Das könnte Ihnen auch gefallen
- Linux Basic CommandsDokument6 SeitenLinux Basic CommandsReddy SumanthNoch keine Bewertungen
- IJESC Journal Paper FormatDokument3 SeitenIJESC Journal Paper FormatReddy SumanthNoch keine Bewertungen
- All Linux A-ZDokument8 SeitenAll Linux A-ZReddy SumanthNoch keine Bewertungen
- Overview Remedy ToolDokument58 SeitenOverview Remedy ToolReddy SumanthNoch keine Bewertungen
- IJCTT Paper FormatDokument4 SeitenIJCTT Paper FormatReddy SumanthNoch keine Bewertungen
- PLSQL DeveloperDokument3 SeitenPLSQL DeveloperReddy SumanthNoch keine Bewertungen
- Action Pagecount Print 3 Print 2 Print 3 Email Print 2 Print 2 Print 1 Print 3Dokument1 SeiteAction Pagecount Print 3 Print 2 Print 3 Email Print 2 Print 2 Print 1 Print 3Reddy SumanthNoch keine Bewertungen
- Univer Management SystemDokument2 SeitenUniver Management SystemReddy SumanthNoch keine Bewertungen
- International Journal of Digital Application & Contemporary ResearchDokument3 SeitenInternational Journal of Digital Application & Contemporary ResearchReddy SumanthNoch keine Bewertungen
- Mobile: 91-7204998991: - Career ObjectiveDokument2 SeitenMobile: 91-7204998991: - Career ObjectiveReddy SumanthNoch keine Bewertungen
- Intelligent Network (IN) Is A Telephone Network Architecture Originated by BellDokument6 SeitenIntelligent Network (IN) Is A Telephone Network Architecture Originated by BellReddy SumanthNoch keine Bewertungen
- Different Types of Insurance: Lesson ObjectivesDokument11 SeitenDifferent Types of Insurance: Lesson ObjectivesReddy SumanthNoch keine Bewertungen
- Name: Permanent Address: Duration (From Which Month and Year) : Current CTC: Current Designation: Pan No: Phone NoDokument2 SeitenName: Permanent Address: Duration (From Which Month and Year) : Current CTC: Current Designation: Pan No: Phone NoReddy SumanthNoch keine Bewertungen
- NAME:Veeranjaneyulu Mobile: +91-9743763740 Software TesterDokument3 SeitenNAME:Veeranjaneyulu Mobile: +91-9743763740 Software TesterReddy SumanthNoch keine Bewertungen
- PL SQL DeveloperDokument3 SeitenPL SQL DeveloperReddy SumanthNoch keine Bewertungen
- Operating SystemDokument3 SeitenOperating SystemReddy SumanthNoch keine Bewertungen
- Po Box 1010, Liverpool L70 1Nl, United Kingdom Contact Number: +447937438458, +447017450549Dokument2 SeitenPo Box 1010, Liverpool L70 1Nl, United Kingdom Contact Number: +447937438458, +447017450549Reddy SumanthNoch keine Bewertungen
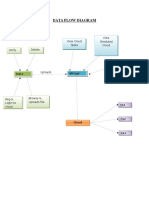
- Data Flow DiagramDokument2 SeitenData Flow DiagramReddy SumanthNoch keine Bewertungen
- Authorise - User, View - Owner - File, View - Registered - Users View - Migrated - Files Uname, Fname, Secret - Key, MAC, Migrated - FilesDokument1 SeiteAuthorise - User, View - Owner - File, View - Registered - Users View - Migrated - Files Uname, Fname, Secret - Key, MAC, Migrated - FilesReddy SumanthNoch keine Bewertungen
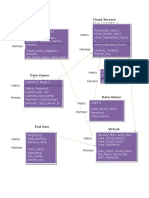
- Architecture Diagram: Social Networks UsersDokument1 SeiteArchitecture Diagram: Social Networks UsersReddy SumanthNoch keine Bewertungen
- Implementation: Data OwnerDokument2 SeitenImplementation: Data OwnerReddy SumanthNoch keine Bewertungen
- C and C++ Cheat Sheet LibrariesDokument5 SeitenC and C++ Cheat Sheet LibrariesReddy SumanthNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Distribution IDokument28 SeitenDistribution IsruthiNoch keine Bewertungen
- Shyla Jennings Ebook FinalDokument17 SeitenShyla Jennings Ebook FinalChye Yong HockNoch keine Bewertungen
- Jazz Guitar Soloing Etude F Blues 3 To 9 ArpsDokument1 SeiteJazz Guitar Soloing Etude F Blues 3 To 9 ArpsLeonardoPiresNoch keine Bewertungen
