Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Spring Reverb - Tank Technical ExplanationDokument12 SeitenSpring Reverb - Tank Technical ExplanationjustinNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- IO Wiring DiagramsDokument172 SeitenIO Wiring DiagramsNikola MilosevicNoch keine Bewertungen
- Balaraj SR Ui Front End DeveloperDokument10 SeitenBalaraj SR Ui Front End DeveloperharshvardhiniNoch keine Bewertungen
- Emerging Technology: Currently Developing, or That Are Expected To Be Available Within The Next Five To Ten YearsDokument42 SeitenEmerging Technology: Currently Developing, or That Are Expected To Be Available Within The Next Five To Ten YearsAddisalem Ganfure100% (2)
- Nishi Sharma: AWS Cloud EngineerDokument7 SeitenNishi Sharma: AWS Cloud EngineerKritika ShuklaNoch keine Bewertungen
- CV SaberDokument3 SeitenCV SaberVigneshInfotechNoch keine Bewertungen
- Date Employee Nam Accompanied by Visited Area School NameDokument4 SeitenDate Employee Nam Accompanied by Visited Area School NameVigneshInfotechNoch keine Bewertungen
- 2 MasDokument29 Seiten2 MasVigneshInfotechNoch keine Bewertungen
- Numbers: 5 and 6 Digits: AnswersDokument37 SeitenNumbers: 5 and 6 Digits: AnswersVigneshInfotechNoch keine Bewertungen
- 1 EvsDokument30 Seiten1 EvsVigneshInfotechNoch keine Bewertungen
- An Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorDokument39 SeitenAn Optimized Modified Parallel Implementation Design of Multiplier and Accumulator OperatorVigneshInfotechNoch keine Bewertungen
- 1 EngDokument32 Seiten1 EngVigneshInfotechNoch keine Bewertungen
- A New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmDokument8 SeitenA New VLSI Architecture of Parallel Multiplier-Accumulator Based On Radix-2 Modified Booth AlgorithmVigneshInfotechNoch keine Bewertungen
- 24-Mar-2019, CC, BZA - KZJDokument2 Seiten24-Mar-2019, CC, BZA - KZJVigneshInfotechNoch keine Bewertungen
- STUDENT Name:: Mundada Vinay Kumar EmailDokument2 SeitenSTUDENT Name:: Mundada Vinay Kumar EmailVigneshInfotechNoch keine Bewertungen
- Project Documentation Guidelines - ECE - JITS2013Dokument4 SeitenProject Documentation Guidelines - ECE - JITS2013VigneshInfotechNoch keine Bewertungen
- Matlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'Dokument1 SeiteMatlab Code:: 'Zebra - JPG' 'Image With Salt and Pepper Noise'VigneshInfotechNoch keine Bewertungen
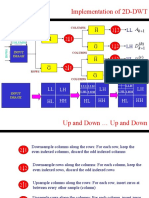
- Implementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHDokument4 SeitenImplementation of 2D-DWT: 2 1 1 2 1 2 1 2 1 2 LL LH HL HH LL LH HL HH LH HL HHVigneshInfotechNoch keine Bewertungen
- Discrete Wavelet TransformDokument10 SeitenDiscrete Wavelet TransformVigneshInfotechNoch keine Bewertungen
- 2 Evs PDFDokument39 Seiten2 Evs PDFVigneshInfotechNoch keine Bewertungen
- Performance Analysis of BPSK and DPSK Systems in The Presence of Nakagami-MDokument5 SeitenPerformance Analysis of BPSK and DPSK Systems in The Presence of Nakagami-MVigneshInfotechNoch keine Bewertungen
- Design of An Error Detection and Data Recovery Architecture For Motion Estimation Testing ApplicationsDokument3 SeitenDesign of An Error Detection and Data Recovery Architecture For Motion Estimation Testing ApplicationsVigneshInfotechNoch keine Bewertungen
- VTVL13 With ErrorDokument3 SeitenVTVL13 With ErrorVigneshInfotechNoch keine Bewertungen
- Multi-Feature and Genetic AlgorithmDokument41 SeitenMulti-Feature and Genetic AlgorithmVigneshInfotechNoch keine Bewertungen
- High-Throughput Interpolator Architecture For Low-Complexity Chase Decoding of Rs CodesDokument3 SeitenHigh-Throughput Interpolator Architecture For Low-Complexity Chase Decoding of Rs CodesVigneshInfotechNoch keine Bewertungen
- Module DescriptionDokument1 SeiteModule DescriptionVigneshInfotechNoch keine Bewertungen
- Supporting Multi Data Stores Applications in Cloud EnvironmentsDokument14 SeitenSupporting Multi Data Stores Applications in Cloud EnvironmentsVigneshInfotechNoch keine Bewertungen
- Title NO.: Acknowledgement List of FiguresDokument3 SeitenTitle NO.: Acknowledgement List of FiguresVigneshInfotechNoch keine Bewertungen
