Das könnte Ihnen auch gefallen
- Getting Started with Big Data Query using Apache ImpalaVon EverandGetting Started with Big Data Query using Apache ImpalaNoch keine Bewertungen
- Cloud Integration A Complete Guide - 2019 EditionVon EverandCloud Integration A Complete Guide - 2019 EditionBewertung: 5 von 5 Sternen5/5 (1)
- ETL Testing ConceptsDokument4 SeitenETL Testing Conceptspoornananda saiNoch keine Bewertungen
- Application Support A Complete Guide - 2019 EditionVon EverandApplication Support A Complete Guide - 2019 EditionNoch keine Bewertungen
- Vishnu Datastage ResumeDokument3 SeitenVishnu Datastage ResumeVijay VardhanNoch keine Bewertungen
- Data Validity TestingDokument9 SeitenData Validity TestingumaannamalaiNoch keine Bewertungen
- Pro Oracle SQL Development: Best Practices for Writing Advanced QueriesVon EverandPro Oracle SQL Development: Best Practices for Writing Advanced QueriesNoch keine Bewertungen
- Vulnerability database The Ultimate Step-By-Step GuideVon EverandVulnerability database The Ultimate Step-By-Step GuideNoch keine Bewertungen
- No SQL Database CompiledDokument20 SeitenNo SQL Database CompiledSteffin JosephNoch keine Bewertungen
- Generic Pipelines Using Docker: The DevOps Guide to Building Reusable, Platform Agnostic CI/CD FrameworksVon EverandGeneric Pipelines Using Docker: The DevOps Guide to Building Reusable, Platform Agnostic CI/CD FrameworksNoch keine Bewertungen
- Introducing Maven: A Build Tool for Today's Java DevelopersVon EverandIntroducing Maven: A Build Tool for Today's Java DevelopersNoch keine Bewertungen
- Cloud Application Discovery The Ultimate Step-By-Step GuideVon EverandCloud Application Discovery The Ultimate Step-By-Step GuideNoch keine Bewertungen
- GraphSQL - Sharing Data in A Microservices Architecture Using GraphQLDokument9 SeitenGraphSQL - Sharing Data in A Microservices Architecture Using GraphQLfunkytacoNoch keine Bewertungen
- Comparative Case Study Difference Between Azure Cloud SQL and Atlas MongoDB NoSQL DatabaseDokument4 SeitenComparative Case Study Difference Between Azure Cloud SQL and Atlas MongoDB NoSQL DatabaseWARSE JournalsNoch keine Bewertungen
- Python Continuous Integration and Delivery: A Concise Guide with ExamplesVon EverandPython Continuous Integration and Delivery: A Concise Guide with ExamplesNoch keine Bewertungen
- IBM WebSphere DataStage Basic Reference Guide Version 8Dokument547 SeitenIBM WebSphere DataStage Basic Reference Guide Version 8ALTernativoNoch keine Bewertungen
- IBM InfoSphere Replication Server and Data Event PublisherVon EverandIBM InfoSphere Replication Server and Data Event PublisherNoch keine Bewertungen
- Understanding Azure Monitoring: Includes IaaS and PaaS ScenariosVon EverandUnderstanding Azure Monitoring: Includes IaaS and PaaS ScenariosNoch keine Bewertungen
- Creating Development Environments with Vagrant - Second EditionVon EverandCreating Development Environments with Vagrant - Second EditionNoch keine Bewertungen
- Data Lake Architecture Strategy A Complete Guide - 2021 EditionVon EverandData Lake Architecture Strategy A Complete Guide - 2021 EditionNoch keine Bewertungen
- Modern Web Applications with Next.JS: Learn Advanced Techniques to Build and Deploy Modern, Scalable and Production Ready React Applications with Next.JSVon EverandModern Web Applications with Next.JS: Learn Advanced Techniques to Build and Deploy Modern, Scalable and Production Ready React Applications with Next.JSNoch keine Bewertungen
- Software Product Managers A Complete Guide - 2020 EditionVon EverandSoftware Product Managers A Complete Guide - 2020 EditionNoch keine Bewertungen
- Tableau Performance Optimization Flow Chart 2020Dokument3 SeitenTableau Performance Optimization Flow Chart 2020Samaksh KumarNoch keine Bewertungen
- Terraform for Developers: Essentials of Infrastructure Automation and ProvisioningVon EverandTerraform for Developers: Essentials of Infrastructure Automation and ProvisioningNoch keine Bewertungen
- Observability Services A Complete Guide - 2019 EditionVon EverandObservability Services A Complete Guide - 2019 EditionNoch keine Bewertungen
- Cloud Computing Security A Complete Guide - 2021 EditionVon EverandCloud Computing Security A Complete Guide - 2021 EditionNoch keine Bewertungen
- Introduction to Reliable and Secure Distributed ProgrammingVon EverandIntroduction to Reliable and Secure Distributed ProgrammingNoch keine Bewertungen
