Das könnte Ihnen auch gefallen
- Clase 04 - Lenguajes Regulares y Expresiones RegularesDokument70 SeitenClase 04 - Lenguajes Regulares y Expresiones RegularesPaoO'la Lacruz SNoch keine Bewertungen
- Sistemas de InventariosDokument5 SeitenSistemas de InventariosEMILY SUAREZ RUIZ0% (1)
- 2.7. Actividades PropuestasDokument31 Seiten2.7. Actividades PropuestasNICOLAS ROJAS TEJADANoch keine Bewertungen
- 1 Estadística Descriptiva Con MinitabDokument21 Seiten1 Estadística Descriptiva Con Minitabvictor_1981Noch keine Bewertungen
- Chi CuadradaDokument16 SeitenChi CuadradaGustavo TellezNoch keine Bewertungen
- Lp11 Aplicaciones Windows FormDokument394 SeitenLp11 Aplicaciones Windows FormEdwin ArevaloNoch keine Bewertungen
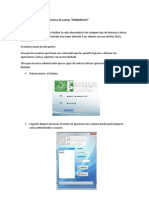
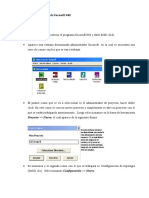
- Manual de Usuario Del Sistema de VentasDokument5 SeitenManual de Usuario Del Sistema de VentasRamiro Sanchez RamosNoch keine Bewertungen
- La Falacia Del FiscalDokument3 SeitenLa Falacia Del FiscalRADA1235476Noch keine Bewertungen
- Resumen Del Capítulo 9 de Ingeniería de SoftwareDokument6 SeitenResumen Del Capítulo 9 de Ingeniería de SoftwaregustavoNoch keine Bewertungen
- Jelozgon - Funcion Lineal 2021-2Dokument4 SeitenJelozgon - Funcion Lineal 2021-2Maria RangelNoch keine Bewertungen
- GXX SE Ejercicio 04 02Dokument5 SeitenGXX SE Ejercicio 04 02CristhianDavid0% (1)
- POO Examen Solucion Segundo Parcial ESPOLDokument10 SeitenPOO Examen Solucion Segundo Parcial ESPOLRonny MoránNoch keine Bewertungen
- Ejercicios Propuestos para Los Módulos de Programación Ciclos Formativos de InformáticaDokument50 SeitenEjercicios Propuestos para Los Módulos de Programación Ciclos Formativos de InformáticaJose Luis TrujilloNoch keine Bewertungen
- EjerciciosResueltosBusqueda InteligenciaDokument205 SeitenEjerciciosResueltosBusqueda InteligenciaAlonso CruzNoch keine Bewertungen
- Instalacion y Configuracion de Postfix y Dovecot en UbuntuDokument9 SeitenInstalacion y Configuracion de Postfix y Dovecot en UbuntuFerNey VasquezNoch keine Bewertungen
- Ejercicios Expresiones REgularesDokument64 SeitenEjercicios Expresiones REgularesSolomeo Paredes100% (1)
- Ejercicio Análisis de InversionesDokument3 SeitenEjercicio Análisis de InversionesDaniel ArteagaNoch keine Bewertungen
- Consultas de Base EscuelaDokument8 SeitenConsultas de Base EscueladraunzNoch keine Bewertungen
- Ejercicio de Interfaces en JavaDokument5 SeitenEjercicio de Interfaces en JavaItzelRManterolaNoch keine Bewertungen
- Ejercicio 4 - Tienda Informatica SQLDokument8 SeitenEjercicio 4 - Tienda Informatica SQLThomas WrightNoch keine Bewertungen
- Algoritmode StrassenDokument14 SeitenAlgoritmode StrassenJhon Antonio Quispe ChoqueNoch keine Bewertungen
- Tutorial Sobre El Uso Del MVC en PHPDokument6 SeitenTutorial Sobre El Uso Del MVC en PHPCarlos Mosquera WiltordNoch keine Bewertungen
- Tarea 4Dokument3 SeitenTarea 4Senya AnhelyNoch keine Bewertungen
- Guia SQL ABDDokument237 SeitenGuia SQL ABDwilder yesid lesmes pinzonNoch keine Bewertungen
- 337 Lectura6.3.3Dokument17 Seiten337 Lectura6.3.3Aldo RuizNoch keine Bewertungen
- Qué Son IntégralesDokument11 SeitenQué Son IntégralesJOHN HUMBERTO POSSO SALCEDONoch keine Bewertungen
- Casos de Uso Metodo de PagoDokument1 SeiteCasos de Uso Metodo de PagoAlejandra PolocheNoch keine Bewertungen
- OpenGL - IntroduccionDokument17 SeitenOpenGL - IntroduccionNeneFINoch keine Bewertungen
- Operaciones Pilas - PHPDokument2 SeitenOperaciones Pilas - PHPjguerramaya100% (1)
- 005 MetNum Interpolacion Numerica Lagrange 2019IIDokument16 Seiten005 MetNum Interpolacion Numerica Lagrange 2019IIMiguel VilcaNoch keine Bewertungen
