Das könnte Ihnen auch gefallen
- An Introduction to Mathematical Analysis for Economic Theory and EconometricsVon EverandAn Introduction to Mathematical Analysis for Economic Theory and EconometricsNoch keine Bewertungen
- A Energy Price ProcessesDokument5 SeitenA Energy Price ProcessesEmily7959Noch keine Bewertungen
- CAPMDokument34 SeitenCAPMadityav_13100% (1)
- A Merton Model Approach To Assessing The Default Risk of UK Public Companies PDFDokument18 SeitenA Merton Model Approach To Assessing The Default Risk of UK Public Companies PDFAndri WibowoNoch keine Bewertungen
- PJM ARR and FTR MarketDokument159 SeitenPJM ARR and FTR MarketfwlwllwNoch keine Bewertungen
- Ipo UnderpricingDokument13 SeitenIpo Underpricingshivams18Noch keine Bewertungen
- Table of Contents - LatestDokument5 SeitenTable of Contents - LatestGaurav ManglaNoch keine Bewertungen
- A Practical ImplementationOfHJMDokument336 SeitenA Practical ImplementationOfHJMTom WuNoch keine Bewertungen
- IEOR E4630 Spring 2016 SyllabusDokument2 SeitenIEOR E4630 Spring 2016 Syllabuscef4Noch keine Bewertungen
- The Basic New Keynesian Model: Josef StráskýDokument29 SeitenThe Basic New Keynesian Model: Josef StráskýTiago MatosNoch keine Bewertungen
- Two Stage Fama MacbethDokument5 SeitenTwo Stage Fama Macbethkty21joy100% (1)
- Udemy Python Financial Analysis SlidesDokument35 SeitenUdemy Python Financial Analysis SlidesWang ShenghaoNoch keine Bewertungen
- Interest Rate Modelling Piterbarg Table of ContentsDokument23 SeitenInterest Rate Modelling Piterbarg Table of ContentsKranthi Kiran50% (2)
- AttilioMeucci BeyondBlackLittermanDokument10 SeitenAttilioMeucci BeyondBlackLittermanRichard LindseyNoch keine Bewertungen
- BLK Risk Factor Investing Revealed PDFDokument8 SeitenBLK Risk Factor Investing Revealed PDFShaun RodriguezNoch keine Bewertungen
- Creditrisk Plus PDFDokument72 SeitenCreditrisk Plus PDFNayeline CastilloNoch keine Bewertungen
- Markov Switching Model ToolDokument39 SeitenMarkov Switching Model ToolcristianmondacaNoch keine Bewertungen
- HD - Machine Learnind and EconometricsDokument185 SeitenHD - Machine Learnind and EconometricsFaustinNoch keine Bewertungen
- Handbook of Volatility Models and Their ApplicationsVon EverandHandbook of Volatility Models and Their ApplicationsBewertung: 4.5 von 5 Sternen4.5/5 (2)
- Econometric Models For Oil PriceDokument16 SeitenEconometric Models For Oil PricedanonninoNoch keine Bewertungen
- Statistical Cost AccountingDokument20 SeitenStatistical Cost AccountingBirat Sharma100% (1)
- Flow Chart For Quant StrategiesDokument1 SeiteFlow Chart For Quant StrategiesKaustubh KeskarNoch keine Bewertungen
- (Springer Finance) Dr. Manuel Ammann (Auth.) - Credit Risk Valuation - Methods, Models, and Applications-Springer Berlin Heidelberg (2001)Dokument258 Seiten(Springer Finance) Dr. Manuel Ammann (Auth.) - Credit Risk Valuation - Methods, Models, and Applications-Springer Berlin Heidelberg (2001)Amel AmarNoch keine Bewertungen
- GARCH Models in Python 1Dokument31 SeitenGARCH Models in Python 1visNoch keine Bewertungen
- Noncooperative Approaches to the Theory of Perfect CompetitionVon EverandNoncooperative Approaches to the Theory of Perfect CompetitionBewertung: 5 von 5 Sternen5/5 (1)
- Stolyarov MFE Study Guide PDFDokument279 SeitenStolyarov MFE Study Guide PDFSachin SomaniNoch keine Bewertungen
- Basic Econometrics (Lectures)Dokument165 SeitenBasic Econometrics (Lectures)Omar FarooqNoch keine Bewertungen
- Derivatives and Risk Management JP Morgan ReportDokument24 SeitenDerivatives and Risk Management JP Morgan Reportanirbanccim8493Noch keine Bewertungen
- Fund of Hedge Funds Portfolio Selection: A Multiple-Objective ApproachDokument35 SeitenFund of Hedge Funds Portfolio Selection: A Multiple-Objective ApproachgimbrinelNoch keine Bewertungen
- Derivatives Pricing Using QuantLib - An IntroductionDokument25 SeitenDerivatives Pricing Using QuantLib - An Introductionvicky.sajnaniNoch keine Bewertungen
