Das könnte Ihnen auch gefallen
- XDokument56 SeitenXDeepak BaliyanNoch keine Bewertungen
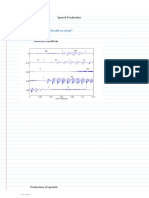
- 3 Production and Classification of Speech SoundsDokument56 Seiten3 Production and Classification of Speech SoundsKuldeep DhootNoch keine Bewertungen
- The Acoustic Phonetics of SpeachDokument8 SeitenThe Acoustic Phonetics of Speachapi-253695787Noch keine Bewertungen
- Airstream Mechanisims and Phnation TypesDokument5 SeitenAirstream Mechanisims and Phnation TypesZena SattarNoch keine Bewertungen
- Gimson's Pronunciation of English CorregidoDokument3 SeitenGimson's Pronunciation of English CorregidoLily Muñoz OrozcoNoch keine Bewertungen
- The Basic Properties of SpeechDokument3 SeitenThe Basic Properties of Speechjeysam0% (1)
- 3.4 The Source-Filter Model of Speech Production: Figure 2.31: Saggital Cross Section of The Vocal TractDokument4 Seiten3.4 The Source-Filter Model of Speech Production: Figure 2.31: Saggital Cross Section of The Vocal TractMirjana NenadovicNoch keine Bewertungen
- Lecture 3 Articulatory PhoneticsDokument29 SeitenLecture 3 Articulatory Phoneticsdavegreenwood100% (1)
- Speech SeminarDokument57 SeitenSpeech SeminarDrshruthi SkNoch keine Bewertungen
- Articulatory Phonetics 1Dokument5 SeitenArticulatory Phonetics 1KhlifibrahimNoch keine Bewertungen
- An Introduction To Speech ProductionDokument11 SeitenAn Introduction To Speech ProductionPetruta IordacheNoch keine Bewertungen
- Synthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezDokument5 SeitenSynthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezZellagui EnergyNoch keine Bewertungen
- Peter Roach2009 - Chapter 4Dokument9 SeitenPeter Roach2009 - Chapter 4Nguyễn QuíNoch keine Bewertungen
- The Vocal Tract: 2.01 Speaking and BreathingDokument10 SeitenThe Vocal Tract: 2.01 Speaking and BreathingbjorngrambowNoch keine Bewertungen
- (2001) Vocal Fold and False Vocal Fold Vibrations in Throat Singing and Synthesis of KhöömeiDokument4 Seiten(2001) Vocal Fold and False Vocal Fold Vibrations in Throat Singing and Synthesis of KhöömeiRicardo Rocha100% (2)
- UNc2rjc ncr2ocmxedIT 2Dokument3 SeitenUNc2rjc ncr2ocmxedIT 2chemaNoch keine Bewertungen
- English Phonetics and Phonology 6Dokument20 SeitenEnglish Phonetics and Phonology 6Mohd Zulkhairi AbdullahNoch keine Bewertungen
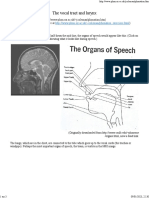
- Info Speech OrgansDokument7 SeitenInfo Speech OrgansMari FigueroaNoch keine Bewertungen
- Phonetics Book LING 372 Chapter 1Dokument6 SeitenPhonetics Book LING 372 Chapter 1Rachida Al FakirNoch keine Bewertungen
- 4 Phonetics: Speech OrgansDokument8 Seiten4 Phonetics: Speech OrgansLorz CatalinaNoch keine Bewertungen
- AIRSchapterDokument13 SeitenAIRSchapterlhercule071Noch keine Bewertungen
- Compound Subjects and PredicatesDokument110 SeitenCompound Subjects and Predicatesakanksha09Noch keine Bewertungen
- Semi Occluded Vocal Tract Exercises AeroDokument11 SeitenSemi Occluded Vocal Tract Exercises AeroSerginho KabuloNoch keine Bewertungen
- دكتور هاشم المحاضرة الاولىDokument6 Seitenدكتور هاشم المحاضرة الاولىanmar ahmedNoch keine Bewertungen
- Introduction Summary - PronunciationDokument4 SeitenIntroduction Summary - PronunciationStellaNoch keine Bewertungen
