Das könnte Ihnen auch gefallen
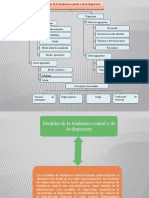
- Unidad 3 - Medidas de Tendencia Central y DispersiónDokument6 SeitenUnidad 3 - Medidas de Tendencia Central y DispersiónIris SánchezNoch keine Bewertungen
- Unidad 3. Medidas de Tendencia Central y DispersionDokument7 SeitenUnidad 3. Medidas de Tendencia Central y DispersionJose Leopoldo SantanaNoch keine Bewertungen
- REPORTE INVESTIGACIÓN SOBRE MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN - PlatasGomezEdwinEduardo - 3D2Dokument28 SeitenREPORTE INVESTIGACIÓN SOBRE MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN - PlatasGomezEdwinEduardo - 3D2Eduardo Platas100% (1)
- Distribución NormalDokument11 SeitenDistribución NormalRicardo MurilloNoch keine Bewertungen
- U1. Estadistica No Parametrica PDFDokument61 SeitenU1. Estadistica No Parametrica PDFRaul Santiago LopezNoch keine Bewertungen
- Unidad 3 y 4Dokument4 SeitenUnidad 3 y 4JessicaNoch keine Bewertungen
- Trabajo de Estadistica II Analisis de Series de Tiempo Vanessa ConchaDokument9 SeitenTrabajo de Estadistica II Analisis de Series de Tiempo Vanessa ConchaVanessa ConchaNoch keine Bewertungen
- Ensayo de VariablesDokument9 SeitenEnsayo de VariablesAngela Malpartida HurtadoNoch keine Bewertungen
- Distribuciones Discretas IIDokument3 SeitenDistribuciones Discretas IIJuan Pablo AranzazuNoch keine Bewertungen
- Medición de VariablesDokument5 SeitenMedición de Variablespipo2992Noch keine Bewertungen
- Unidad 3. Medidas de Tendencia Central y DispersiónDokument5 SeitenUnidad 3. Medidas de Tendencia Central y DispersiónJudith SantanaNoch keine Bewertungen
- U2 Act2 Variabilidad GNPGDokument10 SeitenU2 Act2 Variabilidad GNPGGloria NohemíNoch keine Bewertungen
- Distribución HipergeométricaDokument2 SeitenDistribución HipergeométricaDaniel AvilaNoch keine Bewertungen
- Ritchey Cap. 2 Organización de Los Datos (2008)Dokument21 SeitenRitchey Cap. 2 Organización de Los Datos (2008)Lincoyan Painecura100% (1)
- Desviacion EstandarDokument5 SeitenDesviacion EstandarNemeses MondragonNoch keine Bewertungen
- Caracterizacion de Variables CuantitativasDokument8 SeitenCaracterizacion de Variables CuantitativasJuan Diego Guzmán GuerreroNoch keine Bewertungen
- Trabajo Final Estadistica 2Dokument7 SeitenTrabajo Final Estadistica 2lalaNoch keine Bewertungen
- Odds Ratio - Tabla 2X2Dokument18 SeitenOdds Ratio - Tabla 2X2juan diego100% (1)
- La Distribución NormalDokument45 SeitenLa Distribución NormalTrevor DixonNoch keine Bewertungen
- Desviación Estándar y Error EstandarDokument6 SeitenDesviación Estándar y Error EstandarJosselin Rodriguez TorresNoch keine Bewertungen
- Medidas de Tendencia CentralDokument16 SeitenMedidas de Tendencia CentralestreNoch keine Bewertungen
- Cálculo MuestralDokument4 SeitenCálculo MuestralClaudia Patricia BeltranNoch keine Bewertungen
- Medidas de Tendecia Central y DispersionDokument5 SeitenMedidas de Tendecia Central y DispersionMichelLezcanoNoch keine Bewertungen
- Binominal Poisson y NormalDokument12 SeitenBinominal Poisson y NormalDavid CapachoNoch keine Bewertungen
- 3.medidas de Tendencia Central y DispersiónDokument32 Seiten3.medidas de Tendencia Central y DispersiónInes Elida Carrascal Lopez0% (1)
- Distribucion de La ProbabilidadDokument13 SeitenDistribucion de La ProbabilidadJULIO CESAR RIVERO ANDARANoch keine Bewertungen
