Das könnte Ihnen auch gefallen
- Central Limit TheoremDokument38 SeitenCentral Limit TheoremNiraj Gupta100% (2)
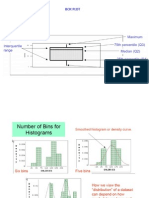
- Bio-Stats Step 3Dokument9 SeitenBio-Stats Step 3S100% (4)
- The Impatient Trader by Derek Evans Founder of Equitimax Insiders CircleDokument106 SeitenThe Impatient Trader by Derek Evans Founder of Equitimax Insiders CircleEquitimax Insiders Circle100% (1)
- Lecture 3 - Sampling-Distribution & Central Limit TheoremDokument5 SeitenLecture 3 - Sampling-Distribution & Central Limit TheoremNilo Galvez Jr.Noch keine Bewertungen
- Point and Interval Estimation-26!08!2011Dokument28 SeitenPoint and Interval Estimation-26!08!2011Syed OvaisNoch keine Bewertungen
- Confidence IntervalDokument19 SeitenConfidence IntervalAjinkya Adhikari100% (1)
- Normal Binomial PoissonDokument12 SeitenNormal Binomial Poissonamit447100% (1)
- (RILEM Proceedings 30) Pigeon, Michel_ Marchand, J._ Setzer, M-Freeze-thaw Durability of Concrete _ Proceedings of the International Workshop in the Resistance of Concrete to Scaling Due to Freezing i (1)Dokument323 Seiten(RILEM Proceedings 30) Pigeon, Michel_ Marchand, J._ Setzer, M-Freeze-thaw Durability of Concrete _ Proceedings of the International Workshop in the Resistance of Concrete to Scaling Due to Freezing i (1)Leonel MedinaNoch keine Bewertungen
- Normal Distribution and Probability: Mate14 - Design and Analysis of Experiments in Materials EngineeringDokument23 SeitenNormal Distribution and Probability: Mate14 - Design and Analysis of Experiments in Materials EngineeringsajeerNoch keine Bewertungen
- 3 UnequalDokument7 Seiten3 UnequalRicardo TavaresNoch keine Bewertungen
- Inquiries, Investigations and ImmersionsDokument220 SeitenInquiries, Investigations and Immersionschael100% (4)
- Applied Multidimensional Scaling by Ingwer Borg Patrick J F Groenen Patrick Mair PDFDokument119 SeitenApplied Multidimensional Scaling by Ingwer Borg Patrick J F Groenen Patrick Mair PDFvoulgeorNoch keine Bewertungen
- FF Analysis of The Effect of Temperature On Insects in Flight Taylor 1963Dokument20 SeitenFF Analysis of The Effect of Temperature On Insects in Flight Taylor 1963jessupaNoch keine Bewertungen
- Probility DistributionDokument41 SeitenProbility Distributionnitindhiman30Noch keine Bewertungen
- Module 2 in IStat 1 Probability DistributionDokument6 SeitenModule 2 in IStat 1 Probability DistributionJefferson Cadavos CheeNoch keine Bewertungen
- שפות סימולציה- הרצאה 12 - Output Data Analysis IDokument49 Seitenשפות סימולציה- הרצאה 12 - Output Data Analysis IRonNoch keine Bewertungen
- Confidence Intervals and Hypothesis Tests For MeansDokument40 SeitenConfidence Intervals and Hypothesis Tests For MeansJosh PotashNoch keine Bewertungen
- SamplingDistributions LectureDokument13 SeitenSamplingDistributions LectureJeanpierre AklNoch keine Bewertungen
- Insurance Pricing Basic Statistical PrinciplesDokument33 SeitenInsurance Pricing Basic Statistical PrinciplesEsra Gunes YildizNoch keine Bewertungen
- Random Variable & Probability DistributionDokument48 SeitenRandom Variable & Probability DistributionRISHAB NANGIANoch keine Bewertungen
- Sampling Distributions of Statistics: Corresponds To Chapter 5 of Tamhaneand DunlopDokument36 SeitenSampling Distributions of Statistics: Corresponds To Chapter 5 of Tamhaneand DunlopLuis LoredoNoch keine Bewertungen
- S2 Revision NotesDokument2 SeitenS2 Revision NotesimnulNoch keine Bewertungen
- Estimation 1Dokument35 SeitenEstimation 1Fun Toosh345Noch keine Bewertungen
- Quant Part2Dokument40 SeitenQuant Part2TAKESHI OMAR CASTRO REYESNoch keine Bewertungen
- f (x) ≥0, Σf (x) =1. We can describe a discrete probability distribution with a table, graph,Dokument4 Seitenf (x) ≥0, Σf (x) =1. We can describe a discrete probability distribution with a table, graph,missy74Noch keine Bewertungen
- Inferential Statistic: 1 Estimation of A Population MeanDokument8 SeitenInferential Statistic: 1 Estimation of A Population MeanshahzebNoch keine Bewertungen