- Physiology of Phonation Written OutputDokument10 SeitenPhysiology of Phonation Written OutputDeane BiancaNoch keine Bewertungen
- 10 1017@cbo9781139166126 002Dokument28 Seiten10 1017@cbo9781139166126 002subtitle kurdiNoch keine Bewertungen
- VowelsDokument110 SeitenVowelsamirNoch keine Bewertungen
- Summary GimsonDokument6 SeitenSummary GimsonsgambelluribeiroNoch keine Bewertungen
- Quarterly Progress and Status Report: Dept. For Speech, Music and HearingDokument26 SeitenQuarterly Progress and Status Report: Dept. For Speech, Music and HearingTheresa HagenNoch keine Bewertungen
- Speech Signal Processing and Cross Language Information RetrievalDokument45 SeitenSpeech Signal Processing and Cross Language Information RetrievalIswarya PurushothamanNoch keine Bewertungen
- Articulatory PhoneticsDokument5 SeitenArticulatory Phoneticsابو محمدNoch keine Bewertungen
- Respiration & VoicingDokument2 SeitenRespiration & Voicingrosenasiri714Noch keine Bewertungen
- Unit 2Dokument25 SeitenUnit 2vazlloNoch keine Bewertungen
- Unit 3. Consonants: A Theoretical ApproachDokument17 SeitenUnit 3. Consonants: A Theoretical ApproachAna Bella FranciscoNoch keine Bewertungen
- Notes WK 1 1Dokument12 SeitenNotes WK 1 1HarshalNoch keine Bewertungen
- Adjustment of Glottal Configurations in Singing: Christian T. Herbst and Jan G. ŠvecDokument8 SeitenAdjustment of Glottal Configurations in Singing: Christian T. Herbst and Jan G. ŠvecLindaNoch keine Bewertungen
- Phonation and Oro-Nasal ProcessesDokument10 SeitenPhonation and Oro-Nasal ProcessesAnn VillarNoch keine Bewertungen
- Air and PhonationDokument3 SeitenAir and PhonationDjalal MoumenNoch keine Bewertungen
- V R, V F V P P V: Marek Fric, František Šram, Jan G. ŠvecDokument4 SeitenV R, V F V P P V: Marek Fric, František Šram, Jan G. ŠvecTravis Mc DowallNoch keine Bewertungen
- Speech ChainDokument6 SeitenSpeech ChainNatalia Correa GuerreroNoch keine Bewertungen
- Articulatory PhoneticsDokument6 SeitenArticulatory PhoneticsGlennmeloveNoch keine Bewertungen
- Biomedical Signal Processing and Control: P.H. Dejonckere, J. LebacqDokument11 SeitenBiomedical Signal Processing and Control: P.H. Dejonckere, J. LebacqKariny KelviaNoch keine Bewertungen
- Acoustic Theory of Speech ProductionDokument57 SeitenAcoustic Theory of Speech ProductionMiza MariyamNoch keine Bewertungen
- Resume FonologiDokument24 SeitenResume FonologiEndang Tri RahayuNoch keine Bewertungen
- Energy and SingingDokument6 SeitenEnergy and SingingAndria UaleNoch keine Bewertungen
- Linguistics 2Dokument45 SeitenLinguistics 2Bani AbdullaNoch keine Bewertungen
- 2 The Sound-Producing SystemDokument2 Seiten2 The Sound-Producing SystemRoberto Carlos Sosa BadilloNoch keine Bewertungen
- Consonant SoundsDokument5 SeitenConsonant SoundsPrincess ToriNoch keine Bewertungen
- English Phonetics - ConsonantsDokument15 SeitenEnglish Phonetics - ConsonantsJandelineNoch keine Bewertungen
- Makalah Phonology Kelompok 2Dokument11 SeitenMakalah Phonology Kelompok 2meldianto manugalaNoch keine Bewertungen
- Ohala Sole 2010 TurbulenceDokument66 SeitenOhala Sole 2010 TurbulenceCarol LainaNoch keine Bewertungen
- Phonetics in Phonology: John J. OhalaDokument6 SeitenPhonetics in Phonology: John J. OhalaNoorul JannahNoch keine Bewertungen
