel_KingNoch keine Bewertungen
- Legend ReDokument2 SeitenLegend ReErhan SavaşNoch keine Bewertungen
- Functions For Calculus Chapter 1-Linear, Quadratic, Polynomial and RationalDokument13 SeitenFunctions For Calculus Chapter 1-Linear, Quadratic, Polynomial and RationalShaikh Usman AiNoch keine Bewertungen
- VC Ma1cAnalytical Notes Chap.1Dokument16 SeitenVC Ma1cAnalytical Notes Chap.1Kashf e AreejNoch keine Bewertungen
- Functions and Graphs IntmathDokument61 SeitenFunctions and Graphs IntmathsmeenaNoch keine Bewertungen
- Math 414 Exam 2 SolutionsDokument5 SeitenMath 414 Exam 2 SolutionseriksantosoNoch keine Bewertungen
- Bressenham's Algorithm Easily ExplainedDokument18 SeitenBressenham's Algorithm Easily ExplainedXenulhassanNoch keine Bewertungen
- Matrix Chain MultiplicationDokument11 SeitenMatrix Chain MultiplicationamukhopadhyayNoch keine Bewertungen
- Newton Forward and BackwardDokument39 SeitenNewton Forward and BackwardRoshan ShanmughanNoch keine Bewertungen
- Math Week 3Dokument14 SeitenMath Week 3Alican KaptanNoch keine Bewertungen
- Em04 IlDokument10 SeitenEm04 Ilmaantom3Noch keine Bewertungen
- GauntletDokument6 SeitenGauntletsuvo baidyaNoch keine Bewertungen
- The Number e and The Exponential FunctionDokument4 SeitenThe Number e and The Exponential Functionrosan.sapkotaNoch keine Bewertungen
- Opt1 16Dokument7 SeitenOpt1 16Venkatesh NagarajuNoch keine Bewertungen
- Iteration. Trapezium Rule.Dokument5 SeitenIteration. Trapezium Rule.arcp49Noch keine Bewertungen
- Final Exam: 1. Lots of Ones (20 Points)Dokument4 SeitenFinal Exam: 1. Lots of Ones (20 Points)FidaHussainNoch keine Bewertungen
- V Foreword VI Preface VII Authors' Profiles VIII Convention Ix Abbreviations X List of Tables Xi List of Figures Xii 1 1Dokument152 SeitenV Foreword VI Preface VII Authors' Profiles VIII Convention Ix Abbreviations X List of Tables Xi List of Figures Xii 1 1July Rodriguez100% (3)
- Learning N MsDokument16 SeitenLearning N MsElvis Capia QuispeNoch keine Bewertungen
- Deeplung PDFDokument9 SeitenDeeplung PDFElvis Capia QuispeNoch keine Bewertungen
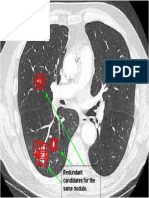
- Redundant Nodule CandidatesDokument1 SeiteRedundant Nodule CandidatesElvis Capia QuispeNoch keine Bewertungen
- Acurrate Pulmonary Nodule DetectionDokument9 SeitenAcurrate Pulmonary Nodule DetectionElvis Capia QuispeNoch keine Bewertungen
- Topics Images 02Dokument4 SeitenTopics Images 02Elvis Capia QuispeNoch keine Bewertungen
- V Foreword VI Preface VII Authors' Profiles VIII Convention Ix Abbreviations X List of Tables Xi List of Figures Xii 1 1Dokument152 SeitenV Foreword VI Preface VII Authors' Profiles VIII Convention Ix Abbreviations X List of Tables Xi List of Figures Xii 1 1July Rodriguez100% (3)
- Acurrate Pulmonary Nodule DetectionDokument9 SeitenAcurrate Pulmonary Nodule DetectionElvis Capia QuispeNoch keine Bewertungen
- Problem CFDokument1 SeiteProblem CFElvis Capia QuispeNoch keine Bewertungen
- Premio Fase II México & Centroamérica The ACM-ICPC in ESCOM-IPN 2015Dokument14 SeitenPremio Fase II México & Centroamérica The ACM-ICPC in ESCOM-IPN 2015Elvis Capia QuispeNoch keine Bewertungen
- Theoretical Computer Science Cheat SheetDokument10 SeitenTheoretical Computer Science Cheat SheetKoushik MandalNoch keine Bewertungen
- Lec5 PDFDokument4 SeitenLec5 PDFElvis Capia QuispeNoch keine Bewertungen
- Premio Fase II México & Centroamérica The ACM-ICPC in ESCOM-IPN 2015Dokument14 SeitenPremio Fase II México & Centroamérica The ACM-ICPC in ESCOM-IPN 2015Elvis Capia QuispeNoch keine Bewertungen
- NeercDokument15 SeitenNeercElvis Capia QuispeNoch keine Bewertungen
- Project Management - Chapter 10 RevisedDokument43 SeitenProject Management - Chapter 10 RevisedShahdNoch keine Bewertungen
