Das könnte Ihnen auch gefallen
- Ipsotek VISuite DatasheetDokument2 SeitenIpsotek VISuite DatasheetMaria PredanNoch keine Bewertungen
- AEM 6 Certification 2Dokument47 SeitenAEM 6 Certification 2raja sekhar reddy Bhavanam100% (1)
- USSD and SMS Market Review Short Final ReportDokument43 SeitenUSSD and SMS Market Review Short Final Reportunknown4080Noch keine Bewertungen
- cs298 Report Dhillon Ravi PDFDokument61 Seitencs298 Report Dhillon Ravi PDFALOKIK YADAVNoch keine Bewertungen
- Building A RESTful Web ServiceDokument8 SeitenBuilding A RESTful Web ServicedendibeckNoch keine Bewertungen
- Telecom Data SheetDokument2 SeitenTelecom Data SheetBhupendra JhaNoch keine Bewertungen
- Ratecard Ivosights 2021Dokument21 SeitenRatecard Ivosights 2021Somad Rachmat WidhiaNoch keine Bewertungen
- Technical Proposal For Libyana GPRS Roaming Solution (V0.2)Dokument25 SeitenTechnical Proposal For Libyana GPRS Roaming Solution (V0.2)صديقكالوفيNoch keine Bewertungen
- Jukka Lintusaari IRU Ertico MaaS WorkhopDokument17 SeitenJukka Lintusaari IRU Ertico MaaS WorkhopanirudhasNoch keine Bewertungen
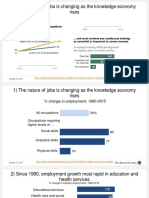
- 1) The Nature of Jobs Is Changing As The Knowledge Economy RisesDokument16 Seiten1) The Nature of Jobs Is Changing As The Knowledge Economy Risesmeh3reNoch keine Bewertungen
- Deep Analytics Services - Ivosights 2021Dokument19 SeitenDeep Analytics Services - Ivosights 2021Elga YulwardianNoch keine Bewertungen
- Internet of Things: Iot Protocols - Unit - 2Dokument135 SeitenInternet of Things: Iot Protocols - Unit - 2Manikanta RobbiNoch keine Bewertungen
- 5 G Test BedDokument10 Seiten5 G Test BedAnkur AgarwalNoch keine Bewertungen
- Kiosk ManualDokument39 SeitenKiosk Manualezlink5Noch keine Bewertungen
- WAPT Generic CheckListDokument6 SeitenWAPT Generic CheckListsamsungNoch keine Bewertungen
- ITServices SOP OverallOperations2010 - Version1.3Dokument32 SeitenITServices SOP OverallOperations2010 - Version1.3santsj78Noch keine Bewertungen
- Proposal No. Frame Agreement:: XXX/XX - XX.XXXX XX - XX.XXXXDokument3 SeitenProposal No. Frame Agreement:: XXX/XX - XX.XXXX XX - XX.XXXXDicu AndreiNoch keine Bewertungen
- Wireless Networks: Gates Institute of TechnologyDokument13 SeitenWireless Networks: Gates Institute of TechnologyShaik AllabakashNoch keine Bewertungen
- Olympic InnovationDokument40 SeitenOlympic InnovationBBVA Innovation CenterNoch keine Bewertungen
- Strategic Management - Modified Maps - Coloured - February 2020Dokument11 SeitenStrategic Management - Modified Maps - Coloured - February 2020ahmedgelixNoch keine Bewertungen
- Calculate, Communicate and Compare Your Cyber Exposure Key BenefitsDokument2 SeitenCalculate, Communicate and Compare Your Cyber Exposure Key BenefitsSantiago HuilcamaiguaNoch keine Bewertungen
- Understanding Cloud ComputingDokument14 SeitenUnderstanding Cloud ComputingPawanNoch keine Bewertungen
- Cloud Computing: Helping Financial Institutions Leverage The Cloud To Improve IT EfficiencyDokument15 SeitenCloud Computing: Helping Financial Institutions Leverage The Cloud To Improve IT EfficiencyIBMBankingNoch keine Bewertungen
- Next Generation Library and Information Services Strategy 2012-2015Dokument19 SeitenNext Generation Library and Information Services Strategy 2012-2015Phyllis StephenNoch keine Bewertungen
- Dhrubajit Das's ProjectDokument27 SeitenDhrubajit Das's ProjectAnonymous 4MXnnF0NZbNoch keine Bewertungen
- 7code PresentationDokument14 Seiten7code PresentationNicuMardariNoch keine Bewertungen
- NIST Cloud Computing Reference Architecture PDFDokument35 SeitenNIST Cloud Computing Reference Architecture PDFoswaldofarithNoch keine Bewertungen
- IT Sector NewDokument29 SeitenIT Sector NewShashank KumarNoch keine Bewertungen
- Smart Home: Technology Solutions For Smart BuildingsDokument31 SeitenSmart Home: Technology Solutions For Smart Buildingsb01eru84Noch keine Bewertungen
- 4IT As A ServiceDokument2 Seiten4IT As A ServicerohitNoch keine Bewertungen
