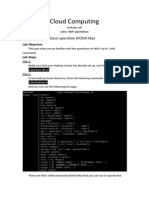
Das könnte Ihnen auch gefallen
- Practical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inDokument61 SeitenPractical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inParthNoch keine Bewertungen
- Import Import Import Import Import Import Import Import Public Class Extends ImplementsDokument7 SeitenImport Import Import Import Import Import Import Import Public Class Extends ImplementsSARAVANANNoch keine Bewertungen
- BDA Lab 8 ManualDokument7 SeitenBDA Lab 8 ManualMydah NasirNoch keine Bewertungen
- Tutorial-Counting Words in File (S) Using Mapreduce: PrerequisitesDokument11 SeitenTutorial-Counting Words in File (S) Using Mapreduce: PrerequisitessaiconzeNoch keine Bewertungen
- Step 2 - First MapReduce ProgramDokument25 SeitenStep 2 - First MapReduce ProgramSantosh Kumar DesaiNoch keine Bewertungen
- BDT Lab ManualDokument48 SeitenBDT Lab ManualVishnu Vardhan HNoch keine Bewertungen
- PalakDokument10 SeitenPalakDolly MehraNoch keine Bewertungen
- Word Count Program To Demonstrate The Use of Map and Reduce TasksDokument5 SeitenWord Count Program To Demonstrate The Use of Map and Reduce Tasksriya kNoch keine Bewertungen
- BDA LabManualDokument20 SeitenBDA LabManualposprojectzNoch keine Bewertungen
- Steps: /usr/lib/hadoop-0.20/ Usr/lib/hadoop-0.20/libDokument4 SeitenSteps: /usr/lib/hadoop-0.20/ Usr/lib/hadoop-0.20/libKarthick JothivelNoch keine Bewertungen
- WordCount Program Hadoop Task 2Dokument7 SeitenWordCount Program Hadoop Task 220261A6757 VIJAYAGIRI ANIL KUMARNoch keine Bewertungen
- Setting Up Eclipse:: Codelab 1 Introduction To The Hadoop Environment (Version 0.17.0)Dokument9 SeitenSetting Up Eclipse:: Codelab 1 Introduction To The Hadoop Environment (Version 0.17.0)K V D SagarNoch keine Bewertungen
- Bda LabDokument47 SeitenBda LabpawanNoch keine Bewertungen
- MapReduce Word Count ProgramDokument6 SeitenMapReduce Word Count ProgramshaliniiiiNoch keine Bewertungen
- Lab ManualDokument86 SeitenLab Manualpthuynh709Noch keine Bewertungen
- Hadoop Administrator Training - Lab Hand BookDokument12 SeitenHadoop Administrator Training - Lab Hand BookdebkrcNoch keine Bewertungen
- Run WordcountDokument3 SeitenRun WordcountKhushi PatilNoch keine Bewertungen
- Lab HadoopDokument7 SeitenLab HadoopTev WallaceNoch keine Bewertungen
- Import Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsDokument6 SeitenImport Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsSARAVANANNoch keine Bewertungen
- Execute Java Map Reduce Sample Using EclipseDokument9 SeitenExecute Java Map Reduce Sample Using EclipseArjun SNoch keine Bewertungen
- Experiment: Word Count in HadoopDokument12 SeitenExperiment: Word Count in HadoopSAMINA ATTARINoch keine Bewertungen
- CC Hadoop LabDokument6 SeitenCC Hadoop LabClaudia ArdeleanNoch keine Bewertungen
- Hadoop and Map ReduceDokument27 SeitenHadoop and Map Reducearshpreetmundra14Noch keine Bewertungen
- Hands-On Exercises With Big Data: Lab Sheet 1: Getting Started With Mapreduce and HadoopDokument14 SeitenHands-On Exercises With Big Data: Lab Sheet 1: Getting Started With Mapreduce and HadoopmoorthykemNoch keine Bewertungen
- BDALab Assn4Dokument9 SeitenBDALab Assn4Deepti AgrawalNoch keine Bewertungen
- Exp 4 Word CountDokument4 SeitenExp 4 Word Countmunish kumar agarwalNoch keine Bewertungen
- Lab2 WCDokument2 SeitenLab2 WCwisesharkwhaleNoch keine Bewertungen
- Hands OnDokument26 SeitenHands OnAshok Kumar K RNoch keine Bewertungen
- Run Python MapReduce On Local Docker Hadoop Cluster - DEV CommunityDokument5 SeitenRun Python MapReduce On Local Docker Hadoop Cluster - DEV CommunityAhmed MohamedNoch keine Bewertungen
