Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- This Datasheet Has Been Downloaded From at ThisDokument3 SeitenThis Datasheet Has Been Downloaded From at ThisEka Puji WidiyantoNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Face DetectDokument22 SeitenFace DetectMuhammad SaqibNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- From Bottom To Top, The Waveforms Show VIN (CH1), VHALF (CH2), and VOUT (CH3)Dokument1 SeiteFrom Bottom To Top, The Waveforms Show VIN (CH1), VHALF (CH2), and VOUT (CH3)Eka Puji WidiyantoNoch keine Bewertungen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- 13668-Figure 1Dokument1 Seite13668-Figure 1Eka Puji WidiyantoNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- User Manual ACR30Dokument13 SeitenUser Manual ACR30Eka Puji WidiyantoNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Avr TutorialDokument111 SeitenAvr Tutoriallabirint10100% (7)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- C++ Reference ManualDokument61 SeitenC++ Reference ManualEka Puji WidiyantoNoch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- DSP IntuitiveDokument4 SeitenDSP IntuitiveEka Puji WidiyantoNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Banker AlgorithmDokument2 SeitenBanker AlgorithmEka Puji WidiyantoNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Zhi Dong Bai, Random Matrix Theory and Its ApplicationsDokument174 SeitenZhi Dong Bai, Random Matrix Theory and Its ApplicationsanthalyaNoch keine Bewertungen
- Chapter 8Dokument8 SeitenChapter 8Aldon JimenezNoch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Cambridge University Chemistry DataBookDokument18 SeitenCambridge University Chemistry DataBookiantocNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Simulation of Signal Constellations ofDokument19 SeitenSimulation of Signal Constellations ofThahsin ThahirNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Alan TuringDokument10 SeitenAlan TuringtomNoch keine Bewertungen
- Amcat Question QUANTITATIVE ABILITY Papers-2. - FresherLine - Jobs, Recruitment, Fresher - FresherlineDokument2 SeitenAmcat Question QUANTITATIVE ABILITY Papers-2. - FresherLine - Jobs, Recruitment, Fresher - FresherlinePrashant Kumar TiwariNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Java Assignment 2Dokument4 SeitenJava Assignment 2Arkoprabho DuttaNoch keine Bewertungen
- Research Methodology & Biostatistics: DR Waqar Ahmed AwanDokument73 SeitenResearch Methodology & Biostatistics: DR Waqar Ahmed AwanWaqar Ahmed AwanNoch keine Bewertungen
- Mathematical Analysis NonRecursive AlgorithmsDokument15 SeitenMathematical Analysis NonRecursive AlgorithmsNIKHIL SOLOMON P URK19CS1045100% (1)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Bergmann1993 PDFDokument22 SeitenBergmann1993 PDFChethan K NarayanNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Chap5C 4pDokument10 SeitenChap5C 4pMingdreamerNoch keine Bewertungen
- Basiccalculus q3 Mod5 Slopeofatangentline FinalDokument32 SeitenBasiccalculus q3 Mod5 Slopeofatangentline FinalMark Allen Labasan100% (2)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Course Syllabus in Math of InvestmentDokument4 SeitenCourse Syllabus in Math of InvestmentGerwil Descallar75% (4)
- Numerology Calculator and Numerology Chart Explained - How To Easily DIY For FreeDokument9 SeitenNumerology Calculator and Numerology Chart Explained - How To Easily DIY For FreeBouck DavidNoch keine Bewertungen
- Runtime Model Checking of Multithreaded C/C++ Programs: Yu Yang Xiaofang Chen Ganesh Gopalakrishnan Robert M. KirbyDokument11 SeitenRuntime Model Checking of Multithreaded C/C++ Programs: Yu Yang Xiaofang Chen Ganesh Gopalakrishnan Robert M. KirbypostscriptNoch keine Bewertungen
- Backpropagation AlgorithmDokument9 SeitenBackpropagation AlgorithmPatel SaikiranNoch keine Bewertungen
- GR 4 Unit 7 Part 1 Measuring Angles Form ADokument4 SeitenGR 4 Unit 7 Part 1 Measuring Angles Form Aapi-280863641Noch keine Bewertungen
- PTFT and Loss PDF 20.06.2017Dokument25 SeitenPTFT and Loss PDF 20.06.2017AnkitNoch keine Bewertungen
- Modu 18 - FaepDokument60 SeitenModu 18 - FaepHAFIDY RIZKY ILHAMSYAHNoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- IB Physics Revision NotesDokument31 SeitenIB Physics Revision NotesBig Long67% (3)
- Rational Numbers: Class VIII. Maths WorksheetDokument3 SeitenRational Numbers: Class VIII. Maths WorksheetThe world Of HarshNoch keine Bewertungen
- Projectile Motion Online LabDokument5 SeitenProjectile Motion Online Labpwbddpq585Noch keine Bewertungen
- Plotting Graphs - MATLAB DocumentationDokument10 SeitenPlotting Graphs - MATLAB DocumentationEr Rachit ShahNoch keine Bewertungen
- ME 489 SyllabusDokument3 SeitenME 489 SyllabusFaraz JamshaidNoch keine Bewertungen
- 6 Differential CalculusDokument35 Seiten6 Differential CalculusPankaj SahuNoch keine Bewertungen
- Planning Analysis Design of Hospital Building Using Staad Prov8iDokument5 SeitenPlanning Analysis Design of Hospital Building Using Staad Prov8ikbkwebsNoch keine Bewertungen
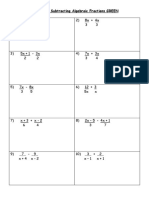
- Algebraic FractionDokument4 SeitenAlgebraic FractionBaiquinda ElzulfaNoch keine Bewertungen
- A7 Cruz ManalastasDokument4 SeitenA7 Cruz ManalastasPatricia CruzNoch keine Bewertungen
- The Mathematics of Graphs: Graphs and Euler CircuitsDokument16 SeitenThe Mathematics of Graphs: Graphs and Euler CircuitsJaybelle Faith ManticahonNoch keine Bewertungen
- Project CrashingDokument10 SeitenProject CrashingShashikumar TheenathayaparanNoch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)