- Estadistica No Parametrica Carlos OrtizDokument5 SeitenEstadistica No Parametrica Carlos OrtizCarlos Alfonso Ortiz PereiraNoch keine Bewertungen
- 1 Modelos de Regresion Con Variables Dicotomas 1Dokument13 Seiten1 Modelos de Regresion Con Variables Dicotomas 1Yanel NaderNoch keine Bewertungen
- Estadistica DescriptivaDokument45 SeitenEstadistica DescriptivaAndrea Rivera TabacoNoch keine Bewertungen
- Distribución de La Varianza MuestralDokument3 SeitenDistribución de La Varianza MuestralMaria BautistaNoch keine Bewertungen
- Tipos Variables.Dokument5 SeitenTipos Variables.Alexandra Fernandez100% (1)
- Unidad 2 Medida de Tendencias Central y DispersiónDokument56 SeitenUnidad 2 Medida de Tendencias Central y DispersiónMelanieNoch keine Bewertungen
- Análisis Descriptivo de Datos No AgrupadosDokument12 SeitenAnálisis Descriptivo de Datos No AgrupadosJeisson GarciaNoch keine Bewertungen
- Estimación de ParametrosDokument8 SeitenEstimación de Parametrosmaria contrerasNoch keine Bewertungen
- Prueba de Hipotesis PDFDokument6 SeitenPrueba de Hipotesis PDFAndrea Revilla GarciaNoch keine Bewertungen
- ECONOMETRÍADokument138 SeitenECONOMETRÍAAdolfo Carlos Gutiérrez SosaNoch keine Bewertungen
- Documento Educación Inicial PDFDokument15 SeitenDocumento Educación Inicial PDFPatricia Constanza100% (6)
- Método No ProbabilísticoDokument2 SeitenMétodo No ProbabilísticoLeyton GalloNoch keine Bewertungen
- Actividad 2 Taller de ProbabilidadDokument8 SeitenActividad 2 Taller de ProbabilidadCARLOS ANDRES RAMIREZ CASTILLONoch keine Bewertungen
- Poblacion y Muestra PDFDokument24 SeitenPoblacion y Muestra PDFmaco0% (1)
- Estimacion de ParametrosDokument5 SeitenEstimacion de Parametrosmaria volverasNoch keine Bewertungen
- Fase 4-Discusión ColaborativoDokument32 SeitenFase 4-Discusión ColaborativoAdriana MartinezNoch keine Bewertungen
- Taller 1 Variables Macroeconómicas XDokument7 SeitenTaller 1 Variables Macroeconómicas XJuan Sebastian CUADROS ALFONSONoch keine Bewertungen
- Determinación Del Tamaño de La MuestraDokument10 SeitenDeterminación Del Tamaño de La MuestraLenin Antonio Wade LopezNoch keine Bewertungen
- 6 (Correlación Variables Ordinales Dicotómicas)Dokument14 Seiten6 (Correlación Variables Ordinales Dicotómicas)Syn PrósthesisNoch keine Bewertungen
- Estadistica 2. Distribucion NormalDokument17 SeitenEstadistica 2. Distribucion NormalGabrielNoch keine Bewertungen
- Unidad1 Paso2 Grupo551112 1Dokument51 SeitenUnidad1 Paso2 Grupo551112 1Flor Yadira Moreno GarzonNoch keine Bewertungen
- Variables de Investigación PDFDokument3 SeitenVariables de Investigación PDFMarielsy CarruyoNoch keine Bewertungen
- Pep I Marketing IiDokument7 SeitenPep I Marketing IiFrancisca Sofía Escudero SalgadoNoch keine Bewertungen
- Guía de Trabajo Nº1 Distribucion NormalDokument2 SeitenGuía de Trabajo Nº1 Distribucion NormalCatalina Gangas Moreno0% (1)
- Trabajo Matematica FinancieraDokument24 SeitenTrabajo Matematica FinancieraMAIRA ALEJANDRA DE LA OSSA CASTILLO EstudianteNoch keine Bewertungen
- Análisis y Evaluación de Riesgos en El Puesto Del Bodeguero.231Dokument4 SeitenAnálisis y Evaluación de Riesgos en El Puesto Del Bodeguero.231Alejandra Henao Restrepo100% (1)