- Hadoop Training in HyderabadDokument6 SeitenHadoop Training in Hyderabadsoftware instituteNoch keine Bewertungen
- A Tamil Grammar For School UseDokument244 SeitenA Tamil Grammar For School UseIreneoNoch keine Bewertungen
- Data Science Solutions on Azure: Tools and Techniques Using Databricks and MLOpsVon EverandData Science Solutions on Azure: Tools and Techniques Using Databricks and MLOpsNoch keine Bewertungen
- Domain Driven Design ExamDokument29 SeitenDomain Driven Design ExamEr Himanshu VermaNoch keine Bewertungen
- Datastage To Run SAS CodeDokument66 SeitenDatastage To Run SAS Codejbk1110% (1)
- Unix QuestionsDokument7 SeitenUnix QuestionsKushal Sen LaskarNoch keine Bewertungen
- SQL Server QuestionsDokument223 SeitenSQL Server Questionsjbk111100% (1)
- SQL Server QuestionsDokument223 SeitenSQL Server Questionsjbk111Noch keine Bewertungen
- SQL Server QuestionsDokument35 SeitenSQL Server Questionsjbk111Noch keine Bewertungen
- Short Answers 2nd Year PDFDokument20 SeitenShort Answers 2nd Year PDFMairan AnjumNoch keine Bewertungen
- Teco Ma7200 2 PDFDokument209 SeitenTeco Ma7200 2 PDFDung LeNoch keine Bewertungen
- L&T PresentationDokument124 SeitenL&T Presentationrajib ranjan panda100% (1)
- Resimold Resiglas CRT DryType CommercialBrochure enDokument12 SeitenResimold Resiglas CRT DryType CommercialBrochure engreyllom9791Noch keine Bewertungen
- Rancang Bangun Prototipe Sistem Kendali Iron Removal Filter (Irf) Pada Unit Pengolahan Air Bersih Berbasis PLCDokument8 SeitenRancang Bangun Prototipe Sistem Kendali Iron Removal Filter (Irf) Pada Unit Pengolahan Air Bersih Berbasis PLCaulyaakmala24Noch keine Bewertungen
- Laboratory: Generation of Am SignalsDokument25 SeitenLaboratory: Generation of Am SignalsTun ShukorNoch keine Bewertungen
- Grundig Classic 960 MANUALDokument15 SeitenGrundig Classic 960 MANUALjuanp1020Noch keine Bewertungen
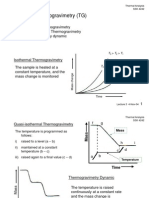
- Thermogravimetry (TG) : 1. Isothermal Thermogravimetry 2. Quasi-Isothermal Thermogravimetry 3. Thermogravimetry DynamicDokument19 SeitenThermogravimetry (TG) : 1. Isothermal Thermogravimetry 2. Quasi-Isothermal Thermogravimetry 3. Thermogravimetry DynamicZUL KAMARUDDIN100% (1)
- Samsung Un24h4000af Un24h4000afxza Manual de UsuarioDokument3 SeitenSamsung Un24h4000af Un24h4000afxza Manual de UsuarioSaid Raúl Macías GonzálezNoch keine Bewertungen
- Arduino Mega PinoutDokument1 SeiteArduino Mega PinoutGlauco Aguiar100% (1)
- EC6303 - Linear Integrated Circuits and Applications NotesDokument132 SeitenEC6303 - Linear Integrated Circuits and Applications NotesbrsreddyNoch keine Bewertungen
- Module 1 - Advanced Computer ArchitectureDokument15 SeitenModule 1 - Advanced Computer ArchitectureDream CatcherNoch keine Bewertungen
- Smart Office Automation SystemDokument6 SeitenSmart Office Automation SystemInternational Journal of Application or Innovation in Engineering & Management100% (1)
- Mplab IDE TutorialDokument12 SeitenMplab IDE Tutorialahsoopk100% (1)
- Bloom QuestionsDokument270 SeitenBloom QuestionsrameshsmeNoch keine Bewertungen
- Carlisle Wire Cable Guide 2011 PDFDokument24 SeitenCarlisle Wire Cable Guide 2011 PDFnizarfebNoch keine Bewertungen
- Support ProfessionalDokument2 SeitenSupport ProfessionalscriNoch keine Bewertungen
- 3281 enDokument28 Seiten3281 enJafarShojaNoch keine Bewertungen
- Flow Control ValvesDokument2 SeitenFlow Control ValvesAnik FaisalNoch keine Bewertungen
- Abs EdgeDokument39 SeitenAbs Edgecorporacion corprosinfro100% (3)
- Indesit Idce745euDokument13 SeitenIndesit Idce745euMилош ЛукићNoch keine Bewertungen
- Quiescent Current DrainDokument5 SeitenQuiescent Current DrainCmj LennonNoch keine Bewertungen
- Lab LCDDokument6 SeitenLab LCDJesus Cotrina100% (1)
- LG C148MDokument5 SeitenLG C148Mlondon335Noch keine Bewertungen
- MODULE 3 Optical Sources 1Dokument55 SeitenMODULE 3 Optical Sources 1Yashavantha K MNoch keine Bewertungen
- Less or Nonflammable Liquid Insulated TransformersDokument21 SeitenLess or Nonflammable Liquid Insulated TransformersTosikur RahmanNoch keine Bewertungen
- Light-Emitting DiodeDokument28 SeitenLight-Emitting DiodebinukirubaNoch keine Bewertungen
- How Did Bill Gates and Steve Jobs Differ in Their Leadership StyleDokument4 SeitenHow Did Bill Gates and Steve Jobs Differ in Their Leadership StyleDip Kumar Dey67% (9)
- Motors and The NECDokument10 SeitenMotors and The NECMike AdvinculaNoch keine Bewertungen
- Okaya SMF Battery FlyerDokument2 SeitenOkaya SMF Battery FlyerSteevan NelsonNoch keine Bewertungen