Das könnte Ihnen auch gefallen
- Marx Nov 7 OutlineDokument10 SeitenMarx Nov 7 OutlineAlex NyeNoch keine Bewertungen
- IR Section NotesDokument50 SeitenIR Section NotesAlex NyeNoch keine Bewertungen
- PiracyDokument9 SeitenPiracyAlex NyeNoch keine Bewertungen
- CH 4Dokument74 SeitenCH 4Nathalie FytrouNoch keine Bewertungen
- Poverty Brazil Amun 2013Dokument1 SeitePoverty Brazil Amun 2013Alex NyeNoch keine Bewertungen
- HW1Dokument4 SeitenHW1Alex NyeNoch keine Bewertungen
- AP AustenDokument5 SeitenAP AustenAlex NyeNoch keine Bewertungen
- Model United Nations HandbookDokument29 SeitenModel United Nations HandbookGeorge Chen100% (19)
- Latin AmericaDokument15 SeitenLatin AmericaAlex NyeNoch keine Bewertungen
- South SudanDokument2 SeitenSouth SudanAlex NyeNoch keine Bewertungen
- MUN HandbookDokument52 SeitenMUN HandbookSyasya SyahieraNoch keine Bewertungen
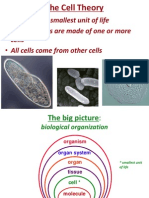
- Cells Are The Smallest Unit of Life - All Organisms Are Made of One or More - All Cells Come From Other CellsDokument16 SeitenCells Are The Smallest Unit of Life - All Organisms Are Made of One or More - All Cells Come From Other CellsAlex NyeNoch keine Bewertungen
- Behavioral Ecology 2010 Rantala 419 23Dokument5 SeitenBehavioral Ecology 2010 Rantala 419 23Alex NyeNoch keine Bewertungen
- Why The WestDokument2 SeitenWhy The WestAlex NyeNoch keine Bewertungen
- Finals Round 2Dokument12 SeitenFinals Round 2Alex NyeNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5784)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (890)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (72)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- SFA160Dokument5 SeitenSFA160scamalNoch keine Bewertungen
- Resp Part 4Dokument95 SeitenResp Part 4Kristian CadaNoch keine Bewertungen
- PanimulaDokument4 SeitenPanimulaCharmayne DatorNoch keine Bewertungen
- Antenatal AssessmentDokument9 SeitenAntenatal Assessmentjyoti singhNoch keine Bewertungen
- Amity Online Exam OdlDokument14 SeitenAmity Online Exam OdlAbdullah Holif0% (1)
- Hmdu - EnglishDokument20 SeitenHmdu - EnglishAbdulaziz SeikoNoch keine Bewertungen
- 42U System Cabinet GuideDokument68 Seiten42U System Cabinet GuideGerman AndersNoch keine Bewertungen
- British and American Culture Marking RubricDokument5 SeitenBritish and American Culture Marking RubricAn Ho LongNoch keine Bewertungen
- Case Briefing and Case SynthesisDokument3 SeitenCase Briefing and Case SynthesisKai RaguindinNoch keine Bewertungen
- IJRP 2018 Issue 8 Final REVISED 2 PDFDokument25 SeitenIJRP 2018 Issue 8 Final REVISED 2 PDFCarlos VegaNoch keine Bewertungen
- System Software Module 3: Machine-Dependent Assembler FeaturesDokument28 SeitenSystem Software Module 3: Machine-Dependent Assembler Featuresvidhya_bineeshNoch keine Bewertungen
- MARCOMDokument35 SeitenMARCOMDrei SalNoch keine Bewertungen
- Morpho Full Fix 2Dokument9 SeitenMorpho Full Fix 2Dayu AnaNoch keine Bewertungen
- The Ideal Structure of ZZ (Alwis)Dokument8 SeitenThe Ideal Structure of ZZ (Alwis)yacp16761Noch keine Bewertungen
- Explore Spanish Lesson Plan - AnimalsDokument8 SeitenExplore Spanish Lesson Plan - Animalsapi-257582917Noch keine Bewertungen
- (Nima Naghibi) Rethinking Global Sisterhood Weste PDFDokument220 Seiten(Nima Naghibi) Rethinking Global Sisterhood Weste PDFEdson Neves Jr.100% (1)
- Clinnic Panel Penag 2014Dokument8 SeitenClinnic Panel Penag 2014Cikgu Mohd NoorNoch keine Bewertungen
- Informed Consent: Ghaiath M. A. HusseinDokument26 SeitenInformed Consent: Ghaiath M. A. HusseinDocAxi Maximo Jr AxibalNoch keine Bewertungen
- We Generally View Objects As Either Moving or Not MovingDokument11 SeitenWe Generally View Objects As Either Moving or Not MovingMarietoni D. QueseaNoch keine Bewertungen
- Open MPDokument30 SeitenOpen MPmacngocthanNoch keine Bewertungen
- New Microwave Lab ManualDokument35 SeitenNew Microwave Lab ManualRadhikaNoch keine Bewertungen
- DOW™ HDPE 05962B: High Density Polyethylene ResinDokument3 SeitenDOW™ HDPE 05962B: High Density Polyethylene ResinFredo NLNoch keine Bewertungen
- Predictive Analytics: QM901.1x Prof U Dinesh Kumar, IIMBDokument36 SeitenPredictive Analytics: QM901.1x Prof U Dinesh Kumar, IIMBVenkata Nelluri PmpNoch keine Bewertungen
- Broom Manufacture Machine: StartDokument62 SeitenBroom Manufacture Machine: StartHaziq PazliNoch keine Bewertungen
- 1 CAT O&M Manual G3500 Engine 0Dokument126 Seiten1 CAT O&M Manual G3500 Engine 0Hassan100% (1)
- "The Meeting of Meditative Disciplines and Western Psychology" Roger Walsh Shauna L. ShapiroDokument13 Seiten"The Meeting of Meditative Disciplines and Western Psychology" Roger Walsh Shauna L. ShapiroSayako87Noch keine Bewertungen
- Mpce 24Dokument39 SeitenMpce 24Sachin Mehla0% (1)
- Technical Bro A4 UK LR NEW v2Dokument45 SeitenTechnical Bro A4 UK LR NEW v2Roxana NegoitaNoch keine Bewertungen
- LTC2410 Datasheet and Product Info - Analog DevicesDokument6 SeitenLTC2410 Datasheet and Product Info - Analog DevicesdonatoNoch keine Bewertungen
- Ethics Book of TAMIL NADU HSC 11th Standard Tamil MediumDokument140 SeitenEthics Book of TAMIL NADU HSC 11th Standard Tamil MediumkumardjayaNoch keine Bewertungen