- Design of An Optimal PID Controller Based On Lyapunov ApproachDokument5 SeitenDesign of An Optimal PID Controller Based On Lyapunov ApproachGuilherme HenriqueNoch keine Bewertungen
- TSPDokument21 SeitenTSPSuvankar KhanNoch keine Bewertungen
- Sampling Distribution Exam HelpDokument9 SeitenSampling Distribution Exam HelpStatistics Exam HelpNoch keine Bewertungen
- Lorentz Transformation, Time Dilation, Length Contraction and Doppler Effect - All at OnceDokument9 SeitenLorentz Transformation, Time Dilation, Length Contraction and Doppler Effect - All at Oncefaisal naveedNoch keine Bewertungen
- Formulations For A Problem of Petroleum TransportationDokument9 SeitenFormulations For A Problem of Petroleum Transportation1br4h1m0v1cNoch keine Bewertungen
- Data Science Interview Questions - 3.pdf - Top 100 Machine..Dokument1 SeiteData Science Interview Questions - 3.pdf - Top 100 Machine..khadija lasriNoch keine Bewertungen
- BoH PethuelDokument54 SeitenBoH PethuelAlex AdallomNoch keine Bewertungen
- ISYE 6420 SyllabusDokument1 SeiteISYE 6420 SyllabusYasin Çagatay GültekinNoch keine Bewertungen
- Crypto 2Dokument1.158 SeitenCrypto 2ErcümentNoch keine Bewertungen
- Adaptive Control Question Bank Without Answer KeyDokument5 SeitenAdaptive Control Question Bank Without Answer KeyMATHANKUMAR.S100% (1)
- Proc TransposeDokument8 SeitenProc Transposegeek_mohitNoch keine Bewertungen
- W7GSDokument10 SeitenW7GSHariharan BalasubramanianNoch keine Bewertungen
- Efficient Retrieval Over Documents Encrypted by Attributes inDokument10 SeitenEfficient Retrieval Over Documents Encrypted by Attributes inHarikrishnan ShunmugamNoch keine Bewertungen
- Haerdle W., Kleinow T., Stahl G. - Applied Quantitative Finance-Springer (2002)Dokument423 SeitenHaerdle W., Kleinow T., Stahl G. - Applied Quantitative Finance-Springer (2002)G HeavyNoch keine Bewertungen
- Quantum CompilingDokument37 SeitenQuantum CompilingHotdogsKimNoch keine Bewertungen
- ML Assignment-2: Unit 3Dokument21 SeitenML Assignment-2: Unit 3sirishaNoch keine Bewertungen
- Forecasting Mid-Long Term Electric Energy Consumption Through Bagging ARIMA and Exponential Smoothing MethodsDokument13 SeitenForecasting Mid-Long Term Electric Energy Consumption Through Bagging ARIMA and Exponential Smoothing MethodsAntonio José Idárraga RiascosNoch keine Bewertungen
- Operation Research Question BankDokument4 SeitenOperation Research Question Bankhosurushanker100% (1)
- Real Time Deep Learning Weapon Detection Techniques For Mitigating Lone Wolf AttacksDokument16 SeitenReal Time Deep Learning Weapon Detection Techniques For Mitigating Lone Wolf AttacksAdam HansenNoch keine Bewertungen
- Aspen ConvergenceDokument40 SeitenAspen ConvergenceKaushal SampatNoch keine Bewertungen
- Software Laboratory II CodeDokument27 SeitenSoftware Laboratory II Codeas9900276Noch keine Bewertungen
- Properties of Continuous Probability Density: Math ReviewerDokument2 SeitenProperties of Continuous Probability Density: Math ReviewerMargaveth P. BalbinNoch keine Bewertungen
- DSA Sheet by Arsh (45 Days Plan) - Sheet1Dokument7 SeitenDSA Sheet by Arsh (45 Days Plan) - Sheet1Kriti ChawreNoch keine Bewertungen
- Unit-3 TOCDokument42 SeitenUnit-3 TOCsageranimesh20Noch keine Bewertungen
- Comparative Analysis Between Different Forecasting Methods: Course: Managing Operations and Supply Chain (P501)Dokument11 SeitenComparative Analysis Between Different Forecasting Methods: Course: Managing Operations and Supply Chain (P501)towkirNoch keine Bewertungen
- Building Diversified Portfolios That Outperform Out-Of-SampleDokument33 SeitenBuilding Diversified Portfolios That Outperform Out-Of-SampleQuant BotsNoch keine Bewertungen
- MSC Part II IT 2015 Question Bank Mumbai UniversityDokument6 SeitenMSC Part II IT 2015 Question Bank Mumbai UniversityJayesh ShindeNoch keine Bewertungen
