Das könnte Ihnen auch gefallen
- Le Plan Marketing PDFDokument240 SeitenLe Plan Marketing PDFRachid El Faiz100% (1)
- Final Rapport PFEDokument118 SeitenFinal Rapport PFEKawtar L AzaarNoch keine Bewertungen
- QCM Langage C PDFDokument6 SeitenQCM Langage C PDFfati83% (18)
- Corrige QCM Gestion SI Interne 2009Dokument17 SeitenCorrige QCM Gestion SI Interne 2009ahlam_170750% (2)
- Guide GEDDokument6 SeitenGuide GEDKawtar L AzaarNoch keine Bewertungen
- Exam JEE 2008-2009 CorrigeDokument9 SeitenExam JEE 2008-2009 Corrigetimaa_2020100% (2)
- Réussir Vos Projets Daffaires en AfriqueDokument560 SeitenRéussir Vos Projets Daffaires en AfriqueBuoreima CisseNoch keine Bewertungen
- Mon Projet de RechercheDokument5 SeitenMon Projet de RechercheMehdi AlpesNoch keine Bewertungen
- coursExcelVBA2012 2013Dokument46 SeitencoursExcelVBA2012 2013Jlassi Hamma KortoubliNoch keine Bewertungen
- Variable Etat PDFDokument103 SeitenVariable Etat PDFIRBAHNoch keine Bewertungen
- Cours Java Sockets PDFDokument36 SeitenCours Java Sockets PDFKawtar L AzaarNoch keine Bewertungen
- Béton de SableDokument121 SeitenBéton de Sableomarout100% (4)
- Atelier 1Dokument2 SeitenAtelier 1lafdaliNoch keine Bewertungen
- ACP M2 Print PDFDokument32 SeitenACP M2 Print PDFJunior Ebong Moudoubou100% (1)
- Présentation Classification - ENCG - S5.pdf Version 1Dokument62 SeitenPrésentation Classification - ENCG - S5.pdf Version 1Hasnae BlNoch keine Bewertungen
- Chapitre3 ClassificationDokument33 SeitenChapitre3 ClassificationRa NimNoch keine Bewertungen
- Classification Ascendante HiérarchiqueDokument6 SeitenClassification Ascendante HiérarchiqueParfait AhohoundoNoch keine Bewertungen
- AcpDokument26 SeitenAcpAmine RakichiNoch keine Bewertungen
- Resume AfcDokument4 SeitenResume AfcAbdallahi SidiNoch keine Bewertungen
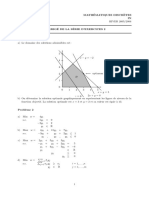
- Revision Simplexe PDFDokument75 SeitenRevision Simplexe PDFYassminaNoch keine Bewertungen
- D317 - Emiage - Décembre 2018Dokument1 SeiteD317 - Emiage - Décembre 2018LeoNoch keine Bewertungen
- GP Chp.1Dokument20 SeitenGP Chp.1Bouchra GhandourNoch keine Bewertungen
- 2 PhasesDokument6 Seiten2 Phasesياسين بوعيشيNoch keine Bewertungen
- TD Statistique Chap 8Dokument4 SeitenTD Statistique Chap 8MEHDINoch keine Bewertungen
- Cours VBA - Les Boucles (Exercice)Dokument5 SeitenCours VBA - Les Boucles (Exercice)boy jorgNoch keine Bewertungen
- Ift1575 Demo 4 Sol h13Dokument11 SeitenIft1575 Demo 4 Sol h13madmajNoch keine Bewertungen
- NG Chapitre 3 Choix de FinancementDokument29 SeitenNG Chapitre 3 Choix de Financementabdelkhalek ouassiriNoch keine Bewertungen
- 39404Dokument9 Seiten39404Mourad HimriNoch keine Bewertungen
- Exam ST1 Janvier 2015Dokument3 SeitenExam ST1 Janvier 2015MohamedNoch keine Bewertungen
- Add-Examen 211229 230134Dokument7 SeitenAdd-Examen 211229 230134Hanae ChNoch keine Bewertungen
