Das könnte Ihnen auch gefallen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Uais Transponder Fa-100 Operator's Guide: Turning On and OffDokument2 SeitenUais Transponder Fa-100 Operator's Guide: Turning On and OffNguyen Phuoc HoNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
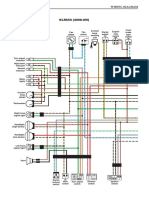
- Small Engine Repair Reference Center Wiring Diagram KawasakiDokument3 SeitenSmall Engine Repair Reference Center Wiring Diagram Kawasakiotto moranNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- GFK2749 - RX3i PSM PDFDokument100 SeitenGFK2749 - RX3i PSM PDFgabsNoch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Swann Enforcer 16-Channel, 12-Camera IndoorOutdoor Wired 1080p Full HD 2TB DVR Security System W Yard Stake & Wi-Fi ExtenderDokument1 SeiteSwann Enforcer 16-Channel, 12-Camera IndoorOutdoor Wired 1080p Full HD 2TB DVR Security System W Yard Stake & Wi-Fi ExtenderTata Zarabanda come brujoNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Drone Tech Project Organizational ChartDokument1 SeiteDrone Tech Project Organizational ChartEngr KushenscottNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- NT Usb DatasheetDokument1 SeiteNT Usb DatasheetxupaNoch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Stocktaking and Inventory Measurement As A Means To Improve Profitability - Susan RandallDokument11 SeitenStocktaking and Inventory Measurement As A Means To Improve Profitability - Susan RandallDani BatallasNoch keine Bewertungen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Historical Development of Computers FSC 113Dokument15 SeitenHistorical Development of Computers FSC 113amodusofiat77Noch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- 3638 - Simba M7 CDokument4 Seiten3638 - Simba M7 Cheleloy1234Noch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Wind Load: K Z S Z 0Dokument1 SeiteWind Load: K Z S Z 0MechanicalNoch keine Bewertungen
- Cloud Computing in Distributed System IJERTV1IS10199Dokument8 SeitenCloud Computing in Distributed System IJERTV1IS10199Nebula OriomNoch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Network Automation Technical EbookDokument20 SeitenNetwork Automation Technical EbookAamir MalikNoch keine Bewertungen
- 2023bske PCVL For Barangay 7216005 JatianDokument56 Seiten2023bske PCVL For Barangay 7216005 JatianBhin BhinNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Concrete Pipes and Portal Culverts HandbookDokument52 SeitenConcrete Pipes and Portal Culverts HandbookKenya Ayallew Asmare100% (3)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- NetGear Task TSK-MVC-20230109000274 13KRW0104Dokument3 SeitenNetGear Task TSK-MVC-20230109000274 13KRW0104Ir VanNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Bow Tle7 2022-2023Dokument7 SeitenBow Tle7 2022-2023Renato Reyes Jr.Noch keine Bewertungen
- Monty 1510: Spare Parts List Tire ChangerDokument24 SeitenMonty 1510: Spare Parts List Tire ChangerJonathan FullumNoch keine Bewertungen
- Step by Step - Deploy & Configure BranchCache in Windows Server 2012 R2 - Just A Random - Microsoft Server - Client Tech - Info..Dokument27 SeitenStep by Step - Deploy & Configure BranchCache in Windows Server 2012 R2 - Just A Random - Microsoft Server - Client Tech - Info..Bui Hong MyNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Review of Related LiteratureDokument3 SeitenReview of Related LiteratureJennifer L. LapizNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Astm A516 1990Dokument5 SeitenAstm A516 1990Indra Gugun GunawanNoch keine Bewertungen
- Trahair (2009) - Buckling Analysis Design of Steel FramesDokument5 SeitenTrahair (2009) - Buckling Analysis Design of Steel FramesGogyNoch keine Bewertungen
- HUP 112 Syllabus - SummerDokument2 SeitenHUP 112 Syllabus - SummerAngela MarisNoch keine Bewertungen
- CTSStenographerSecretarialAssistant (Eng) CTS NSQF-4Dokument40 SeitenCTSStenographerSecretarialAssistant (Eng) CTS NSQF-4Pta NahiNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Disks and Cloud StorageDokument12 SeitenDisks and Cloud StoragePradeepKumarMandavaNoch keine Bewertungen
- (PDF) 14 Websites To Download Research Paper For Free - 2022Dokument19 Seiten(PDF) 14 Websites To Download Research Paper For Free - 2022hatemaaNoch keine Bewertungen
- Cara Movavi Video EditorDokument4 SeitenCara Movavi Video EditornandaNoch keine Bewertungen
- After Resetting Frame Counters, Payload Is Shown On Gateway Traffic But Not in Application - Application Development - The Things NetworkDokument8 SeitenAfter Resetting Frame Counters, Payload Is Shown On Gateway Traffic But Not in Application - Application Development - The Things NetworkWilliam VizzottoNoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Marketing Strategy Dissertation ProposalDokument8 SeitenMarketing Strategy Dissertation ProposalSparkles Soft75% (4)
- Print LearnerDokument1 SeitePrint Learnersyed mithuNoch keine Bewertungen
- Course: EC2P001 Introduction To Electronics Lab: Indian Institute of Technology Bhubaneswar School of Electrical ScienceDokument5 SeitenCourse: EC2P001 Introduction To Electronics Lab: Indian Institute of Technology Bhubaneswar School of Electrical ScienceAnik ChaudhuriNoch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)