- Credit Card Fraud Detection Using Machine Learning: Ruttala Sailusha V. GnaneswarDokument7 SeitenCredit Card Fraud Detection Using Machine Learning: Ruttala Sailusha V. Gnaneswarsneha salunkeNoch keine Bewertungen
- Product Rating Engine: Guide: Mr. Uday Joshi Associate ProfessorDokument15 SeitenProduct Rating Engine: Guide: Mr. Uday Joshi Associate ProfessorDHRITI SHAHNoch keine Bewertungen
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldVon EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldBewertung: 4.5 von 5 Sternen4.5/5 (55)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessVon EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNoch keine Bewertungen
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindVon EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNoch keine Bewertungen
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveVon EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNoch keine Bewertungen
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceVon EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceBewertung: 4.5 von 5 Sternen4.5/5 (38)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldVon EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldBewertung: 4.5 von 5 Sternen4.5/5 (107)
- Generative AI: The Insights You Need from Harvard Business ReviewVon EverandGenerative AI: The Insights You Need from Harvard Business ReviewBewertung: 4.5 von 5 Sternen4.5/5 (2)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesVon EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesBewertung: 4.5 von 5 Sternen4.5/5 (13)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewVon EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewBewertung: 4.5 von 5 Sternen4.5/5 (104)
- Artificial Intelligence & Generative AI for Beginners: The Complete GuideVon EverandArtificial Intelligence & Generative AI for Beginners: The Complete GuideBewertung: 5 von 5 Sternen5/5 (1)
- Dark Data: Why What You Don’t Know MattersVon EverandDark Data: Why What You Don’t Know MattersBewertung: 4.5 von 5 Sternen4.5/5 (3)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeVon EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeBewertung: 4.5 von 5 Sternen4.5/5 (69)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Von EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Bewertung: 4 von 5 Sternen4/5 (1)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepVon EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepBewertung: 4.5 von 5 Sternen4.5/5 (19)
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziVon Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNoch keine Bewertungen
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Von EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Bewertung: 4 von 5 Sternen4/5 (15)
- Artificial Intelligence: A Guide for Thinking HumansVon EverandArtificial Intelligence: A Guide for Thinking HumansBewertung: 4.5 von 5 Sternen4.5/5 (30)
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsVon EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsNoch keine Bewertungen
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkVon EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkBewertung: 4 von 5 Sternen4/5 (7)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceVon EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceBewertung: 4 von 5 Sternen4/5 (2)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleVon EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleBewertung: 4 von 5 Sternen4/5 (16)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Von EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Noch keine Bewertungen
- Four Battlegrounds: Power in the Age of Artificial IntelligenceVon EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceBewertung: 5 von 5 Sternen5/5 (5)