- 002 Thakor 1991 Survey Game Theory and FinancesDokument14 Seiten002 Thakor 1991 Survey Game Theory and FinancesIdeas Guarani KaiowaNoch keine Bewertungen
- Lahore University of Management Sciences ECON 330 - EconometricsDokument3 SeitenLahore University of Management Sciences ECON 330 - EconometricsshyasirNoch keine Bewertungen
- Stochastic Differential EquationsDokument105 SeitenStochastic Differential Equationsali.sarirNoch keine Bewertungen
- Kyle Market Microstructure SyllabusDokument7 SeitenKyle Market Microstructure SyllabusssdebNoch keine Bewertungen
- Jeffrey M. Wooldridge-Econometric Analysis of Cross Section and Panel Data, 2nd Edition (2010)Dokument79 SeitenJeffrey M. Wooldridge-Econometric Analysis of Cross Section and Panel Data, 2nd Edition (2010)Luke Sperduto100% (1)
- Monte Carlo Methods in Finance PDFDokument75 SeitenMonte Carlo Methods in Finance PDFHasan SamiNoch keine Bewertungen
- Forecasting Volatility of Stock Indices With ARCH ModelDokument18 SeitenForecasting Volatility of Stock Indices With ARCH Modelravi_nyseNoch keine Bewertungen
- Lecture 1.1 CQF 2010 - BDokument52 SeitenLecture 1.1 CQF 2010 - BGuillaume PosticNoch keine Bewertungen
- Bayesian ModelDokument71 SeitenBayesian ModelkNoch keine Bewertungen
- A Stochastic Model For Order Book DynamiDokument21 SeitenA Stochastic Model For Order Book DynamiAnalyticNoch keine Bewertungen
- Time Series Analysis: Nonstationary and Noninvertible Distribution TheoryVon EverandTime Series Analysis: Nonstationary and Noninvertible Distribution TheoryNoch keine Bewertungen
- Princeton Financial Math PDFDokument46 SeitenPrinceton Financial Math PDF6doitNoch keine Bewertungen
- Multi-Asset Pairs TradingDokument25 SeitenMulti-Asset Pairs TradingHair4meNoch keine Bewertungen
- Pricing A Bermudan Swaption Using The LIBOR Market ModelDokument74 SeitenPricing A Bermudan Swaption Using The LIBOR Market Modelalexis_miaNoch keine Bewertungen
- Macro DynamicsDokument394 SeitenMacro DynamicsMayerxi Araque MorenoNoch keine Bewertungen
- Forecasting Default With The KMV-Merton ModelDokument35 SeitenForecasting Default With The KMV-Merton ModelEdgardo Garcia MartinezNoch keine Bewertungen
- A Tutorial On Principal Component AnalysisDokument29 SeitenA Tutorial On Principal Component AnalysisrigastiNoch keine Bewertungen
- Contributions To Modem EconometricsDokument285 SeitenContributions To Modem Econometricsاحمد صابرNoch keine Bewertungen
- Computational Finance Using MATLABDokument26 SeitenComputational Finance Using MATLABpopoyboysNoch keine Bewertungen
- Introduction Econometrics RDokument48 SeitenIntroduction Econometrics RMayank RawatNoch keine Bewertungen
- Pub - Oligopoly Pricing Old Ideas and New Tools PDFDokument519 SeitenPub - Oligopoly Pricing Old Ideas and New Tools PDFLeonardo SimonciniNoch keine Bewertungen
- Financial Transmission Rights Primer 13 Mar 2009Dokument27 SeitenFinancial Transmission Rights Primer 13 Mar 2009xiaojunmNoch keine Bewertungen
- Interest RatesDokument54 SeitenInterest RatesAmeen ShaikhNoch keine Bewertungen
- Mscfe CRT m2Dokument6 SeitenMscfe CRT m2Manit Ahlawat100% (1)
- J.C.maxwell (1864) - A Dynamical Theory of The Electromagnetic FieldDokument55 SeitenJ.C.maxwell (1864) - A Dynamical Theory of The Electromagnetic FieldBruno Turetto RodriguesNoch keine Bewertungen
- JEVONS, W. S. - Brief Account of A General Mathematical Theory of Political Economy - 1866Dokument8 SeitenJEVONS, W. S. - Brief Account of A General Mathematical Theory of Political Economy - 1866Bruno Turetto RodriguesNoch keine Bewertungen
- JEVONS, W. S. - Brief Account of A General Mathematical Theory of Political Economy - 1866Dokument8 SeitenJEVONS, W. S. - Brief Account of A General Mathematical Theory of Political Economy - 1866Bruno Turetto RodriguesNoch keine Bewertungen
