Das könnte Ihnen auch gefallen
- Sensory Interventions - Literature ReviewDokument26 SeitenSensory Interventions - Literature Reviewapi-446507356Noch keine Bewertungen
- Btec HN Computing l4 Pearson Set Release 2023 2024 PDFDokument12 SeitenBtec HN Computing l4 Pearson Set Release 2023 2024 PDFMarium BhalaNoch keine Bewertungen
- GIS Theory PDFDokument13 SeitenGIS Theory PDFFrancisco J Contreras MNoch keine Bewertungen
- 4 Key Aspects To VariographyDokument14 Seiten4 Key Aspects To Variographysupri100% (2)
- RegressionAnalysisTutorial ArcGIS10Dokument24 SeitenRegressionAnalysisTutorial ArcGIS10ConkNoch keine Bewertungen
- Administration and ManagementDokument71 SeitenAdministration and Managementsneha dutta100% (1)
- Inquiries Midterm ExamDokument2 SeitenInquiries Midterm ExamMarkmarilyn100% (1)
- Test 07Dokument17 SeitenTest 07Dolly RizaldoNoch keine Bewertungen
- Lesson 1 Introduction To Educational ResearchDokument65 SeitenLesson 1 Introduction To Educational ResearchJoyleen Grace DulnuanNoch keine Bewertungen
- Esse 3600Dokument15 SeitenEsse 3600api-324911878100% (1)
- Assignment CartoDokument26 SeitenAssignment CartoAfiq Munchyz100% (1)
- LabreportDokument13 SeitenLabreportapi-275616442Noch keine Bewertungen
- ADB Assignment 3 SolutionsDokument23 SeitenADB Assignment 3 SolutionsAvudaiappan SNoch keine Bewertungen
- Mapping and Geographic Information Systems (GIS) : What Is GIS?Dokument4 SeitenMapping and Geographic Information Systems (GIS) : What Is GIS?pradeep krNoch keine Bewertungen
- "Gis A Job": What Use Geographical Information Systems in Spatial Economics?Dokument20 Seiten"Gis A Job": What Use Geographical Information Systems in Spatial Economics?Carolina Correa CaroNoch keine Bewertungen
- 2 Mid Semester Exam PaperDokument13 Seiten2 Mid Semester Exam PaperMadhu TanniruNoch keine Bewertungen
- Interpreting Remote Sensing Data: K. Dalsted and L. QueenDokument4 SeitenInterpreting Remote Sensing Data: K. Dalsted and L. QueenrsmxinguNoch keine Bewertungen
- DIVA-GIS - Exercise 1 Distribution and Diversity of Wild PotatoesDokument9 SeitenDIVA-GIS - Exercise 1 Distribution and Diversity of Wild PotatoesAlex AlanezNoch keine Bewertungen
- Williams S Lesson7Dokument12 SeitenWilliams S Lesson7api-276783092Noch keine Bewertungen
- Assignment 1Dokument11 SeitenAssignment 1msnavi65Noch keine Bewertungen
- Spatial Interpolation - PerdinanDokument16 SeitenSpatial Interpolation - PerdinanRian Gampang Di MengertiNoch keine Bewertungen
- Avex 1Dokument2 SeitenAvex 1sdrweshNoch keine Bewertungen
- Image Analysis and Classification Techniques Using ArcGIS 10Dokument16 SeitenImage Analysis and Classification Techniques Using ArcGIS 10greenakses100% (1)
- Scale: It Is Common To Make A Distinction Between Thematic and Topographic MapsDokument4 SeitenScale: It Is Common To Make A Distinction Between Thematic and Topographic MapsParth NakhaleNoch keine Bewertungen
- We Selected Training Sample Points From Individual Land Use Types Proportional To Their Respective Total Parcel Numbers Instead of Total Parcel AreasDokument2 SeitenWe Selected Training Sample Points From Individual Land Use Types Proportional To Their Respective Total Parcel Numbers Instead of Total Parcel AreasSuryadiXiiTkjbNoch keine Bewertungen
- GIS and Economics WebDokument5 SeitenGIS and Economics WebgenosaphNoch keine Bewertungen