- Inferencia Estadistica Quiz 1Dokument5 SeitenInferencia Estadistica Quiz 1yasm212Noch keine Bewertungen
- Trabajo Contextualizado de MacroeconomiaDokument13 SeitenTrabajo Contextualizado de MacroeconomiadeivisNoch keine Bewertungen
- Educacion Ambiental TareaDokument39 SeitenEducacion Ambiental TareaMartín TávaraNoch keine Bewertungen
- Pedagogía para La TransformaciónDokument15 SeitenPedagogía para La Transformaciónheberto1003Noch keine Bewertungen
- Medidas de Tendencia Central para Datos AgrupadosDokument6 SeitenMedidas de Tendencia Central para Datos Agrupadosjose acostaNoch keine Bewertungen
- La Media AritméticaDokument15 SeitenLa Media AritméticaCINTHIA MARLENE GARCIA VERANoch keine Bewertungen
- Medidas de Tendencia CentralDokument8 SeitenMedidas de Tendencia CentralShiruetto ReikNoch keine Bewertungen
- Medidas de Tendencia Central para Series Simples y Datos AgrupadosDokument6 SeitenMedidas de Tendencia Central para Series Simples y Datos AgrupadosAlexander OrdoñezNoch keine Bewertungen
- Procesos, Procedimientos y Control OrganizacionalDokument98 SeitenProcesos, Procedimientos y Control Organizacionalguillermo_ricaldeNoch keine Bewertungen
- 1 TemaDokument4 Seiten1 TemaYadii MartinezNoch keine Bewertungen
- Revisión Bibliográfica Análisis de Políticas Públicas en Proyectos GubernamentalesDokument4 SeitenRevisión Bibliográfica Análisis de Políticas Públicas en Proyectos Gubernamentalesguillermo_ricaldeNoch keine Bewertungen
- Administracion en Enfermeria PDFDokument37 SeitenAdministracion en Enfermeria PDFMarisolCampos50% (2)
- Responsabilidades y Preparación para Las VentasDokument6 SeitenResponsabilidades y Preparación para Las Ventasguillermo_ricaldeNoch keine Bewertungen
- Efectos de La Mejora de La Satisfacción Del PersonalDokument25 SeitenEfectos de La Mejora de La Satisfacción Del Personalguillermo_ricaldeNoch keine Bewertungen
- Artículo Efectos de La Mejora de La Satisfacción Del Personal CorrecciónDokument26 SeitenArtículo Efectos de La Mejora de La Satisfacción Del Personal Correcciónguillermo_ricaldeNoch keine Bewertungen
- Defensa de Tesis Calidad de La Seguridad Del PacienteDokument26 SeitenDefensa de Tesis Calidad de La Seguridad Del Pacienteguillermo_ricaldeNoch keine Bewertungen
- Minería: Dos Décadas. Saqueo y Contubernio en México.Dokument7 SeitenMinería: Dos Décadas. Saqueo y Contubernio en México.guillermo_ricaldeNoch keine Bewertungen
- Papel de La EstadísticaDokument24 SeitenPapel de La Estadísticaguillermo_ricaldeNoch keine Bewertungen
- GBuenfil Cap12 SamuelsonDokument3 SeitenGBuenfil Cap12 Samuelsonguillermo_ricaldeNoch keine Bewertungen
- Directorio Institucional Abr2011nullDokument27 SeitenDirectorio Institucional Abr2011nullguillermo_ricaldeNoch keine Bewertungen
- GBuenfil Gutierrez y GlezDokument3 SeitenGBuenfil Gutierrez y Glezguillermo_ricaldeNoch keine Bewertungen
- Que Es Una IAP For DummiesDokument8 SeitenQue Es Una IAP For Dummiesguillermo_ricaldeNoch keine Bewertungen
- Ejercicio Procesamiento de DatosDokument13 SeitenEjercicio Procesamiento de DatosILSE PAOLA YES MORALESNoch keine Bewertungen
- Guia 5. Test de Hipotesis ParametricasDokument4 SeitenGuia 5. Test de Hipotesis ParametricasJeray Cartes100% (1)
- AC 9. Distribución Normal e Inferencias A Una PoblaciónDokument4 SeitenAC 9. Distribución Normal e Inferencias A Una PoblaciónAndrés LimaNoch keine Bewertungen