- B.Ed Notes 502Dokument16 SeitenB.Ed Notes 502Adeel RazaNoch keine Bewertungen
- 2010 - 38 - 2 - Fletcher - ACOUSTICAL BACKGROUND TO THE MANY VARIETIES OF BIRDSONGDokument4 Seiten2010 - 38 - 2 - Fletcher - ACOUSTICAL BACKGROUND TO THE MANY VARIETIES OF BIRDSONGBozidar KemicNoch keine Bewertungen
- Excerpt From Chapter 10: RegistrationDokument4 SeitenExcerpt From Chapter 10: RegistrationBrenda IglesiasNoch keine Bewertungen
- Lecture 1-7: Source-Filter ModelDokument6 SeitenLecture 1-7: Source-Filter ModelhadaspeeryNoch keine Bewertungen
- Nasals Unplugged: The Aerodynamics of Nasal De-Occlusivization in SpanishDokument9 SeitenNasals Unplugged: The Aerodynamics of Nasal De-Occlusivization in Spanishsuar_kardiniNoch keine Bewertungen
- El Eufemismo y El Difemismo. Procesos de Manipulacion Del TabúDokument113 SeitenEl Eufemismo y El Difemismo. Procesos de Manipulacion Del TabúcareconcreNoch keine Bewertungen
- Development of A Single-Chain Variable Fragment ofDokument15 SeitenDevelopment of A Single-Chain Variable Fragment ofMuhammad AgungNoch keine Bewertungen
- Howard M. Federspiel - Islam and Ideology in the Emerging Indonesian State_ the Persatuan Islam (Persis), 1923 to 1957 (Social, Economic and Political Studies of the Middle East and Asia)-Brill AcademDokument382 SeitenHoward M. Federspiel - Islam and Ideology in the Emerging Indonesian State_ the Persatuan Islam (Persis), 1923 to 1957 (Social, Economic and Political Studies of the Middle East and Asia)-Brill AcademMuhammad AgungNoch keine Bewertungen
- China0918 WebDokument125 SeitenChina0918 WebMuhammad AgungNoch keine Bewertungen
- 06 MEEG FieldTripDokument41 Seiten06 MEEG FieldTripMuhammad AgungNoch keine Bewertungen
- Master Biomedical Engineering Guide 2016-2017 - Version 20160904Dokument43 SeitenMaster Biomedical Engineering Guide 2016-2017 - Version 20160904Muhammad AgungNoch keine Bewertungen
- Module7 PDFDokument76 SeitenModule7 PDFMuhammad AgungNoch keine Bewertungen
- Bci-Ssvep Final ReviewedDokument8 SeitenBci-Ssvep Final ReviewedMuhammad AgungNoch keine Bewertungen
- Analysis and Classification of Speech Signals by Generalized Fractal Dimension FeaturesDokument18 SeitenAnalysis and Classification of Speech Signals by Generalized Fractal Dimension FeaturesMuhammad AgungNoch keine Bewertungen
- Nonmelanoma Skin Cancer: Prof - Dr.Dr. Teguh Aryandono, SPB (K) Onk Division of Surgical Oncology, GmuDokument22 SeitenNonmelanoma Skin Cancer: Prof - Dr.Dr. Teguh Aryandono, SPB (K) Onk Division of Surgical Oncology, GmuFazaKhilwanAmnaNoch keine Bewertungen
- Welrod Silenced PistolDokument2 SeitenWelrod Silenced Pistolblowmeasshole1911Noch keine Bewertungen
- 1 s2.0 S0956713515002546 Main PDFDokument9 Seiten1 s2.0 S0956713515002546 Main PDFIfwat ThaqifNoch keine Bewertungen
- TotSK 3.0Dokument22 SeitenTotSK 3.0PedroNoch keine Bewertungen
- 32lh250h Commercial Mode PDFDokument46 Seiten32lh250h Commercial Mode PDFcordero medusaNoch keine Bewertungen
- National Railway Museum Annual Review 04-05Dokument40 SeitenNational Railway Museum Annual Review 04-05sol.loredo1705530Noch keine Bewertungen