- Data Mining tp.5 Régression Linéaire MultipleDokument13 SeitenData Mining tp.5 Régression Linéaire MultipleHoussayen Ben OuhibaNoch keine Bewertungen
- Rapport de Stage de Fin D'étude AMARA Younes ZAAJ NaoufalDokument31 SeitenRapport de Stage de Fin D'étude AMARA Younes ZAAJ Naoufalنوفل زعاجNoch keine Bewertungen
- RatioDokument1 SeiteRatioAliou Malabaliou MaguiragaNoch keine Bewertungen
- Cours Recherche OpérationnelDokument60 SeitenCours Recherche OpérationnelMouad GuendouzNoch keine Bewertungen
- TD 3 CompilationDokument2 SeitenTD 3 Compilationnikan74883Noch keine Bewertungen
- TkinterDokument5 SeitenTkinterBoukhrisse HamzaNoch keine Bewertungen
- Management CasDokument4 SeitenManagement CasTALAINoch keine Bewertungen
- Ateliers 7 À9Dokument5 SeitenAteliers 7 À9Youssef OuyahyaNoch keine Bewertungen
- 05 Lineaire PDFDokument54 Seiten05 Lineaire PDFYoucef BoumedieneNoch keine Bewertungen
- Ech 1Dokument42 SeitenEch 1Amine FelouaniNoch keine Bewertungen
- Bases de Donnees Exercice IDokument2 SeitenBases de Donnees Exercice IDías VictoriaNoch keine Bewertungen
- Chapitre012-Analyse Factorielle-ACPDokument115 SeitenChapitre012-Analyse Factorielle-ACPAyoub MajajeNoch keine Bewertungen
- s3 - Loisprob - TdexcorrDokument20 Seitens3 - Loisprob - TdexcorrMikeNoch keine Bewertungen
- FR Tanagra AfcDokument10 SeitenFR Tanagra AfcEl Hadj NdoyeNoch keine Bewertungen
- Genie LogicielDokument11 SeitenGenie Logicielnourchene saidiNoch keine Bewertungen
- Manuel - Pratique Des Analyses SpssDokument81 SeitenManuel - Pratique Des Analyses SpssHamid SAMAKINoch keine Bewertungen
- Conception Des Systemes Dinformation LaDokument34 SeitenConception Des Systemes Dinformation Laznga zengaNoch keine Bewertungen
- Questions ContrôlDokument5 SeitenQuestions ContrôlHamza HamzaNoch keine Bewertungen
- Introduction GénéraleDokument13 SeitenIntroduction Généraleamel100% (7)
- Rapport FinalDokument26 SeitenRapport FinalImen FrhNoch keine Bewertungen
- Partie 3 - Maîtriser Bootstrap PDFDokument76 SeitenPartie 3 - Maîtriser Bootstrap PDFYOUNES EL AMRANINoch keine Bewertungen
- 'A C P (ACP) : L Nalyse en Omposantes RincipalesDokument18 Seiten'A C P (ACP) : L Nalyse en Omposantes RincipalesAhmed ToujaniNoch keine Bewertungen
- Acp Et Afc Quest RepDokument4 SeitenAcp Et Afc Quest Repadam smithNoch keine Bewertungen
- Ch4 Analyse Factorielle Des Correspondances AFC PDFDokument42 SeitenCh4 Analyse Factorielle Des Correspondances AFC PDFEL GUENAOUI YASSINENoch keine Bewertungen
- Corrige2 PDFDokument4 SeitenCorrige2 PDFanas100% (1)
- Cours UmlDokument21 SeitenCours UmlPFENoch keine Bewertungen
- Introduction À La Programmation Avec Python 2Dokument18 SeitenIntroduction À La Programmation Avec Python 2XenosNoch keine Bewertungen