- Introduction To GISDokument2 SeitenIntroduction To GISgg_erz9274Noch keine Bewertungen
- Web GIS 4Dokument34 SeitenWeb GIS 4drzubairulislamNoch keine Bewertungen
- National Center For Geographic Information and Analysis: by Yuemin Ding and A. Stewart FotheringhamDokument23 SeitenNational Center For Geographic Information and Analysis: by Yuemin Ding and A. Stewart FotheringhamSudharsananPRSNoch keine Bewertungen
- Theoretical BackgroundDokument19 SeitenTheoretical BackgroundsultanNoch keine Bewertungen
- Geostatistical AnálisisDokument105 SeitenGeostatistical AnálisisPaloma PozoNoch keine Bewertungen
- Spatial Data Analysis - RajuDokument24 SeitenSpatial Data Analysis - RajusonjascribdNoch keine Bewertungen
- Assessing The Uncertainty Resulting From Geoprocessing OperationsDokument22 SeitenAssessing The Uncertainty Resulting From Geoprocessing OperationsSiva RamNoch keine Bewertungen
- Introduction To Modeling Spatial Processes Using Geostatistical AnalystDokument27 SeitenIntroduction To Modeling Spatial Processes Using Geostatistical AnalystDavid Huamani UrpeNoch keine Bewertungen
- Land Change Modeler ArcGIS Software BrochureDokument6 SeitenLand Change Modeler ArcGIS Software BrochureFabio Leonel Casco GutierrezNoch keine Bewertungen
- Sony - Over All Idea About GISDokument17 SeitenSony - Over All Idea About GISDEEPAK KUMAR MALLICKNoch keine Bewertungen
- IEQ-05 Geographic Information Systems NotesDokument16 SeitenIEQ-05 Geographic Information Systems NotesIshani GuptaNoch keine Bewertungen
- Lec51 GIS and GPSDokument20 SeitenLec51 GIS and GPSDIBINoch keine Bewertungen
- Unit III GisDokument69 SeitenUnit III GispraveenbabuNoch keine Bewertungen
- Lab2 Land SuitabilitykDokument9 SeitenLab2 Land SuitabilitykilyaizuraNoch keine Bewertungen
- Article Spie FinalDokument9 SeitenArticle Spie FinalMourad KhelifaNoch keine Bewertungen
- Session 1: Understanding Functions of GIS: 3.1 Why Use GIS? 3.1.1 Improve Organizational IntegrationDokument7 SeitenSession 1: Understanding Functions of GIS: 3.1 Why Use GIS? 3.1.1 Improve Organizational IntegrationZani ZaniNoch keine Bewertungen
- 07 Ras5.FunctionsDokument8 Seiten07 Ras5.FunctionsJames LeeNoch keine Bewertungen
- Genetic Landscapes GISDokument21 SeitenGenetic Landscapes GISjuanNoch keine Bewertungen
- Classification (Unit3)Dokument11 SeitenClassification (Unit3)Bijaya DhamiNoch keine Bewertungen
- Report On ArcMapDokument25 SeitenReport On ArcMapYogesh BillaNoch keine Bewertungen
- Using Spatial Statistics in GISDokument6 SeitenUsing Spatial Statistics in GISErwin AnshariNoch keine Bewertungen
- Urban Morphology of Unplanned Settlements: The Use of Spatial Metrics in VHR Remotely Sensed ImagesDokument6 SeitenUrban Morphology of Unplanned Settlements: The Use of Spatial Metrics in VHR Remotely Sensed ImagesKaro ZempoaltecaNoch keine Bewertungen
- Double-Line Representation) - Figure 3.6.1 Shows The Three Options. Which of These Is UsedDokument26 SeitenDouble-Line Representation) - Figure 3.6.1 Shows The Three Options. Which of These Is UsedXaynoy VilaxayNoch keine Bewertungen
- A.1 .. Spatial Statistics in Arcgis: Lauren M. Scott and Mark V. JanikasDokument15 SeitenA.1 .. Spatial Statistics in Arcgis: Lauren M. Scott and Mark V. JanikasFachri FaisalNoch keine Bewertungen