- BioanalisisDokument5 SeitenBioanalisisScarlett RamírezNoch keine Bewertungen
- Orca Share Media1553738348593Dokument55 SeitenOrca Share Media1553738348593Iván RodrigoNoch keine Bewertungen
- Capítulo 6 Control Del Voltaje y La FrecuenciaDokument43 SeitenCapítulo 6 Control Del Voltaje y La FrecuenciaBruno SamosNoch keine Bewertungen
- Población y MuestraDokument19 SeitenPoblación y MuestraYESIKA ALEJANDRA VANEGAS CHACONNoch keine Bewertungen
- Preguntas Teoricas Del Cap 10 de RossDokument5 SeitenPreguntas Teoricas Del Cap 10 de RossMilagros SanchezNoch keine Bewertungen
- FM - Guia 4 - Riesgo & Rendimiento 2020-1Dokument5 SeitenFM - Guia 4 - Riesgo & Rendimiento 2020-1LDelPinoAlvarezNoch keine Bewertungen
- Ut4 Distribucion NormalDokument27 SeitenUt4 Distribucion NormalKlaus AnwandterNoch keine Bewertungen
- Actividad 2 BioestadisticaDokument3 SeitenActividad 2 BioestadisticaAnDrez AnakOnaNoch keine Bewertungen
- Ejercicios Cap 13 Iris CastroDokument13 SeitenEjercicios Cap 13 Iris CastroRegina Morales Mourra50% (2)
- Taller 1Dokument6 SeitenTaller 1danieladia100% (1)
- EstadisticaunsaDokument8 SeitenEstadisticaunsaKramnick Yeremi PANoch keine Bewertungen
- Relación Entre Los Parámetros Acústicos, Higiene VocalDokument60 SeitenRelación Entre Los Parámetros Acústicos, Higiene VocalSALSA 10Noch keine Bewertungen
- Tarea 4Dokument4 SeitenTarea 4Luis Fernando Uribe100% (1)
- Análisis de Consistencia-Jatun Soratera, Tamboraque y CarapomaDokument49 SeitenAnálisis de Consistencia-Jatun Soratera, Tamboraque y CarapomaTomasSalazarCastilloNoch keine Bewertungen
- EstadísticaDokument2 SeitenEstadísticaRodrigo Ivan Mendoza Garcia0% (1)
- Calcula El RangoDokument6 SeitenCalcula El RangoMariaNoch keine Bewertungen
- Clase 3 20 04Dokument8 SeitenClase 3 20 04Andrea Arboleda HernandezNoch keine Bewertungen
- Sustentacion Trabajo Colaborativo - Escenario 7 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA II - (GRUPO4)Dokument7 SeitenSustentacion Trabajo Colaborativo - Escenario 7 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA II - (GRUPO4)Lorena CruzNoch keine Bewertungen
- Práctica Calificada - Distribuciones Muestrales PDFDokument47 SeitenPráctica Calificada - Distribuciones Muestrales PDFEsperanza VeraNoch keine Bewertungen
- Tarea 1Dokument1 SeiteTarea 1Estuardo EstradaNoch keine Bewertungen
- Manual de Manejo de Reproductores Cobb 500Dokument62 SeitenManual de Manejo de Reproductores Cobb 500cacolon100% (1)
- Expresión de ResultadosDokument23 SeitenExpresión de ResultadosSoraya López ÁngelNoch keine Bewertungen
- Espectros de Diseño y de RespuestaDokument12 SeitenEspectros de Diseño y de RespuestaAlvaro Pazmiño RomanNoch keine Bewertungen
- Medidas de Dispersión ArveloDokument24 SeitenMedidas de Dispersión ArveloAngel Francisco Arvelo LujánNoch keine Bewertungen
- Capítulo 7: Prueba de ConceptosDokument3 SeitenCapítulo 7: Prueba de Conceptossehidy gabriela caamal pucNoch keine Bewertungen
- ISO 3534-1 2015 - Estadistica - VocabuDokument104 SeitenISO 3534-1 2015 - Estadistica - VocabuALISON ELIZABETH HUAPAYA CAYCHO100% (3)
- Actividad Colaborativa ESTADISTICA Y PROBABILIDADESDokument11 SeitenActividad Colaborativa ESTADISTICA Y PROBABILIDADESBetyy AcevedoNoch keine Bewertungen