- Ap Government Imperial PresidencyDokument2 SeitenAp Government Imperial Presidencyapi-234443616Noch keine Bewertungen
- Hazardous Location Division Listed LED Light: Model 191XLDokument2 SeitenHazardous Location Division Listed LED Light: Model 191XLBernardo Damas EspinozaNoch keine Bewertungen
- Business Advantage Pers Study Book Intermediate PDFDokument98 SeitenBusiness Advantage Pers Study Book Intermediate PDFCool Nigga100% (1)
- Creative Thesis ExamplesDokument8 SeitenCreative Thesis Examplescatherinebitkerrochester100% (2)
- SAGEM FAST 3202 (Livebox) ENGLISHDokument140 SeitenSAGEM FAST 3202 (Livebox) ENGLISHspam47spam47Noch keine Bewertungen
- Case Digest 2 S.C. MEGAWORLD CONSTRUCTIONDokument3 SeitenCase Digest 2 S.C. MEGAWORLD CONSTRUCTIONRomualdo CabanesasNoch keine Bewertungen
- Ef3 Englisch 04 14 08052014Dokument20 SeitenEf3 Englisch 04 14 08052014PiPradoNoch keine Bewertungen
- Neon Wilderness MenuDokument2 SeitenNeon Wilderness MenuAlisa HNoch keine Bewertungen
- This I BeleiveDokument3 SeitenThis I Beleiveapi-708902979Noch keine Bewertungen
- Catalogue Mega EnglishDokument40 SeitenCatalogue Mega EnglishInotech Outillage Nouvelle CalédonieNoch keine Bewertungen
- R Don Steele - How To Date Young Women For Men Over 35Dokument232 SeitenR Don Steele - How To Date Young Women For Men Over 35gonzalo_barandiarán83% (6)
- Buchanan, KeohaneDokument34 SeitenBuchanan, KeohaneFlorina BortoșNoch keine Bewertungen
- Business Mathematics 11 Q2 Week3 MELC20 MELC21 MOD Baloaloa, JeffersonDokument25 SeitenBusiness Mathematics 11 Q2 Week3 MELC20 MELC21 MOD Baloaloa, JeffersonJefferson BaloaloaNoch keine Bewertungen
- Priya - Rachna Kumari PrasadDokument17 SeitenPriya - Rachna Kumari PrasadSumant priyadarshiNoch keine Bewertungen
- Comparative Genomics 2 - PART 1Dokument31 SeitenComparative Genomics 2 - PART 1NnleinomNoch keine Bewertungen
- China Email ListDokument3 SeitenChina Email ListRosie Brown40% (5)
- The Real World An Introduction To Sociology Test Bank SampleDokument28 SeitenThe Real World An Introduction To Sociology Test Bank SampleMohamed M YusufNoch keine Bewertungen
- Talking SwedishDokument32 SeitenTalking Swedishdiana jimenezNoch keine Bewertungen
- Bajaj Holdings & Investment Ltd. - Research Center: Balance SheetDokument6 SeitenBajaj Holdings & Investment Ltd. - Research Center: Balance Sheetsarathkumarreddy855081Noch keine Bewertungen
- Theological Differences Between Christianity and IslamDokument18 SeitenTheological Differences Between Christianity and IslamMencari KhadijahNoch keine Bewertungen
- Gurdan Saini: From Wikipedia, The Free EncyclopediaDokument6 SeitenGurdan Saini: From Wikipedia, The Free EncyclopediaRanjeet SinghNoch keine Bewertungen
- Qualitative Analysis of Selected Medicinal Plants, Tamilnadu, IndiaDokument3 SeitenQualitative Analysis of Selected Medicinal Plants, Tamilnadu, IndiaDiana RaieNoch keine Bewertungen
- Quad Destroyer - 10 Sets of Squats Workout - Muscle & StrengthDokument6 SeitenQuad Destroyer - 10 Sets of Squats Workout - Muscle & StrengthMouhNoch keine Bewertungen
- Floline Size eDokument4 SeitenFloline Size eNikesh ShahNoch keine Bewertungen
- Irm PDFDokument27 SeitenIrm PDFerraticNoch keine Bewertungen
- Project Proposal Environmental Protection Program-DeNRDokument57 SeitenProject Proposal Environmental Protection Program-DeNRLGU PadadaNoch keine Bewertungen
- (EN) Google Developer Policy - September 1, 2021Dokument56 Seiten(EN) Google Developer Policy - September 1, 2021JimmyNoch keine Bewertungen