- Lab N - 6 - Programaci+ N Visual C++ - Arreglos Vectores - 2011-IDokument5 SeitenLab N - 6 - Programaci+ N Visual C++ - Arreglos Vectores - 2011-IKike ZCNoch keine Bewertungen
- Tema 11 Investigacion Operativa Con RDokument10 SeitenTema 11 Investigacion Operativa Con RTito BarrionuevoNoch keine Bewertungen
- Administracion de Inventarios Miguelina VegaDokument87 SeitenAdministracion de Inventarios Miguelina VegaWalter Ariza PertuzNoch keine Bewertungen
- Discreta - Segunda Evaluación de ConocimientosDokument2 SeitenDiscreta - Segunda Evaluación de ConocimientosAlejandro BrayanNoch keine Bewertungen
- Validacion de Datos y MatricesDokument4 SeitenValidacion de Datos y MatricesArmida SucasaireNoch keine Bewertungen
- Notacion InfijaDokument2 SeitenNotacion InfijaJudiith ReyesNoch keine Bewertungen
- PilasDokument2 SeitenPilasamareNoch keine Bewertungen
- Ex Bas Pra 4Dokument1 SeiteEx Bas Pra 4Sinhue LeónNoch keine Bewertungen
- Simulacion C Sharp - ADokument32 SeitenSimulacion C Sharp - ARob BrañezNoch keine Bewertungen
- 4.2 Diagramas de SintaxisDokument17 Seiten4.2 Diagramas de SintaxisJuanlanixNoch keine Bewertungen
- Estructuras y Elementos de PythonDokument26 SeitenEstructuras y Elementos de PythonmiguelNoch keine Bewertungen
- Optimizacion Consultas 2Dokument33 SeitenOptimizacion Consultas 2Mercy OspinaNoch keine Bewertungen
- Algoritmo 8 Reinas RecursividadDokument7 SeitenAlgoritmo 8 Reinas RecursividadJonatan ChubbNoch keine Bewertungen
- Numeros Pseudoaleatorios PDFDokument21 SeitenNumeros Pseudoaleatorios PDFRicardoNoch keine Bewertungen
- Arraylist de Objetos en JavaDokument4 SeitenArraylist de Objetos en Javamiguel9309Noch keine Bewertungen
- CLASE 2 - Estadística Descriptiva (7192)Dokument137 SeitenCLASE 2 - Estadística Descriptiva (7192)José MontenegroNoch keine Bewertungen
- Examen Proba 3er ParcialDokument5 SeitenExamen Proba 3er ParcialChepMurdocNoch keine Bewertungen
- Investigacion de Operaciones (Método de La Gran M - Dos Fases)Dokument10 SeitenInvestigacion de Operaciones (Método de La Gran M - Dos Fases)Luis Armando Morales GonzálezNoch keine Bewertungen
- Evaluacion Presaberes Unad Base de DatosDokument14 SeitenEvaluacion Presaberes Unad Base de DatosJULIETHNoch keine Bewertungen
- Instalacion de SybaseDokument54 SeitenInstalacion de SybaseAlejandro Bustamante MendozaNoch keine Bewertungen
- Practica RNAsDokument7 SeitenPractica RNAsJose RamonNoch keine Bewertungen
- Manual R en EspañolDokument38 SeitenManual R en EspañolJoseph PerryNoch keine Bewertungen
- Int Octave 2022 IDokument127 SeitenInt Octave 2022 Imariano quintanillaNoch keine Bewertungen
- TP2 2006Dokument14 SeitenTP2 2006Joha MarinNoch keine Bewertungen
- Ceduvirt Matlab para IngenierosDokument71 SeitenCeduvirt Matlab para IngenierosHemerson Lizarbe AlarcónNoch keine Bewertungen
- Laboratorio#1 Introducción Al MatlabDokument6 SeitenLaboratorio#1 Introducción Al MatlabGustavo Ascarrunz GomezNoch keine Bewertungen
- Introduccion A MatlabDokument23 SeitenIntroduccion A MatlabpsyoNoch keine Bewertungen
- Resolucion Ejercicios1Dokument10 SeitenResolucion Ejercicios1Edgar Jaime Ochoa SalinasNoch keine Bewertungen
- Matlab para EDO 1Dokument35 SeitenMatlab para EDO 1Hector Levano GamboaNoch keine Bewertungen
- Métodos Matriciales para ingenieros con MATLABVon EverandMétodos Matriciales para ingenieros con MATLABBewertung: 5 von 5 Sternen5/5 (1)
- Modelo de Contrato de OutsourcingDokument10 SeitenModelo de Contrato de OutsourcingLibrosAyudaNoch keine Bewertungen
- El Análisis Del Público en Expresión OralDokument6 SeitenEl Análisis Del Público en Expresión OralLibrosAyudaNoch keine Bewertungen
- Citas TextualesDokument2 SeitenCitas TextualesLibrosAyudaNoch keine Bewertungen
- Ensayo Sobre El Renacimiento Italiano - Historia Del ArteDokument3 SeitenEnsayo Sobre El Renacimiento Italiano - Historia Del ArteLibrosAyudaNoch keine Bewertungen