- Faculty of Information Science & Technology (FIST) : PSM 0325 Introduction To Probability and StatisticsDokument7 SeitenFaculty of Information Science & Technology (FIST) : PSM 0325 Introduction To Probability and StatisticsMATHAVAN A L KRISHNANNoch keine Bewertungen
- PSYCH 240: Statistics For Psychologists: Interval Estimation: Understanding The T DistributionDokument44 SeitenPSYCH 240: Statistics For Psychologists: Interval Estimation: Understanding The T DistributionSatish NamjoshiNoch keine Bewertungen
- Tatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialDokument15 SeitenTatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialPrima JoeNoch keine Bewertungen
- Lc07 SL Estimation - PPT - 0Dokument48 SeitenLc07 SL Estimation - PPT - 0Deni ChanNoch keine Bewertungen
- Confidence Interval EstimationDokument62 SeitenConfidence Interval EstimationVikrant LadNoch keine Bewertungen
- Lec 3 - Continuous ProbabilitiesDokument9 SeitenLec 3 - Continuous ProbabilitiesCharles QuahNoch keine Bewertungen
- Inferences Based On A Single Sample: Confidence Intervals and Tests of Hypothesis (9 Hours)Dokument71 SeitenInferences Based On A Single Sample: Confidence Intervals and Tests of Hypothesis (9 Hours)Kato AkikoNoch keine Bewertungen
- Chapter06 091211160706 Phpapp01Dokument42 SeitenChapter06 091211160706 Phpapp01shan4600Noch keine Bewertungen
- 3 DistributionsDokument42 Seiten3 DistributionsAngga Ade PutraNoch keine Bewertungen
- CHAPTER 5 - Sampling Distributions Sections: 5.1 & 5.2: AssumptionsDokument9 SeitenCHAPTER 5 - Sampling Distributions Sections: 5.1 & 5.2: Assumptionssound05Noch keine Bewertungen
- Mechanical MeasurementsDokument22 SeitenMechanical MeasurementsBanamali MohantaNoch keine Bewertungen
- ASPjskjkjksnkxdqlcwlDokument34 SeitenASPjskjkjksnkxdqlcwlSonuBajajNoch keine Bewertungen
- Sampling Dist 18 Aug 10Dokument2 SeitenSampling Dist 18 Aug 10GolamKibriabipuNoch keine Bewertungen
- The Practice of Statistic For Business and Economics Is An IntroductoryDokument15 SeitenThe Practice of Statistic For Business and Economics Is An IntroductoryuiysdfiyuiNoch keine Bewertungen
- Group 2Dokument65 SeitenGroup 2Fazal McphersonNoch keine Bewertungen
- Sampling DistributionDokument22 SeitenSampling Distributionumar2040Noch keine Bewertungen
- STATISTICS FOR BUSINESS - CHAP05 - Sampling and Sampling Distribution PDFDokument3 SeitenSTATISTICS FOR BUSINESS - CHAP05 - Sampling and Sampling Distribution PDFHoang NguyenNoch keine Bewertungen
- STATISTICSDokument8 SeitenSTATISTICSmesfindukedomNoch keine Bewertungen
- Statistics For Business and Economics: Module 1:probability Theory and Statistical Inference Spring 2010Dokument20 SeitenStatistics For Business and Economics: Module 1:probability Theory and Statistical Inference Spring 2010S.WaqquasNoch keine Bewertungen
- Value of Z Area Between Z and - Z Area From Z ToDokument3 SeitenValue of Z Area Between Z and - Z Area From Z Topatricia_castillo_49Noch keine Bewertungen
- Business Statistics - Session Probability DistributionDokument21 SeitenBusiness Statistics - Session Probability Distributionmukul3087_305865623Noch keine Bewertungen
- Normal Dist - Student LectureDokument43 SeitenNormal Dist - Student LecturesovolojikNoch keine Bewertungen
- AP Statistics - Chapter 8 Notes: Estimating With Confidence 8.1 - Confidence Interval BasicsDokument2 SeitenAP Statistics - Chapter 8 Notes: Estimating With Confidence 8.1 - Confidence Interval BasicsRhivia LoratNoch keine Bewertungen
- Module 6-1Dokument21 SeitenModule 6-1Ho Uyen Thu NguyenNoch keine Bewertungen
- IISER BiostatDokument87 SeitenIISER BiostatPrithibi Bodle GacheNoch keine Bewertungen
- Lecture 03 & 04 EC5002 CLT & Normal Distribution 2015-16Dokument13 SeitenLecture 03 & 04 EC5002 CLT & Normal Distribution 2015-16nishit0157623637Noch keine Bewertungen
- Sampling Distributions of Sample MeansDokument7 SeitenSampling Distributions of Sample MeansDaryl Vincent RiveraNoch keine Bewertungen
- Statistical Inference: Prepared By: Antonio E. Chan, M.DDokument227 SeitenStatistical Inference: Prepared By: Antonio E. Chan, M.Dश्रीकांत शरमाNoch keine Bewertungen