- Séance 3-Cours Environnement Économique Des OrganisationsDokument29 SeitenSéance 3-Cours Environnement Économique Des OrganisationsSemlali Fatima zahraeNoch keine Bewertungen
- TD2 PLDokument3 SeitenTD2 PLYassminaNoch keine Bewertungen
- Chapitre 5 EstimastionDokument44 SeitenChapitre 5 EstimastionsimoNoch keine Bewertungen
- BclogoDokument22 SeitenBclogoSupantha PanditNoch keine Bewertungen
- Annexe A La Decision No357Dokument313 SeitenAnnexe A La Decision No357cheikh fatma diopNoch keine Bewertungen
- Cours Mcda AnDokument21 SeitenCours Mcda Anlokmandz100% (2)
- DS Economie InternationaleDokument1 SeiteDS Economie InternationaleNourAllah Aouini100% (2)
- Cours Kalla Salim PLDokument43 SeitenCours Kalla Salim PLBesma BessaNoch keine Bewertungen
- Lien Entre ACP Et AFDDokument2 SeitenLien Entre ACP Et AFDOthmane BrahimiNoch keine Bewertungen
- TD N3 Eg6 2020 PDFDokument2 SeitenTD N3 Eg6 2020 PDFfousseynou sanon100% (1)
- Dossier 1: Gestion Des Branchements Électriques.: Filière: Durée: 4 Heures Épreuve: Coefficient: 45Dokument13 SeitenDossier 1: Gestion Des Branchements Électriques.: Filière: Durée: 4 Heures Épreuve: Coefficient: 45zaydNoch keine Bewertungen
- Recherche Operationnelle Chap3 PDFDokument18 SeitenRecherche Operationnelle Chap3 PDFboubiz100% (1)
- ANALYSE HiérarchiqueDokument51 SeitenANALYSE HiérarchiqueHaitam KhouncheNoch keine Bewertungen
- Classification 2008 2Dokument28 SeitenClassification 2008 2mouradkadiriNoch keine Bewertungen
- ClassificationComplet HierarchiqueDokument5 SeitenClassificationComplet HierarchiquesaididhiaeddineNoch keine Bewertungen
- Scrum Guide - FRDokument19 SeitenScrum Guide - FRmpehlevanNoch keine Bewertungen
- RapportDokument125 SeitenRapportKawtar L AzaarNoch keine Bewertungen
- Memento SQL PDFDokument8 SeitenMemento SQL PDFKawtar L Azaar100% (1)
- Final Rapport PDFDokument118 SeitenFinal Rapport PDFKawtar L AzaarNoch keine Bewertungen
- Page de GardeDokument1 SeitePage de GardeKawtar L AzaarNoch keine Bewertungen
- Stage-Le Anh TuanDokument59 SeitenStage-Le Anh TuanKawtar L AzaarNoch keine Bewertungen
- Rapport de Stage-VfNarimaneDokument46 SeitenRapport de Stage-VfNarimaneKawtar L AzaarNoch keine Bewertungen
- QCM 2005 CorrDokument3 SeitenQCM 2005 CorrKawtar L AzaarNoch keine Bewertungen
- PHP HTMLDokument18 SeitenPHP HTMLKhaoula HassouneNoch keine Bewertungen
- Guide Conception ScenarioDokument6 SeitenGuide Conception ScenarioKawtar L AzaarNoch keine Bewertungen
- c3 Passagemcd MLDDokument20 Seitenc3 Passagemcd MLDKawtar L AzaarNoch keine Bewertungen
- Premiers Pas Dans Le DOMDokument7 SeitenPremiers Pas Dans Le DOMKawtar L AzaarNoch keine Bewertungen
- Memo CDokument4 SeitenMemo Cadri5000Noch keine Bewertungen
- Diff C++ JavaDokument4 SeitenDiff C++ JavaKawtar L AzaarNoch keine Bewertungen
- 2sockets PDFDokument8 Seiten2sockets PDFKawtar L AzaarNoch keine Bewertungen