- Image Histogram: Unveiling Visual Insights, Exploring the Depths of Image Histograms in Computer VisionVon EverandImage Histogram: Unveiling Visual Insights, Exploring the Depths of Image Histograms in Computer VisionNoch keine Bewertungen
- A Linear Programming-Based Framework For Handling Missing Data in Multi-Granular Data WarehousesDokument43 SeitenA Linear Programming-Based Framework For Handling Missing Data in Multi-Granular Data WarehousesJenny CastilloNoch keine Bewertungen
- What Is GIS?: Why Geography?Dokument17 SeitenWhat Is GIS?: Why Geography?tvijayarajaNoch keine Bewertungen
- Decision Tree Approaches For Zero-Inflated Count Data: Seong-Keon Lee & Seohoon JinDokument15 SeitenDecision Tree Approaches For Zero-Inflated Count Data: Seong-Keon Lee & Seohoon JinAlex Miller100% (1)
- Quantative Mapping - (D) MAPPING ENUMERATION AND OTHER AREALLY AGGREGATED DATA - THE CHOROPLETH MAPDokument10 SeitenQuantative Mapping - (D) MAPPING ENUMERATION AND OTHER AREALLY AGGREGATED DATA - THE CHOROPLETH MAPIan MurimiNoch keine Bewertungen
- Ags Getting To KnowDokument16 SeitenAgs Getting To KnowJordán LópezNoch keine Bewertungen
- Bayesian Statistics For Small Area EstimationDokument36 SeitenBayesian Statistics For Small Area Estimationhasniii babaNoch keine Bewertungen
- GIS & RS Modified NotesDokument49 SeitenGIS & RS Modified NotesEMMANUEL GONESENoch keine Bewertungen
- Region Growing in GIS, An Application For Landscape Character AssessmentDokument7 SeitenRegion Growing in GIS, An Application For Landscape Character Assessmentkeer_thiNoch keine Bewertungen
- GIS - 06: SPATIAL ANALYSIS (1) - Overlay Operations &Dokument26 SeitenGIS - 06: SPATIAL ANALYSIS (1) - Overlay Operations &Anitha MuruganNoch keine Bewertungen
- 1-Political MapsDokument14 Seiten1-Political MapsaulaNoch keine Bewertungen
- Unit I Fundamentals of GisDokument15 SeitenUnit I Fundamentals of GismadhuNoch keine Bewertungen
- Regionalisation As Spatial Data Mining Problem: A Comparative StudyDokument4 SeitenRegionalisation As Spatial Data Mining Problem: A Comparative Studysurendiran123Noch keine Bewertungen
- Spatial Analysis Along Networks: Statistical and Computational MethodsVon EverandSpatial Analysis Along Networks: Statistical and Computational MethodsNoch keine Bewertungen
- Cancun ArimaDokument10 SeitenCancun ArimazaforNoch keine Bewertungen
- Time Series Analysis Matlab Tutorial: Joachim GrossDokument39 SeitenTime Series Analysis Matlab Tutorial: Joachim GrosszaforNoch keine Bewertungen
- Timeseries 586Dokument56 SeitenTimeseries 586zaforNoch keine Bewertungen
- Spatial Analysis PrimerDokument30 SeitenSpatial Analysis PrimerkalladyNoch keine Bewertungen
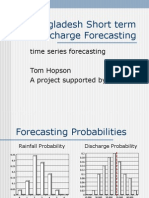
- Characterizing Rainfall Trend in Bangladesh by Temporal Statistics AnalysisDokument9 SeitenCharacterizing Rainfall Trend in Bangladesh by Temporal Statistics AnalysiszaforNoch keine Bewertungen
- 254 Statistical Modeling of Space-Time RainfallDokument18 Seiten254 Statistical Modeling of Space-Time RainfallzaforNoch keine Bewertungen
- ADF NotesDokument2 SeitenADF NotesHassan HasanNoch keine Bewertungen
- BW Doodling MarkovDokument7 SeitenBW Doodling MarkovzaforNoch keine Bewertungen
- Ajassp 2013 1172 1180 PDFDokument9 SeitenAjassp 2013 1172 1180 PDFzaforNoch keine Bewertungen
- BW Doodling MarkovDokument7 SeitenBW Doodling MarkovzaforNoch keine Bewertungen
- GisDokument4 SeitenGiszaforNoch keine Bewertungen