- Plan Estratégico de Marketing para El Lanzamiento de Un ProductosDokument131 SeitenPlan Estratégico de Marketing para El Lanzamiento de Un ProductosLibrosAyuda100% (1)
- Presentacion Arte EgipcioDokument15 SeitenPresentacion Arte EgipcioLibrosAyudaNoch keine Bewertungen
- Mostrar Un Texto en Una Caja de DialogoDokument4 SeitenMostrar Un Texto en Una Caja de DialogoJeisson Andres CortesNoch keine Bewertungen
- Mat021-Guia Funciones DesarrolloDokument20 SeitenMat021-Guia Funciones DesarrolloCeeiqa UsmNoch keine Bewertungen
- Constantes y Variables PDFDokument6 SeitenConstantes y Variables PDFRogert RamosNoch keine Bewertungen
- Tipos de HackersDokument14 SeitenTipos de HackersChristopher RamosNoch keine Bewertungen
- La Inteligencia Artificial y Su Aplicación Con La Seguridad BiometricaDokument11 SeitenLa Inteligencia Artificial y Su Aplicación Con La Seguridad BiometricaJuan Manuel GallegosNoch keine Bewertungen
- Propuesta de Implementación de La Firma Digital para La Cooperativa CoopserpDokument77 SeitenPropuesta de Implementación de La Firma Digital para La Cooperativa CoopserpElisa AlanocaNoch keine Bewertungen
- Program AsDokument1 SeiteProgram Asflashbry0% (1)
- Curso Administrador SPDokument90 SeitenCurso Administrador SPjadg0070scribdNoch keine Bewertungen
- Modelo Parabolico para La Pluma de Contaminacion en Un RioDokument17 SeitenModelo Parabolico para La Pluma de Contaminacion en Un RioManuel KronhausNoch keine Bewertungen
- Servidor FTPDokument12 SeitenServidor FTPFrancisco Manuel García VallejoNoch keine Bewertungen
- 10 3 Fracciones ParcialesDokument11 Seiten10 3 Fracciones ParcialesHuayhuaC.EdgeNoch keine Bewertungen
- Herencia y PoliformismoDokument7 SeitenHerencia y PoliformismoAri Carranza0% (1)
- Interpolacion en MapleDokument23 SeitenInterpolacion en MapleManuel GarzaNoch keine Bewertungen
- 837-Texto Del Artículo-2440-4-10-20190607Dokument10 Seiten837-Texto Del Artículo-2440-4-10-20190607Aldo MedinaNoch keine Bewertungen
- Texto de Problemas Propuestos de Est DiscretasDokument42 SeitenTexto de Problemas Propuestos de Est Discretasanon_458511860100% (1)
- Estudio Sobre Las Tecnologías Biométricas Aplicadas A La SeguridadDokument100 SeitenEstudio Sobre Las Tecnologías Biométricas Aplicadas A La SeguridadINTECO100% (1)
- Ejercicios de Pérdidas y Ganacias (Docente)Dokument3 SeitenEjercicios de Pérdidas y Ganacias (Docente)Edgar SampayoNoch keine Bewertungen
- Apuntes Excel AvanzadoDokument25 SeitenApuntes Excel AvanzadoJhonny ValenciaNoch keine Bewertungen
- Temario Curso VIHDokument7 SeitenTemario Curso VIHJacqueline GranadosNoch keine Bewertungen
- Manual de Usuario Rslogix5000Dokument41 SeitenManual de Usuario Rslogix5000Manuel Chuquimarca100% (1)
- Ficha de Caracterización Del Proceso ComprasDokument2 SeitenFicha de Caracterización Del Proceso ComprasfabioNoch keine Bewertungen
- Foro M1Dokument1 SeiteForo M1Isabel RiveraNoch keine Bewertungen
- Formulas y Funciones en Excel Cindy Cecilia Huacchillo RiosDokument98 SeitenFormulas y Funciones en Excel Cindy Cecilia Huacchillo RiosPierre Marchena CalleNoch keine Bewertungen
- Tipos TablerosDokument17 SeitenTipos Tablerosargelis castilloNoch keine Bewertungen
- SUCOSOFT40Dokument8 SeitenSUCOSOFT40JUAN MIGUEL ARAMAYONoch keine Bewertungen
- Tesis Learning MachineDokument52 SeitenTesis Learning MachinedamianquijanoNoch keine Bewertungen
- Easy Law Penal & Procesal PenalDokument4 SeitenEasy Law Penal & Procesal PenalLa Ley100% (2)
- Testeo de Penetracion LinuxDokument28 SeitenTesteo de Penetracion LinuxWalter AlvarezNoch keine Bewertungen
- Correo InstitucionalDokument2 SeitenCorreo InstitucionalJose Manuel Araujo OrregoNoch keine Bewertungen