- 2019 BMS1021 Practice Questions Answers PDFDokument12 Seiten2019 BMS1021 Practice Questions Answers PDFaskldhfdasjkNoch keine Bewertungen
- Solid State Controller of Drives - ExperimentDokument37 SeitenSolid State Controller of Drives - ExperimentRakesh Singh LodhiNoch keine Bewertungen
- Edrolo ch3Dokument42 SeitenEdrolo ch3YvonneNoch keine Bewertungen
- 240-Article Text-799-3-10-20190203Dokument6 Seiten240-Article Text-799-3-10-20190203EVANDRO FRANCO DA ROCHANoch keine Bewertungen
- Medgroup Packet Tracer Skills Integration Challenge: - Design and Prototype The New Medgroup TopologyDokument4 SeitenMedgroup Packet Tracer Skills Integration Challenge: - Design and Prototype The New Medgroup TopologyvilanchNoch keine Bewertungen
- 0.6m (2ft) Low Profile Antennas Microwave Antenna SpecificationsDokument15 Seiten0.6m (2ft) Low Profile Antennas Microwave Antenna SpecificationsDarwin Lopez AcevedoNoch keine Bewertungen
- FUCHS LUBRITECH Product RangeDokument76 SeitenFUCHS LUBRITECH Product RangeBurak GüleşNoch keine Bewertungen
- Institute of Metallurgy and Materials Engineering Faculty of Chemical and Materials Engineering University of The Punjab LahoreDokument10 SeitenInstitute of Metallurgy and Materials Engineering Faculty of Chemical and Materials Engineering University of The Punjab LahoreMUmairQrNoch keine Bewertungen
- Propagare - Threshold Degradation - AbateriDokument72 SeitenPropagare - Threshold Degradation - AbateriAndrada AdaNoch keine Bewertungen
- MGE UPS Comissioning GuideDokument19 SeitenMGE UPS Comissioning GuideAldo Rodriguez MaturanaNoch keine Bewertungen
- Anil Singh Rathore: Career HighlightsDokument4 SeitenAnil Singh Rathore: Career HighlightsHRD CORP CONSULTANCYNoch keine Bewertungen
- Cigarettes and AlcoholDokument1 SeiteCigarettes and AlcoholHye Jin KimNoch keine Bewertungen
- It Park Design Submission PDFDokument20 SeitenIt Park Design Submission PDFSAKET TYAGI100% (1)
- MicrosoftDynamicsNAVAdd OnsDokument620 SeitenMicrosoftDynamicsNAVAdd OnsSadiq QudduseNoch keine Bewertungen
- Sunday Afternoon, October 27, 2013: TechnologyDokument283 SeitenSunday Afternoon, October 27, 2013: TechnologyNatasha MyersNoch keine Bewertungen
- Course For Loco Inspector Initial (Diesel)Dokument239 SeitenCourse For Loco Inspector Initial (Diesel)Hanuma Reddy93% (14)
- Static CMOS and Dynamic CircuitsDokument19 SeitenStatic CMOS and Dynamic CircuitsAbhijna MaiyaNoch keine Bewertungen
- Servo Controlled FBW With Power Boost Control, Operations & Maint. ManualDokument126 SeitenServo Controlled FBW With Power Boost Control, Operations & Maint. ManualKota NatarajanNoch keine Bewertungen
- Yehuda Berg Satan PDFDokument77 SeitenYehuda Berg Satan PDFOswaldo Archundia100% (7)
- Surface & Subsurface Geotechnical InvestigationDokument5 SeitenSurface & Subsurface Geotechnical InvestigationAshok Kumar SahaNoch keine Bewertungen
- Em - Animals A To ZDokument9 SeitenEm - Animals A To ZgowriNoch keine Bewertungen
- Travelsinvarious03clar BWDokument522 SeitenTravelsinvarious03clar BWSima Sorin MihailNoch keine Bewertungen
- Iare Ece Aec012 DSP QB 0Dokument20 SeitenIare Ece Aec012 DSP QB 0projects allNoch keine Bewertungen
- GP 24-21 - Fire Hazard AnalysisDokument53 SeitenGP 24-21 - Fire Hazard AnalysisJohn DryNoch keine Bewertungen