- Review of StatisticsDokument36 SeitenReview of StatisticsJessica AngelinaNoch keine Bewertungen
- DistributionDokument6 SeitenDistributionRamos LeonaNoch keine Bewertungen
- Notes ch3 Sampling DistributionsDokument20 SeitenNotes ch3 Sampling DistributionsErkin DNoch keine Bewertungen
- 6 Monte Carlo Simulation: Exact SolutionDokument10 Seiten6 Monte Carlo Simulation: Exact SolutionYuri PazaránNoch keine Bewertungen
- STAT 241 - Unit 5 NotesDokument9 SeitenSTAT 241 - Unit 5 NotesCassie LemonsNoch keine Bewertungen
- Introduction To The T-Statistic: PSY295 Spring 2003 SummerfeltDokument19 SeitenIntroduction To The T-Statistic: PSY295 Spring 2003 SummerfeltEddy MwachenjeNoch keine Bewertungen
- Unit-3 Methods in Social PsychologyDokument21 SeitenUnit-3 Methods in Social PsychologyAnanya NarangNoch keine Bewertungen
- CyfDokument13 SeitenCyfdeepakNoch keine Bewertungen
- Dont Remove 301Dokument524 SeitenDont Remove 301deevan30Noch keine Bewertungen
- Mender MouradDokument15 SeitenMender Mouradghassen laouiniNoch keine Bewertungen
- Malina1996 PDFDokument11 SeitenMalina1996 PDFNancy MoralesNoch keine Bewertungen
- A Statistical Analysis of GDP and Final Consumption Using Simple Linear Regression. The Case of Romania 1990-2010Dokument7 SeitenA Statistical Analysis of GDP and Final Consumption Using Simple Linear Regression. The Case of Romania 1990-2010Nouf ANoch keine Bewertungen
- Modeling of Liquid-Liquid Extraction Column: A Review: Reviews in Chemical Engineering January 2000Dokument51 SeitenModeling of Liquid-Liquid Extraction Column: A Review: Reviews in Chemical Engineering January 2000Atha Pahlevi PutraNoch keine Bewertungen
- The Strengths and Difficulties Questionnaire: A Research NoteDokument7 SeitenThe Strengths and Difficulties Questionnaire: A Research NoteAnum AdeelNoch keine Bewertungen
- Modelling in RDokument47 SeitenModelling in RtrNoch keine Bewertungen
- Introduction To Panel Data AnalysisDokument18 SeitenIntroduction To Panel Data Analysissmazadamha sulaimanNoch keine Bewertungen
- Chapter 4Dokument32 SeitenChapter 4camNoch keine Bewertungen
- Multivariate Linear RegressionDokument30 SeitenMultivariate Linear RegressionesjaiNoch keine Bewertungen
- Two Dimensional Random Variables 1Dokument6 SeitenTwo Dimensional Random Variables 1murugesanvNoch keine Bewertungen
- How Does Searching For Health Information On The Internet Affect Individuals' Demand For HealthDokument8 SeitenHow Does Searching For Health Information On The Internet Affect Individuals' Demand For HealthHadrianti LasariNoch keine Bewertungen
- Group Project STA 108Dokument18 SeitenGroup Project STA 108Cassy0% (1)
- Hubungan Pemahaman Nilai-Nilai Pancasila Dengan Karakter Siswa Di SMP Swasta HKBP Belawan Tahun Ajaran 2019/2020Dokument22 SeitenHubungan Pemahaman Nilai-Nilai Pancasila Dengan Karakter Siswa Di SMP Swasta HKBP Belawan Tahun Ajaran 2019/2020ElishaNoch keine Bewertungen
- Project STA108Dokument25 SeitenProject STA108meliszaNoch keine Bewertungen
- Correlation and Linear RegressionDokument17 SeitenCorrelation and Linear RegressionMa Joanna VecinoNoch keine Bewertungen
- Modelling The Barriers of Lean Six Sigma For Indian Micro-Small Medium EnterprisesDokument23 SeitenModelling The Barriers of Lean Six Sigma For Indian Micro-Small Medium EnterprisesPratikJagtapNoch keine Bewertungen
- This Content Downloaded From 132.174.250.76 On Fri, 04 Sep 2020 01:33:22 UTCDokument42 SeitenThis Content Downloaded From 132.174.250.76 On Fri, 04 Sep 2020 01:33:22 UTCBenjamin NaulaNoch keine Bewertungen
- Factors Affecting1Dokument23 SeitenFactors Affecting1TopArt Tân BìnhNoch keine Bewertungen
- The Quiet Eye - Its Role in SquashDokument4 SeitenThe Quiet Eye - Its Role in SquashIJAR JOURNALNoch keine Bewertungen
- Factors Affecting Organizational Commitment Among Lecturers in Higher Educational Institution in Malaysia PDFDokument16 SeitenFactors Affecting Organizational Commitment Among Lecturers in Higher Educational Institution in Malaysia PDFDr-Malkah Noor100% (1)
- Algebra 1 Review Through Jan 2016Dokument8 SeitenAlgebra 1 Review Through Jan 2016api-262532023Noch keine Bewertungen