- Lump Semi SelectDokument12 SeitenLump Semi SelectzaforNoch keine Bewertungen
- History of Census Taking in Maldives: by Mr. Ibrahim Naseem & Mr. Ahmed NihadDokument11 SeitenHistory of Census Taking in Maldives: by Mr. Ibrahim Naseem & Mr. Ahmed NihadHamza ZainNoch keine Bewertungen
- Literature Review: Prof M. Sandada 0772363753 Msandada@uzbusinessschool - Uz.ac - ZW Uzbusiness School Office No. 7Dokument12 SeitenLiterature Review: Prof M. Sandada 0772363753 Msandada@uzbusinessschool - Uz.ac - ZW Uzbusiness School Office No. 7Tinotenda FredNoch keine Bewertungen
- The Percentage Oil Content, P, and The Weight, W Milligrams, of Each of 10 RandomlyDokument17 SeitenThe Percentage Oil Content, P, and The Weight, W Milligrams, of Each of 10 RandomlyHalal BoiNoch keine Bewertungen
- Carib I.A SampleDokument31 SeitenCarib I.A SampleCurtleyVigilant-MercenaryThompson50% (2)
- Fundamentals of Mathematics-I TheoryDokument36 SeitenFundamentals of Mathematics-I TheoryTanmay KhandelwalNoch keine Bewertungen
- Apj Abdul KalamDokument16 SeitenApj Abdul Kalamamanblr12100% (2)
- ABC-MAR014-11-New Life For Old Masonry Arch BridgesDokument12 SeitenABC-MAR014-11-New Life For Old Masonry Arch BridgesNestor Ricardo OrtegaNoch keine Bewertungen
- Syllabus All Courses 3Dokument69 SeitenSyllabus All Courses 3Andrea Mae QuiniquiniNoch keine Bewertungen
- Q4 Week 4-5 INQUIRIES, INVESTIGATIONS, IMMERSIONDokument9 SeitenQ4 Week 4-5 INQUIRIES, INVESTIGATIONS, IMMERSIONPricess LingadNoch keine Bewertungen
- FDA 483 Form PDFDokument2 SeitenFDA 483 Form PDFHollyNoch keine Bewertungen
- 1 s2.0 S0747563222003181 MainDokument11 Seiten1 s2.0 S0747563222003181 Maintrongmanh.travelgroupNoch keine Bewertungen
- NI LUH 2021 Company Value Profitability ROADokument11 SeitenNI LUH 2021 Company Value Profitability ROAFitra Ramadhana AsfriantoNoch keine Bewertungen
- Akash Market Survey ReportDokument79 SeitenAkash Market Survey Reportkushi_ali2000Noch keine Bewertungen
- Chapter 1 Fundamental Concepts SPSS - Descriptive StatisticsDokument4 SeitenChapter 1 Fundamental Concepts SPSS - Descriptive StatisticsAvinash AmbatiNoch keine Bewertungen
- John M. Sullivan - Sphere Eversions: From Smale Through "The Optiverse"Dokument12 SeitenJohn M. Sullivan - Sphere Eversions: From Smale Through "The Optiverse"GremnDLNoch keine Bewertungen
- Demis - Commented1Dokument34 SeitenDemis - Commented1demistesfawNoch keine Bewertungen
- 35 - 2WCSCDokument1 Seite35 - 2WCSCCristianLopezNoch keine Bewertungen
- Correlation Between Student'S Vocabulary Mastery and Speaking SkillDokument12 SeitenCorrelation Between Student'S Vocabulary Mastery and Speaking SkillMinh ThươngNoch keine Bewertungen
- Literature Review On E-Commerce WebsiteDokument8 SeitenLiterature Review On E-Commerce Websiteafmzsbdlmlddog100% (1)
- For DissertationDokument13 SeitenFor DissertationRegi viniciyaNoch keine Bewertungen
- Chapter 06 PDFDokument18 SeitenChapter 06 PDFMonicaFrensiaMegaFisheraNoch keine Bewertungen
- R Letter PDFDokument2 SeitenR Letter PDFYasith WeerasingheNoch keine Bewertungen
- University of Eswatini: Department of Statistics and Demography Assignment 1Dokument6 SeitenUniversity of Eswatini: Department of Statistics and Demography Assignment 1Themba MdlaloseNoch keine Bewertungen
- QsenDokument7 SeitenQsendancehallstarraNoch keine Bewertungen