- How Using Iot Helps To Form Heterogeneous Long and Short-Range Networks For Sensing and Asset TrackingDokument9 SeitenHow Using Iot Helps To Form Heterogeneous Long and Short-Range Networks For Sensing and Asset TrackingParesh PatelNoch keine Bewertungen
- Common DDoS AttacksDokument6 SeitenCommon DDoS AttacksregabriNoch keine Bewertungen
- 2015 Hfs Blueprint Iot Services 2015Dokument56 Seiten2015 Hfs Blueprint Iot Services 2015Joca Tartuf Emeritus100% (1)
- The State of Dark Data ReportDokument28 SeitenThe State of Dark Data ReportgkpalokNoch keine Bewertungen
- Comtec IT Infrastructure 2012Dokument12 SeitenComtec IT Infrastructure 2012Paddy BukkettNoch keine Bewertungen
- 50 Email Security Best PracticesDokument17 Seiten50 Email Security Best Practicesjames smithNoch keine Bewertungen
- Big Data in Telecommunication OperDokument14 SeitenBig Data in Telecommunication OperSHASHIKANTNoch keine Bewertungen
- A Study On Big Data Processing Mechanism & Applicability: Byung-Tae Chun and Seong-Hoon LeeDokument10 SeitenA Study On Big Data Processing Mechanism & Applicability: Byung-Tae Chun and Seong-Hoon LeeVladimir Calle MayserNoch keine Bewertungen
- 2015 Sentiment Analysis of Twitter Data Within Big Data DistributedDokument6 Seiten2015 Sentiment Analysis of Twitter Data Within Big Data DistributedDeepa BoobalakrishnanNoch keine Bewertungen
- Fundamentals of Big Data JUNE 2022Dokument11 SeitenFundamentals of Big Data JUNE 2022Rajni KumariNoch keine Bewertungen
- 4 Roychoudhury KulkarniDokument4 Seiten4 Roychoudhury KulkarniArindam BanerjeeNoch keine Bewertungen
- 1 Foreword: TerminologyDokument6 Seiten1 Foreword: TerminologyManikandan K KrishnankuttyNoch keine Bewertungen
- Development Framework For Mobile Social Applications: (Despindler, Grossniklaus, Norrie) @inf - Ethz.chDokument15 SeitenDevelopment Framework For Mobile Social Applications: (Despindler, Grossniklaus, Norrie) @inf - Ethz.chهيدايو کامارودينNoch keine Bewertungen
- Service Level Comparison For Online Shopping Using Data MiningDokument4 SeitenService Level Comparison For Online Shopping Using Data MiningIIR indiaNoch keine Bewertungen
- Big Data Technology in ConstructionDokument6 SeitenBig Data Technology in Constructionsawaf fasaluNoch keine Bewertungen
- Exploration On Big Data Oriented Data Analyzing and Processing TechnologyDokument7 SeitenExploration On Big Data Oriented Data Analyzing and Processing TechnologyRookie VishwakantNoch keine Bewertungen
- 10 Strategic Technological Trends in 2019Dokument10 Seiten10 Strategic Technological Trends in 2019Fatma El Zahraa IsmailNoch keine Bewertungen
- Growing Smart Cities On An Open-Data-Centric Cyber-Physical PlatformDokument6 SeitenGrowing Smart Cities On An Open-Data-Centric Cyber-Physical Platformgonzalo lopezNoch keine Bewertungen
- Facebook Crawler As Software Agent For Business Intelligence SystemDokument22 SeitenFacebook Crawler As Software Agent For Business Intelligence SystemErickNoch keine Bewertungen
- Exploiting Rich Telecom Data For Increased Monetization of Telecom Application StoresDokument6 SeitenExploiting Rich Telecom Data For Increased Monetization of Telecom Application Storeszaib29Noch keine Bewertungen
- ATEKO Et Al DEVELOPMENT OF A NEWS DROID AND EVENT REPORTING SYSTEMDokument7 SeitenATEKO Et Al DEVELOPMENT OF A NEWS DROID AND EVENT REPORTING SYSTEMBusayo AtekoNoch keine Bewertungen
- Mobile 3.0 Mobile Enterprise Application DevelopmentDokument14 SeitenMobile 3.0 Mobile Enterprise Application DevelopmentgradybizNoch keine Bewertungen
- Ecommendation System For Information Services Adapted Over Terrestrial Digital TelevisionDokument13 SeitenEcommendation System For Information Services Adapted Over Terrestrial Digital TelevisioncseijNoch keine Bewertungen
- M2M To Iot: 2180709 Prof - Dharmesh G PatelDokument40 SeitenM2M To Iot: 2180709 Prof - Dharmesh G PatelTapan ShahNoch keine Bewertungen
- Big Data, Cloud Computing, and Mobile TrafficDokument12 SeitenBig Data, Cloud Computing, and Mobile TrafficRV devNoch keine Bewertungen
- A Novel Big Data Analytics Framework For Smart CitiesDokument30 SeitenA Novel Big Data Analytics Framework For Smart Citieseng.emanahmed2014Noch keine Bewertungen