- MR YARN - Lab 2 - Cloud - Updated-V2.0Dokument22 SeitenMR YARN - Lab 2 - Cloud - Updated-V2.0bender1686Noch keine Bewertungen
- Big Data ManualDokument19 SeitenBig Data ManualMadhubala JNoch keine Bewertungen
- Assignment 11 DSBDADokument4 SeitenAssignment 11 DSBDADARSHAN JADHAVNoch keine Bewertungen
- Trắc Nghiệm Big dataDokument69 SeitenTrắc Nghiệm Big dataMinhNoch keine Bewertungen
- Big Data & Analytics Lab ManualDokument51 SeitenBig Data & Analytics Lab ManualSathishNoch keine Bewertungen
- BDALab Assn4Dokument9 SeitenBDALab Assn4Deepti AgrawalNoch keine Bewertungen
- Big Data Fundamentals and Platforms Assginment 3Dokument6 SeitenBig Data Fundamentals and Platforms Assginment 3sagar srivastavaNoch keine Bewertungen
- Hadoop Single Node Cluster Setup StepsDokument7 SeitenHadoop Single Node Cluster Setup StepsShushrutha Reddy KNoch keine Bewertungen
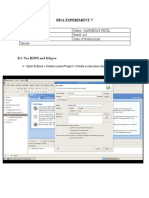
- Bda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeDokument8 SeitenBda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeAlkaNoch keine Bewertungen
- Bda Unit-IiiDokument42 SeitenBda Unit-IiirohithatimsiNoch keine Bewertungen
- Hadoop Installation Step by StepDokument6 SeitenHadoop Installation Step by StepUmesh NagarNoch keine Bewertungen
- DSBDSAssingment 11Dokument20 SeitenDSBDSAssingment 11403 Chaudhari Sanika SagarNoch keine Bewertungen
- CS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011Dokument13 SeitenCS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011smitanair143Noch keine Bewertungen
- Big Data FileDokument16 SeitenBig Data FileArnav ShrivastavaNoch keine Bewertungen
- Bda LabDokument37 SeitenBda LabDhanush KumarNoch keine Bewertungen
- Hadoop Installation StepsDokument10 SeitenHadoop Installation StepsMousoomi BaruahNoch keine Bewertungen
- Activity 2Dokument31 SeitenActivity 2patilbhavesh991209Noch keine Bewertungen
- Assignment 2-033Dokument13 SeitenAssignment 2-033DHARSHANA C PNoch keine Bewertungen
- HadoopDokument51 SeitenHadoopRavitej TadinadaNoch keine Bewertungen
- Cloud Lab Exe 6,7,8Dokument17 SeitenCloud Lab Exe 6,7,8Vasanth AnanthNoch keine Bewertungen
- NotesDokument53 SeitenNotesRadheshyam ShahNoch keine Bewertungen
- Inverted IndexDokument9 SeitenInverted IndexReaderRatNoch keine Bewertungen
- Big Data Lab Manual and SyllabusDokument71 SeitenBig Data Lab Manual and Syllabusstartechbyjus123Noch keine Bewertungen
- 12 CodigoNetbeansDokument5 Seiten12 CodigoNetbeansMiguel AngelNoch keine Bewertungen
- Hadoop Installation Step by StepDokument8 SeitenHadoop Installation Step by StepRamkumar GopalNoch keine Bewertungen
- Hadoop InstallDokument19 SeitenHadoop InstallLâm LươngNoch keine Bewertungen
- Hadoop Installation StepsDokument16 SeitenHadoop Installation StepsSrinivasa Rao TNoch keine Bewertungen
- BDM Lab Manual 2Dokument4 SeitenBDM Lab Manual 2Vijay ManoNoch keine Bewertungen
- Kcs 061 PPT Unit 2Dokument56 SeitenKcs 061 PPT Unit 2PRACHI ROSHANNoch keine Bewertungen
- PHP Package Mastery: 100 Essential Tools in One Hour - 2024 EditionVon EverandPHP Package Mastery: 100 Essential Tools in One Hour - 2024 EditionNoch keine Bewertungen
- JAVA Coding Interview Questions and AnswersDokument247 SeitenJAVA Coding Interview Questions and AnswersKaushal Prajapati100% (5)
- Network Security SUMSDokument9 SeitenNetwork Security SUMSKaushal Prajapati0% (1)
- Bajaj Allianz General Insurance Company LTD.: Summary of A Policy CoverageDokument1 SeiteBajaj Allianz General Insurance Company LTD.: Summary of A Policy CoverageKaushal PrajapatiNoch keine Bewertungen
- Unit 7Dokument12 SeitenUnit 7Kaushal PrajapatiNoch keine Bewertungen