- QCM VF6Dokument7 SeitenQCM VF6Bassem Ellafi100% (1)
- Exercices Corrigs Microprocesseur MmoiresDokument9 SeitenExercices Corrigs Microprocesseur MmoiresKawtar L AzaarNoch keine Bewertungen
- QCM QuizzDokument4 SeitenQCM QuizzKawtar L AzaarNoch keine Bewertungen
- Rapport CheikhnaDokument18 SeitenRapport CheikhnaKawtar L AzaarNoch keine Bewertungen
- Le Commerce Electroniques Au MarocDokument12 SeitenLe Commerce Electroniques Au MarocKawtar L Azaar100% (1)
- Marketing ViralDokument1 SeiteMarketing ViralKawtar L AzaarNoch keine Bewertungen
- Memoire M2 MEEFA Lisa RibetDokument68 SeitenMemoire M2 MEEFA Lisa RibetMyProf EpsNoch keine Bewertungen
- CV Colonel Fakraoui AnisDokument8 SeitenCV Colonel Fakraoui Anisanon_726067978Noch keine Bewertungen
- African Development Review Vol 29 PDFDokument150 SeitenAfrican Development Review Vol 29 PDFj.assokoNoch keine Bewertungen
- Examen3+Solution Méthodologie de La RédactionDokument2 SeitenExamen3+Solution Méthodologie de La Rédactiondjihane haouesNoch keine Bewertungen
- PV - Dfasp1Dokument40 SeitenPV - Dfasp1Estelle BarbatNoch keine Bewertungen
- Brochure Diu Cesam 2019-20Dokument16 SeitenBrochure Diu Cesam 2019-20maximixNoch keine Bewertungen
- Cours Enquête Socio 2021 - 22 PDFDokument22 SeitenCours Enquête Socio 2021 - 22 PDFfarida Hema100% (1)
- Syllabus de Organistion Des Entreprises Et Les Elements de ManagementDokument37 SeitenSyllabus de Organistion Des Entreprises Et Les Elements de ManagementOlga AdroNoch keine Bewertungen
- Exam Méthodologie. Kenza El OumamiDokument6 SeitenExam Méthodologie. Kenza El Oumamim.hamidiNoch keine Bewertungen
- Exosup StatsDokument8 SeitenExosup StatsRené AndreescuNoch keine Bewertungen
- Recherche 1Dokument10 SeitenRecherche 1gerard1993Noch keine Bewertungen
- Recherche Clinique Méthodologie StatistiqueDokument8 SeitenRecherche Clinique Méthodologie StatistiqueYacine Tarik AizelNoch keine Bewertungen
- td1 Equipef Rapport-4Dokument16 Seitentd1 Equipef Rapport-4api-633161295Noch keine Bewertungen
- Mino Dora DinuDokument24 SeitenMino Dora DinuCiprian Constantin100% (1)
- Corrigé Methodo Février 10Dokument13 SeitenCorrigé Methodo Février 10steelhalloweenNoch keine Bewertungen
- Le Soleil D'algerie - Algérie - Le Prof Qui Donnait Un Cours Magistral Sur Le Plagiat Pris en Flagrant Délit De... Plagiat.Dokument4 SeitenLe Soleil D'algerie - Algérie - Le Prof Qui Donnait Un Cours Magistral Sur Le Plagiat Pris en Flagrant Délit De... Plagiat.yacine26Noch keine Bewertungen
- Article 51 Guide Methodologique Evaluation Des Projets Articles 51 Document CompletDokument55 SeitenArticle 51 Guide Methodologique Evaluation Des Projets Articles 51 Document CompletCANTYNoch keine Bewertungen
- Feuilletage Theorie Pratique Geotech T1 2ed BDokument64 SeitenFeuilletage Theorie Pratique Geotech T1 2ed BbouananiNoch keine Bewertungen