- Inner Bound On The Gdof of The K-User Mimo Gaussian Symmetric Interference ChannelDokument8 SeitenInner Bound On The Gdof of The K-User Mimo Gaussian Symmetric Interference ChannelVigneshInfotechNoch keine Bewertungen
- Image Retrieval Using Multi-Feature and Genetic Algorithm: Under The Guidance of K.Venkatramana Sir Associate ProfessorDokument13 SeitenImage Retrieval Using Multi-Feature and Genetic Algorithm: Under The Guidance of K.Venkatramana Sir Associate ProfessorVigneshInfotechNoch keine Bewertungen
- Supporting Multi Data Stores Applications in Cloud EnvironmentsDokument6 SeitenSupporting Multi Data Stores Applications in Cloud EnvironmentsVigneshInfotechNoch keine Bewertungen
- System DesignDokument6 SeitenSystem DesignVigneshInfotechNoch keine Bewertungen
- SS Lab ManualDokument38 SeitenSS Lab ManualRagib R Shariff 4MC19CS115Noch keine Bewertungen
- PenPoint Development Tools June 1992Dokument314 SeitenPenPoint Development Tools June 1992pablo_marxNoch keine Bewertungen
- Thermal Overload ProtectorDokument69 SeitenThermal Overload ProtectorSai Printers100% (1)
- Intel SGX SDK Developer Reference Linux 1.9 Open SourceDokument320 SeitenIntel SGX SDK Developer Reference Linux 1.9 Open SourceliveshellNoch keine Bewertungen
- Project Title: Wireless Power Transmission Using Tesla Coil AbstractDokument5 SeitenProject Title: Wireless Power Transmission Using Tesla Coil AbstractKalyan Reddy AnuguNoch keine Bewertungen
- Chapter-8 FET AmplifiersDokument29 SeitenChapter-8 FET AmplifiersFranklin Rey PacquiaoNoch keine Bewertungen
- Assignment Report: Simple Operating SystemDokument24 SeitenAssignment Report: Simple Operating SystemNguyen Trong Tin50% (2)
- Mobatime: NMS Overview and DSS OverviewDokument21 SeitenMobatime: NMS Overview and DSS OverviewShanavasNoch keine Bewertungen
- Contents in Detail: Foreword by HD Moore Xiii Preface Xvii Acknowledgments XixDokument6 SeitenContents in Detail: Foreword by HD Moore Xiii Preface Xvii Acknowledgments XixLeandro Dias BarataNoch keine Bewertungen
- Transformer Sheet DR RefaatDokument19 SeitenTransformer Sheet DR Refaatمحمد عليNoch keine Bewertungen
- 2013 Course Structure BTech CSEDokument32 Seiten2013 Course Structure BTech CSEMankush JainNoch keine Bewertungen
- System Tools and Documentation TechniquesDokument4 SeitenSystem Tools and Documentation TechniquesVenice DatoNoch keine Bewertungen
- Asus N73SvDokument95 SeitenAsus N73SvtusharNoch keine Bewertungen
- BEEIE - Unit 4 & 5 Question BankDokument7 SeitenBEEIE - Unit 4 & 5 Question Banksachin barathNoch keine Bewertungen
- 1) Two Vectors A, B Are Orthogonal IfDokument9 Seiten1) Two Vectors A, B Are Orthogonal IfRamesh MallaiNoch keine Bewertungen
- A System For Speed and Torque Control of DC Motors With Application To Small Snake RobotsDokument6 SeitenA System For Speed and Torque Control of DC Motors With Application To Small Snake RobotsASOCIACION ATECUBONoch keine Bewertungen
- SDIO SDmode ControllerDokument4 SeitenSDIO SDmode ControllerDinh Hoang TungNoch keine Bewertungen
- Cisco by Test-King: Number: 500-260 Passing Score: 800 Time Limit: 120 Min File Version: 14.0Dokument24 SeitenCisco by Test-King: Number: 500-260 Passing Score: 800 Time Limit: 120 Min File Version: 14.0Ehsan GilaniNoch keine Bewertungen
- Compare Processor Specifications - AMDDokument2 SeitenCompare Processor Specifications - AMDVenkateshwar Reddy KasturiNoch keine Bewertungen
- Pro Palette 5.x ManualDokument291 SeitenPro Palette 5.x ManualObilor Uchechukwu SamuelNoch keine Bewertungen
- Computer Graphics Master ThesisDokument8 SeitenComputer Graphics Master Thesisjuliegonzalezpaterson100% (2)
- Function OverloadingDokument15 SeitenFunction OverloadingSEEMADEVAKSATHA DNoch keine Bewertungen
- Neha Singh Mobile: +91 6360945380 Career Objectives:: Automation Testing SkillsDokument5 SeitenNeha Singh Mobile: +91 6360945380 Career Objectives:: Automation Testing SkillskashviNoch keine Bewertungen
- ProxySG SWG Initial Configuration GuideDokument220 SeitenProxySG SWG Initial Configuration GuideDhananjai SinghNoch keine Bewertungen
- AI-100 OriginalDokument112 SeitenAI-100 OriginalSagnik ChatterjeeNoch keine Bewertungen