- Web Technology & ProgrammingDokument2 SeitenWeb Technology & ProgrammingKaushal PrajapatiNoch keine Bewertungen
- Service Manual: Model: R410, RB410, RV410, RD410 SeriesDokument116 SeitenService Manual: Model: R410, RB410, RV410, RD410 SeriesJorge Eustaquio da SilvaNoch keine Bewertungen
- Sign Language To Speech ConversionDokument6 SeitenSign Language To Speech ConversionGokul RajaNoch keine Bewertungen
- Hitt PPT 12e ch08-SMDokument32 SeitenHitt PPT 12e ch08-SMHananie NanieNoch keine Bewertungen
- Hardware Architecture For Nanorobot Application in Cancer TherapyDokument7 SeitenHardware Architecture For Nanorobot Application in Cancer TherapyCynthia CarolineNoch keine Bewertungen
- Quantity DiscountDokument22 SeitenQuantity Discountkevin royNoch keine Bewertungen
- Ficha Tecnica 320D3 GCDokument12 SeitenFicha Tecnica 320D3 GCanahdezj88Noch keine Bewertungen
- AkDokument7 SeitenAkDavid BakcyumNoch keine Bewertungen
- Nisha Rough DraftDokument50 SeitenNisha Rough DraftbharthanNoch keine Bewertungen
- Pega AcademyDokument10 SeitenPega AcademySasidharNoch keine Bewertungen
- Modulation and Frequency Synthesis X Digital Wireless RadioDokument233 SeitenModulation and Frequency Synthesis X Digital Wireless Radiolcnblzr3877Noch keine Bewertungen
- Elliot WaveDokument11 SeitenElliot WavevikramNoch keine Bewertungen
- EW160 AlarmsDokument12 SeitenEW160 AlarmsIgor MaricNoch keine Bewertungen
- PartitionDokument5 SeitenPartitionKotagiri AravindNoch keine Bewertungen
- United States v. Manuel Sosa, 959 F.2d 232, 4th Cir. (1992)Dokument2 SeitenUnited States v. Manuel Sosa, 959 F.2d 232, 4th Cir. (1992)Scribd Government DocsNoch keine Bewertungen
- Residential BuildingDokument5 SeitenResidential Buildingkamaldeep singhNoch keine Bewertungen
- Belimo Fire & Smoke Damper ActuatorsDokument16 SeitenBelimo Fire & Smoke Damper ActuatorsSrikanth TagoreNoch keine Bewertungen
- Sangeetahealingtemples Com Tarot Card Reading Course in UsaDokument3 SeitenSangeetahealingtemples Com Tarot Card Reading Course in UsaSangeetahealing templesNoch keine Bewertungen
- Powerpoint Presentation R.A 7877 - Anti Sexual Harassment ActDokument14 SeitenPowerpoint Presentation R.A 7877 - Anti Sexual Harassment ActApple100% (1)
- We Move You. With Passion.: YachtDokument27 SeitenWe Move You. With Passion.: YachthatelNoch keine Bewertungen
- Circuitos Digitales III: #IncludeDokument2 SeitenCircuitos Digitales III: #IncludeCristiamNoch keine Bewertungen
- Windsor Machines LimitedDokument12 SeitenWindsor Machines LimitedAlaina LongNoch keine Bewertungen
- Proposal For Chemical Shed at Keraniganj - 15.04.21Dokument14 SeitenProposal For Chemical Shed at Keraniganj - 15.04.21HabibNoch keine Bewertungen
- Health, Safety & Environment: Refer NumberDokument2 SeitenHealth, Safety & Environment: Refer NumbergilNoch keine Bewertungen
- Sealant Solutions: Nitoseal Thioflex FlamexDokument16 SeitenSealant Solutions: Nitoseal Thioflex FlamexBhagwat PatilNoch keine Bewertungen
- SMK Techno ProjectDokument36 SeitenSMK Techno Projectpraburaj619Noch keine Bewertungen
- FBW Manual-Jan 2012-Revised and Corrected CS2Dokument68 SeitenFBW Manual-Jan 2012-Revised and Corrected CS2Dinesh CandassamyNoch keine Bewertungen
- Product Manual: Panel Mounted ControllerDokument271 SeitenProduct Manual: Panel Mounted ControllerLEONARDO FREITAS COSTANoch keine Bewertungen
- COGELSA Food Industry Catalogue LDDokument9 SeitenCOGELSA Food Industry Catalogue LDandriyanto.wisnuNoch keine Bewertungen
- SettingsDokument3 SeitenSettingsrusil.vershNoch keine Bewertungen
- Human Resource Management by John Ivancevich PDFDokument656 SeitenHuman Resource Management by John Ivancevich PDFHaroldM.MagallanesNoch keine Bewertungen