- Digital Technologies – an Overview of Concepts, Tools and Techniques Associated with itVon EverandDigital Technologies – an Overview of Concepts, Tools and Techniques Associated with itNoch keine Bewertungen
- Automotive Big DataDokument10 SeitenAutomotive Big DataravigobiNoch keine Bewertungen
- Concept of Delivery System in The Smart City EnvironmentDokument16 SeitenConcept of Delivery System in The Smart City EnvironmentJames MorenoNoch keine Bewertungen
- Big Data ChallengesDokument10 SeitenBig Data ChallengessvuhariNoch keine Bewertungen
- Raja Sharan CloudDokument6 SeitenRaja Sharan CloudRaju PatnaNoch keine Bewertungen
- Engineering Journal Towards A Framework For Executives and Decision Makers To Discriminate Big Data Projects For International DevelopmentDokument5 SeitenEngineering Journal Towards A Framework For Executives and Decision Makers To Discriminate Big Data Projects For International DevelopmentEngineering JournalNoch keine Bewertungen
- Design of The Low-Cost Business Intelligence System Based On Multi-AgentDokument4 SeitenDesign of The Low-Cost Business Intelligence System Based On Multi-AgentShree Krishna ShresthaNoch keine Bewertungen
- Configuration Options and URL Parameters 91f2d03Dokument8 SeitenConfiguration Options and URL Parameters 91f2d03zzgNoch keine Bewertungen
- Application Builder Configuration Guide: Ibm Infosphere Data ExplorerDokument46 SeitenApplication Builder Configuration Guide: Ibm Infosphere Data ExplorerPrabu ChinnasamyNoch keine Bewertungen
- Books PHPDokument53 SeitenBooks PHPV.M.B.SNoch keine Bewertungen
- Servlet Interview Question and AnswerDokument32 SeitenServlet Interview Question and AnswerNaresh RomeoNoch keine Bewertungen
- JSPDokument19 SeitenJSPManohar PatidarNoch keine Bewertungen
- Student AssignmentsDokument61 SeitenStudent AssignmentsShashank GosaviNoch keine Bewertungen
- Gravity Force Lab HTML Guide - enDokument3 SeitenGravity Force Lab HTML Guide - endedirusadi277Noch keine Bewertungen
- Redirect Web Visitors by Country Using PHP and MYSQL DatabaseDokument3 SeitenRedirect Web Visitors by Country Using PHP and MYSQL DatabaseIP2Location.com100% (2)
- How To Install Tomcat 7 or 8 (On Windows, Mac OS X and Ubuntu)Dokument16 SeitenHow To Install Tomcat 7 or 8 (On Windows, Mac OS X and Ubuntu)alejandroNoch keine Bewertungen
- Configuring SearchDokument32 SeitenConfiguring SearchRohan JaggaNoch keine Bewertungen
- Introduction To PayPal For C# - ASPDokument15 SeitenIntroduction To PayPal For C# - ASPaspintegrationNoch keine Bewertungen
- Chinese BIG5Dokument18 SeitenChinese BIG5FedericoNoch keine Bewertungen
- Google Data StoreDokument56 SeitenGoogle Data StoreindochinahubNoch keine Bewertungen
- CS411 Notes in Short As Short NotesDokument66 SeitenCS411 Notes in Short As Short NotesAnas arainNoch keine Bewertungen
- enteliWEB 4.5 Developer GuideDokument102 SeitenenteliWEB 4.5 Developer GuiderobgsNoch keine Bewertungen
- General EBS SetupDokument119 SeitenGeneral EBS SetupHidayatulla ShaikhNoch keine Bewertungen
- Guide For Java Devs Vert.xDokument119 SeitenGuide For Java Devs Vert.xJuan PérezNoch keine Bewertungen
- Cosec Device Api - v1.0Dokument91 SeitenCosec Device Api - v1.0Animesh Khare100% (1)
- EbsDokument35 SeitenEbssarrojNoch keine Bewertungen
- Developer ExampleDokument87 SeitenDeveloper ExamplehardironNoch keine Bewertungen
- Windchill Performance Tuning GuideDokument175 SeitenWindchill Performance Tuning GuidecontdavNoch keine Bewertungen
- Delphi Informant Magazine Vol 6 No 4Dokument34 SeitenDelphi Informant Magazine Vol 6 No 4sharkfinmikeNoch keine Bewertungen
- Facebook Code BookDokument151 SeitenFacebook Code BookAlsheDupurNoch keine Bewertungen
- OpenSearch Cheat Sheet 1-5Dokument2 SeitenOpenSearch Cheat Sheet 1-5Gareth J M Saunders100% (2)
- Aph QLDokument270 SeitenAph QLheartbleed.exeNoch keine Bewertungen
- FastAPI Interview Questions and AnswersDokument3 SeitenFastAPI Interview Questions and Answersmuichiro.a9meNoch keine Bewertungen
- URLDokument4 SeitenURLEmmerNoch keine Bewertungen