- Rules For Biologically-Inspired Adaptive Network DesignDokument13 SeitenRules For Biologically-Inspired Adaptive Network DesignBruno Turetto RodriguesNoch keine Bewertungen
- Problem Set-02Dokument2 SeitenProblem Set-02linn.pa.pa.khaing.2020.2021.fbNoch keine Bewertungen
- Huawei R4815N1 DatasheetDokument2 SeitenHuawei R4815N1 DatasheetBysNoch keine Bewertungen
- Soft Ground Improvement Using Electro-Osmosis.Dokument6 SeitenSoft Ground Improvement Using Electro-Osmosis.Vincent Ling M SNoch keine Bewertungen
- Lesson PlanDokument2 SeitenLesson Plannicole rigonNoch keine Bewertungen
- Lecturenotes Data MiningDokument23 SeitenLecturenotes Data Miningtanyah LloydNoch keine Bewertungen
- Strucure Design and Multi - Objective Optimization of A Novel NPR Bumber SystemDokument19 SeitenStrucure Design and Multi - Objective Optimization of A Novel NPR Bumber System施元Noch keine Bewertungen
- Floating Oil Skimmer Design Using Rotary Disc MethDokument9 SeitenFloating Oil Skimmer Design Using Rotary Disc MethAhmad YaniNoch keine Bewertungen
- Comparitive Study ICICI & HDFCDokument22 SeitenComparitive Study ICICI & HDFCshah faisal100% (1)
- Hdfs Default XML ParametersDokument14 SeitenHdfs Default XML ParametersVinod BihalNoch keine Bewertungen
- FM 2030Dokument18 SeitenFM 2030renaissancesamNoch keine Bewertungen
- Environmental Economics Pollution Control: Mrinal Kanti DuttaDokument253 SeitenEnvironmental Economics Pollution Control: Mrinal Kanti DuttashubhamNoch keine Bewertungen
- Chemistry Form 4 Daily Lesson Plan - CompressDokument3 SeitenChemistry Form 4 Daily Lesson Plan - Compressadila ramlonNoch keine Bewertungen
- Outdoor Air Pollution: Sources, Health Effects and SolutionsDokument20 SeitenOutdoor Air Pollution: Sources, Health Effects and SolutionsCamelia RadulescuNoch keine Bewertungen
- Obesity - The Health Time Bomb: ©LTPHN 2008Dokument36 SeitenObesity - The Health Time Bomb: ©LTPHN 2008EVA PUTRANTO100% (2)
- Ricoh IM C2000 IM C2500: Full Colour Multi Function PrinterDokument4 SeitenRicoh IM C2000 IM C2500: Full Colour Multi Function PrinterKothapalli ChiranjeeviNoch keine Bewertungen
- Rule 113 114Dokument7 SeitenRule 113 114Shaila GonzalesNoch keine Bewertungen
- Objective & Scope of ProjectDokument8 SeitenObjective & Scope of ProjectPraveen SehgalNoch keine Bewertungen
- Arens - Auditing and Assurance Services 15e-2Dokument17 SeitenArens - Auditing and Assurance Services 15e-2Magdaline ChuaNoch keine Bewertungen
- Mcom Sem 4 Project FinalDokument70 SeitenMcom Sem 4 Project Finallaxmi iyer75% (4)
- PR KehumasanDokument14 SeitenPR KehumasanImamNoch keine Bewertungen
- Homework 1 W13 SolutionDokument5 SeitenHomework 1 W13 SolutionSuzuhara EmiriNoch keine Bewertungen
- Test Your Knowledge - Study Session 1Dokument4 SeitenTest Your Knowledge - Study Session 1My KhanhNoch keine Bewertungen
- ISBN Safe Work Method Statements 2022 03Dokument8 SeitenISBN Safe Work Method Statements 2022 03Tamo Kim ChowNoch keine Bewertungen
- E Flight Journal Aero Special 2018 Small PDFDokument44 SeitenE Flight Journal Aero Special 2018 Small PDFMalburg100% (1)
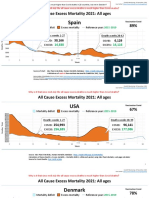
- Countries EXCESS DEATHS All Ages - 15nov2021Dokument21 SeitenCountries EXCESS DEATHS All Ages - 15nov2021robaksNoch keine Bewertungen
- Proceeding of Rasce 2015Dokument245 SeitenProceeding of Rasce 2015Alex ChristopherNoch keine Bewertungen
- Assembler Pass 2Dokument5 SeitenAssembler Pass 2AnuNoch keine Bewertungen
- A Case Study of Coustomer Satisfaction in Demat Account At: A Summer Training ReportDokument110 SeitenA Case Study of Coustomer Satisfaction in Demat Account At: A Summer Training ReportDeepak SinghalNoch keine Bewertungen
- 5c3f1a8b262ec7a Ek PDFDokument5 Seiten5c3f1a8b262ec7a Ek PDFIsmet HizyoluNoch keine Bewertungen
- Movie Piracy in Ethiopian CinemaDokument22 SeitenMovie Piracy in Ethiopian CinemaBehailu Shiferaw MihireteNoch keine Bewertungen